- The paper introduces novel prompting methods, including Miniature and Mull as well as Explain {content} Compare, to evaluate SQL equivalence.
- The study demonstrates that models like GPT-4 effectively differentiate between semantic and relaxed SQL equivalence, outperforming traditional heuristics.
- The paper highlights the potential for LLMs to improve SQL query optimization and serve as benchmarks for text-to-SQL tasks in data engineering.
"LLM-SQL-Solver: Can LLMs Determine SQL Equivalence?" (2312.10321)
This paper explores the application of LLMs, particularly GPT models, in determining SQL query equivalence. LLMs have demonstrated strong reasoning abilities, prompting researchers to investigate their potential as tools for evaluating SQL query equivalence, which has long been a complex and undecidable problem in data management.
Introduction
SQL remains the standard language for querying databases. Despite its versatility and efficiency, SQL's nature as a non-procedural language means that different syntactically diverse queries can produce semantically identical results. For decades, the challenge of determining SQL query equivalence has posed considerable difficulties, with previous approaches incorporating restricted SQL operations and limited prototypes such as Cosette (2312.10321). However, recent advances have shown that LLMs are capable of logical reasoning, hence the premise that they could extend those reasoning capabilities to solving SQL equivalence challenges.
Notions of SQL Equivalence
Two critical notions of SQL equivalence are defined: Semantic Equivalence and Relaxed Equivalence. Semantic equivalence ensures SQL queries always produce identical outputs for all possible databases, while relaxed equivalence allows for trivial modifications to queries that do not alter their logical structure but achieve semantic equivalence. For instance, the study explores a known COUNT bug in SQL queries, where correct logical reasoning would categorize similar queries as semantically different, but relaxed equivalent, showcasing human-like understanding of underlying logic.
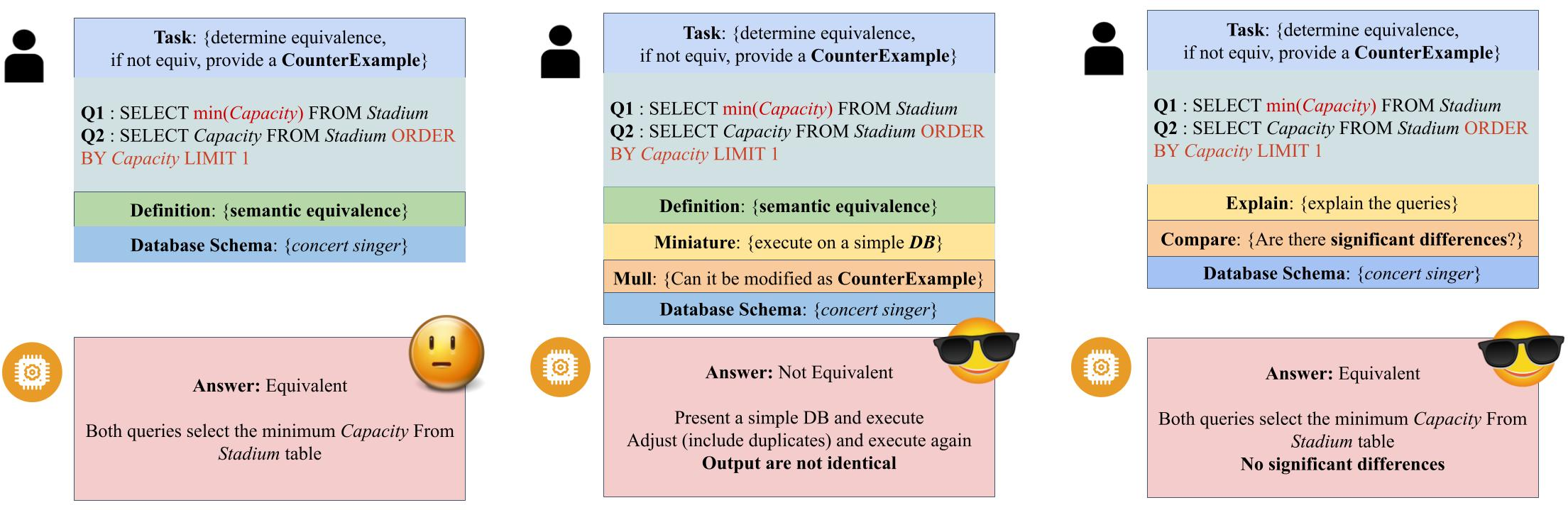
Figure 1: Demonstration of Counter Example, Miniature {content} MULL, and Explain \% Compare prompts. The used SQL queries are not semantically equivalent but are relaxed equivalent.
Proposed Methodology
The research introduces two sophisticated prompting techniques: Miniature and Mull for evaluating semantic equivalence and Explain {content} Compare for assessing relaxed equivalence. The Miniature and Mull technique asks LLMs to execute the queries over a simplified database and assess if a counter-example can be generated by modifying the database, enhancing reasoning capability particularly for subtle SQL differences. Explain {content} Compare designed for relaxed equivalence requires multi-step reasoning, encouraging LLMs to consider if the queries share significant logical similarity.
Experimental Evaluation
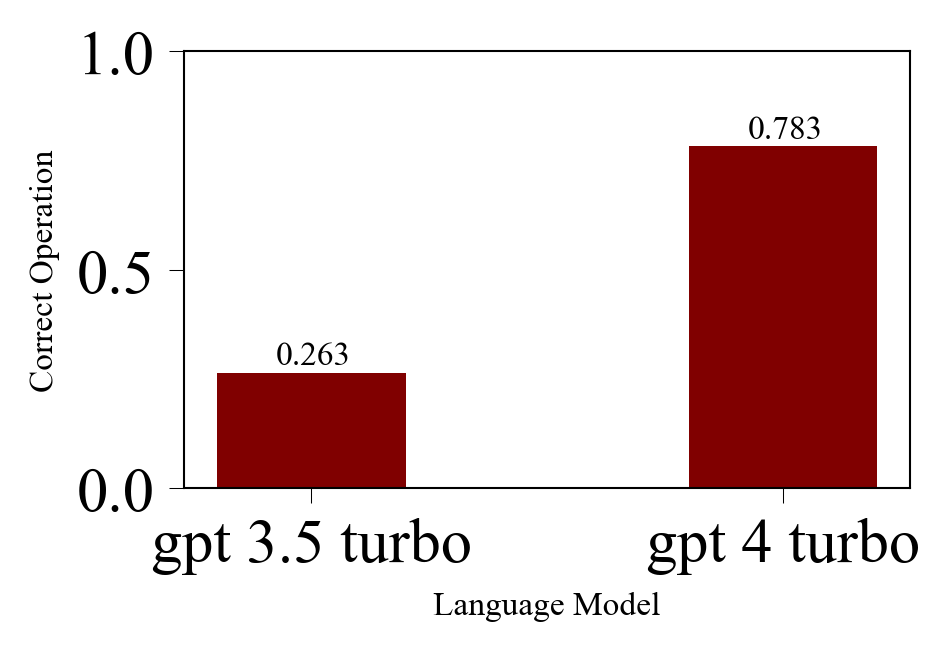
Figure 2: The correct operation rates for LLMs. Correct operations imply the LLM correctly executed and reasoned about the SQL queries on its own provided simple database.
The study evaluated the performance of GPT-3.5 turbo and GPT-4 turbo models in determining SQL equivalence against established datasets including Non-equivalent Queries (2312.10321) and Spider (Yu et al., 2018). The experiments highlighted the discrepancies and potential strengths of LLM models relative to past heuristics such as execution accuracy. The study emphasizes that LLMs, especially when using the proposed prompts, better capture both semantic and relaxed equivalence from a human perception standpoint compared to execution match metrics. The results suggest that models like GPT-4 are effective at reasoning about SQL equivalences and can aid in refining SQL optimization logic.
Implications and Future Developments
The implications of deploying LLMs as SQL solvers are profound for data management systems. LLMs can assist in discovering semantic equivalence in SQL queries, providing a powerful tool for data engineers. Furthermore, employing LLMs as benchmark evaluators for text-to-SQL tasks holds promise due to their ability to discern logical similarities that resonate more appropriately with user expectations. Given the advancements in LLMs, these models offer promising avenues for further research to develop effective SQL equivalency solutions and related applications.
Conclusion
The study concludes that current LLMs demonstrate the potential to assist in judging SQL equivalence under both precise semantic constraints and relaxed human-centric notions. LLMs, with appropriate prompting, prove to be valuable in special contexts where traditional syntax-level evaluation metrics like execution accuracy may fall short. Despite challenges such as possible LLM reasoning limitations and hallucinations, these models have shown significant promise in improving data engineering processes and redefining evaluation metrics in NLP tasks. Future research will likely continue to explore the expanding utility of LLMs in logical equivalence and reasoning tasks.