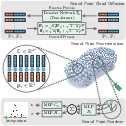
Neural Point Cloud Diffusion for Disentangled 3D Shape and Appearance Generation
Abstract: Controllable generation of 3D assets is important for many practical applications like content creation in movies, games and engineering, as well as in AR/VR. Recently, diffusion models have shown remarkable results in generation quality of 3D objects. However, none of the existing models enable disentangled generation to control the shape and appearance separately. For the first time, we present a suitable representation for 3D diffusion models to enable such disentanglement by introducing a hybrid point cloud and neural radiance field approach. We model a diffusion process over point positions jointly with a high-dimensional feature space for a local density and radiance decoder. While the point positions represent the coarse shape of the object, the point features allow modeling the geometry and appearance details. This disentanglement enables us to sample both independently and therefore to control both separately. Our approach sets a new state of the art in generation compared to previous disentanglement-capable methods by reduced FID scores of 30-90% and is on-par with other non disentanglement-capable state-of-the art methods.
- Learning representations and generative models for 3D point clouds. In ICML, 2018.
- Renderdiffusion: Image diffusion for 3d reconstruction, inpainting and generation. In CVPR, 2023.
- Demystifying mmd gans. In ICLR, 2018.
- Learning gradient fields for shape generation. In ECCV, 2020.
- Deep local shapes: Learning local SDF priors for detailed 3D reconstruction. In ECCV, 2020.
- Efficient geometry-aware 3D generative adversarial networks. In CVPR, 2022.
- ShapeNet: An information-rich 3d model repository. Technical Report arXiv:1512.03012, Stanford University — Princeton University — Toyota Technological Institute at Chicago, 2015.
- Single-stage diffusion nerf: A unified approach to 3d generation and reconstruction, 2023.
- Diffusion models beat gans on image synthesis. In NeurIPS, 2021.
- From data to functa: Your data point is a function and you can treat it like one. In ICML, 2022.
- HyperDiffusion: Generating implicit neural fields with weight-space diffusion, 2023.
- Gans trained by a two time-scale update rule converge to a local nash equilibrium. In NeurIPS, 2017.
- Denoising diffusion probabilistic models. In NeurIPS, 2020.
- Codenerf: Disentangled neural radiance fields for object categories. In ICCV, 2021.
- Shap-E: Generating conditional 3d implicit functions. arXiv:2305.02463, 2023.
- Elucidating the design space of diffusion-based generative models. In NeurIPS, 2022.
- Softflow: Probabilistic framework for normalizing flow on manifolds. In NeurIPS, 2020.
- Auto-Encoding Variational Bayes. In ICLR, 2014.
- Discrete point flow networks for efficient point cloud generation. In ECCV, 2020.
- Magic3d: High-resolution text-to-3d content creation. In CVPR, 2023.
- Zero-1-to-3: Zero-shot one image to 3d object. arXiv preprint arXiv:2303.11328, 2023.
- Diffusion probabilistic models for 3d point cloud generation. In CVPR, 2021.
- Realfusion: 360deg reconstruction of any object from a single image. In CVPR, 2023.
- Nerf: Representing scenes as neural radiance fields for view synthesis. In ECCV, 2020.
- Diffrf: Rendering-guided 3d radiance field diffusion. In CVPR, 2023.
- Point-E: A system for generating 3d point clouds from complex prompts. arXiv:2212.08751, 2022.
- Giraffe: Representing scenes as compositional generative neural feature fields. In CVPR, 2021.
- Differentiable volumetric rendering: Learning implicit 3d representations without 3d supervision. In CVPR, 2020.
- Photoshape: Photorealistic materials for large-scale shape collections. ACM TOG, 2018.
- Dreamfusion: Text-to-3d using 2d diffusion. In ICLR, 2023.
- Zero-shot text-to-image generation. In ICML, 2021.
- High-resolution image synthesis with latent diffusion models. In CVPR, 2022.
- Photorealistic text-to-image diffusion models with deep language understanding. In NeurIPS, 2022.
- Graf: Generative radiance fields for 3d-aware image synthesis. In NeurIPS, 2020.
- 3d neural field generation using triplane diffusion. In CVPR, 2023.
- Scene representation networks: Continuous 3d-structure-aware neural scene representations. In NeurIPS, 2019.
- Deep unsupervised learning using nonequilibrium thermodynamics. In ICML, 2015.
- Generative modeling by estimating gradients of the data distribution. In NeurIPS, 2019.
- Disentangled3d: Learning a 3d generative model with disentangled geometry and appearance from monocular images. In CVPR, 2022.
- Attention is all you need. In NeurIPS, 2017.
- Simnp: Learning self-similarity priors between neural points. In ICCV, 2023.
- Point-NeRF: Point-based neural radiance fields. In CVPR, 2022.
- Pointflow: 3d point cloud generation with continuous normalizing flows. In ICCV, 2019.
- Mvsnet: Depth inference for unstructured multi-view stereo. In ECCV, 2018.
- LION: Latent point diffusion models for 3d shape generation. In NeurIPS, 2022.
- Adding conditional control to text-to-image diffusion models. arXiv preprint arXiv:2302.05543, 2023.
- 3d shape generation and completion through point-voxel diffusion. In ICCV, 2021.
- Sparsefusion: Distilling view-conditioned diffusion for 3d reconstruction. In CVPR, 2023.
- Visual object networks: Image generation with disentangled 3d representations. In NeurIPS, 2018.































Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.