The LLM Surgeon
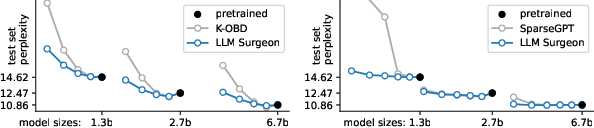
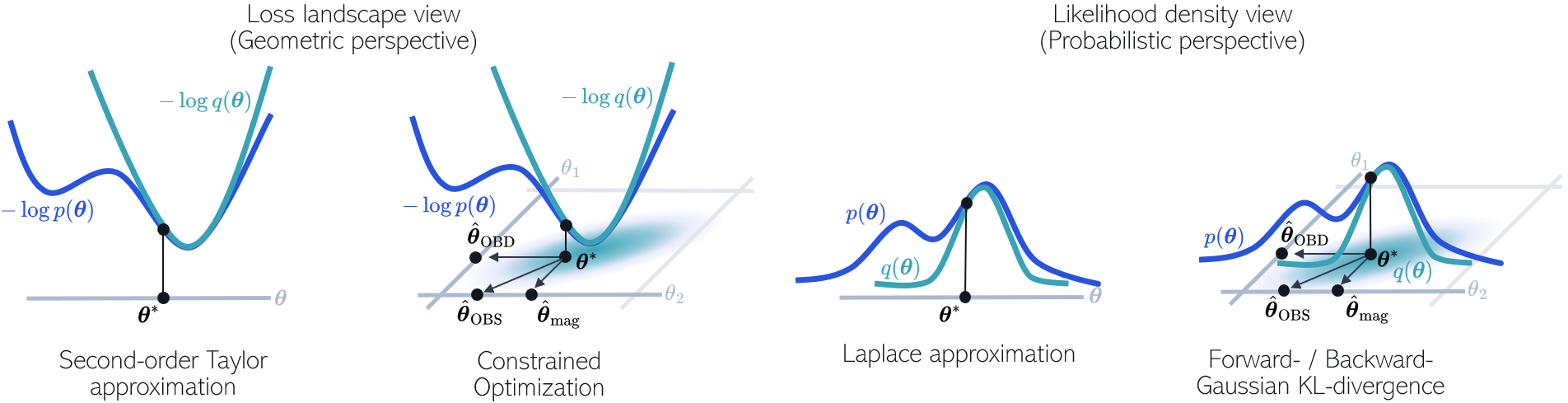
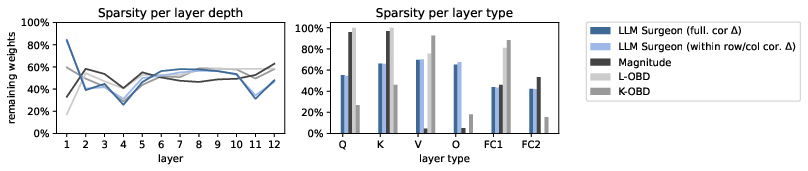
Abstract: State-of-the-art LLMs are becoming increasingly large in an effort to achieve the highest performance on large corpora of available textual data. However, the sheer size of the Transformer architectures makes it difficult to deploy models within computational, environmental or device-specific constraints. We explore data-driven compression of existing pretrained models as an alternative to training smaller models from scratch. To do so, we scale Kronecker-factored curvature approximations of the target loss landscape to LLMs. In doing so, we can compute both the dynamic allocation of structures that can be removed as well as updates of remaining weights that account for the removal. We provide a general framework for unstructured, semi-structured and structured pruning and improve upon weight updates to capture more correlations between weights, while remaining computationally efficient. Experimentally, our method can prune rows and columns from a range of OPT models and Llamav2-7B by 20%-30%, with a negligible loss in performance, and achieve state-of-the-art results in unstructured and semi-structured pruning of LLMs.
- Pattern recognition and machine learning, volume 4. Springer, 2006.
- Practical gauss-newton optimisation for deep learning. In International Conference on Machine Learning, pp. 557–565. PMLR, 2017.
- Optimal brain compression: A framework for accurate post-training quantization and pruning. Advances in Neural Information Processing Systems, 35:4475–4488, 2022.
- Sparsegpt: Massive language models can be accurately pruned in one-shot. 2023.
- Matrix computations. JHU press, 2013.
- Second order derivatives for network pruning: Optimal brain surgeon. Advances in neural information processing systems, 5, 1992.
- Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
- Accurate post training quantization with small calibration sets. In International Conference on Machine Learning, pp. 4466–4475. PMLR, 2021.
- Invariance learning in deep neural networks with differentiable laplace approximations. Advances in Neural Information Processing Systems, 35:12449–12463, 2022.
- Efficient approximations of the fisher matrix in neural networks using kronecker product singular value decomposition. arXiv preprint arXiv:2201.10285, 2022.
- Limitations of the empirical fisher approximation for natural gradient descent. Advances in neural information processing systems, 32, 2019.
- The optimal bert surgeon: Scalable and accurate second-order pruning for large language models. arXiv preprint arXiv:2203.07259, 2022.
- Optimal brain damage. Advances in neural information processing systems, 2, 1989.
- Learning sparse neural networks through l_0𝑙_0l\_0italic_l _ 0 regularization. arXiv preprint arXiv:1712.01312, 2017.
- David JC MacKay. Information theory, inference and learning algorithms. Cambridge university press, 2003.
- Optimizing neural networks with kronecker-factored approximate curvature. In International conference on machine learning, pp. 2408–2417. PMLR, 2015.
- Pointer sentinel mixture models. arXiv preprint arXiv:1609.07843, 2016.
- A simple and effective pruning approach for large language models. arXiv preprint arXiv:2306.11695, 2023.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Eigendamage: Structured pruning in the kronecker-factored eigenbasis. In International conference on machine learning, pp. 6566–6575. PMLR, 2019.
- Wikipedia. Wikipedia. PediaPress, 2004.
- Huggingface’s transformers: State-of-the-art natural language processing. arXiv preprint arXiv:1910.03771, 2019.
- Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022.
- Learning n: m fine-grained structured sparse neural networks from scratch. arXiv preprint arXiv:2102.04010, 2021.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.