- The paper presents an efficient single-layer transformer approach for BEV view transformation that compresses image features to width-focused embeddings.
- It introduces Reference Positional Encoding (RefPE) to accurately encode rotation and distance, enhancing spatial integrity in 3D detections.
- Evaluations on the nuScenes dataset demonstrate improved mAP and latency performance, underscoring its potential in autonomous driving.
Introduction
The paper "WidthFormer: Toward Efficient Transformer-based BEV View Transformation" (2401.03836) introduces an innovative approach for Bird's-Eye-View (BEV) transformation in the context of real-time 3D detection for autonomous vehicles. Traditional methods for BEV transformation typically fall into attention-based approaches or Lift-Splat frameworks, often burdened by computational intensity and deployment complexity. WidthFormer aims to overcome these limitations through a single-layer transformer architecture together with a novel positional encoding strategy.
Key Contributions
The WidthFormer method is centered around reducing computational overhead by compressing image features into width-focused embeddings rather than relying on traditional height and width feature maps, reducing the dimensional data it processes. By applying a single-layer transformer decoder model, WidthFormer capitalizes on Reference Positional Encoding (RefPE) to maintain high performance while reducing processing load and the necessity for non-standard operations.
Reference Positional Encoding (RefPE)
RefPE is a critical advancement in this paper, presenting a robust means of preserving 3D geometrical integrity in image embeddings by encoding rotation and distance information distinct to each BEV query. By aggregating directional and spatial data into a refined encoding step, significant improvements in spatial accuracy are reported.
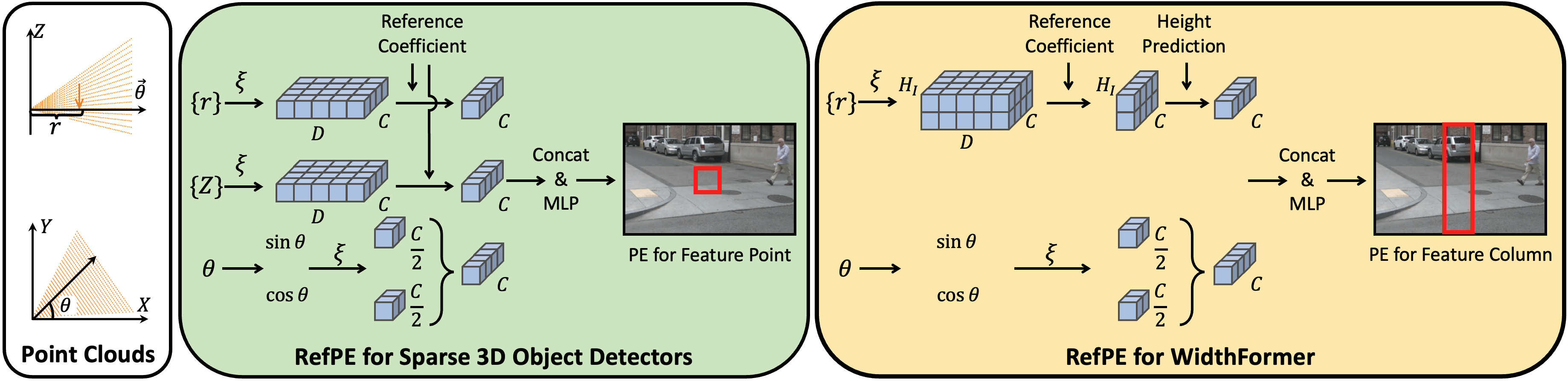
Figure 1: Reference Positional Encoding (RefPE) showcases the inclusion of rotation and distance components, enhancing sparse 3D detectors.
Robustness and Application to Autonomous Driving
The authors test WidthFormer and its variant BEVFormer under various conditions involving degrees of camera perturbation using the 6DoF framework. The methods show a strong balance of real-time efficacy and robustness against disturbances typical in dynamic driving scenarios. Evaluation using the nuScenes dataset demonstrates that WidthFormer not only achieves a significant performance edge over existing methods but does so with improved latency characteristics.
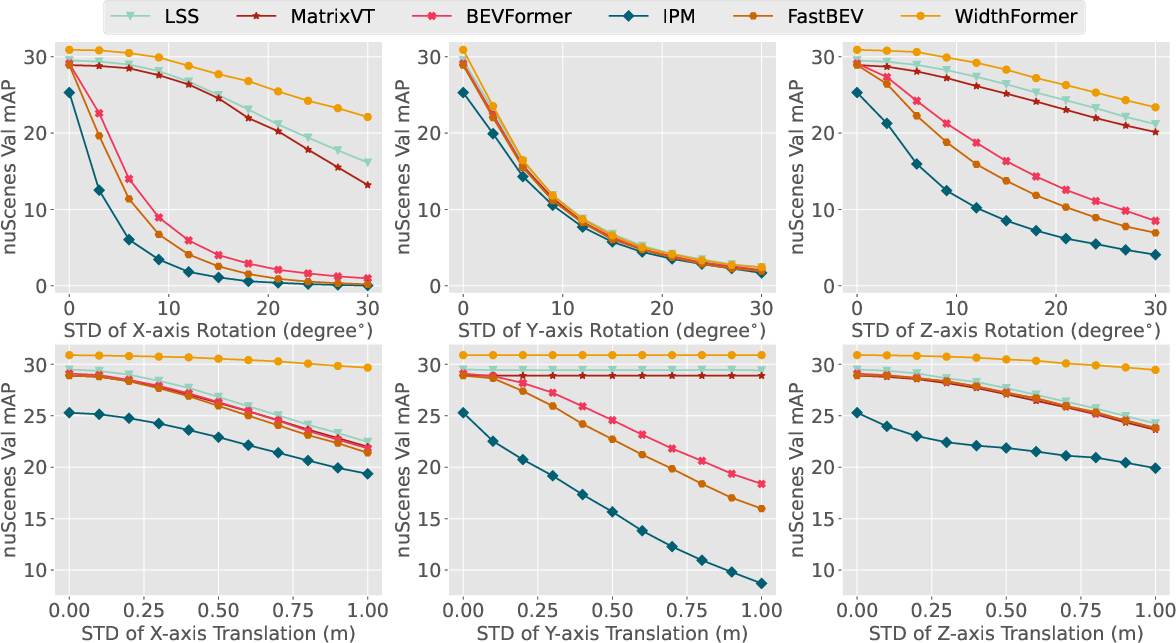
Figure 2: Robustness comparison of different VT methods under 6DoF camera perturbations.
Methodology
WidthFormer introduces an architecture where the transformation from image to BEV space is facilitated via a single transformer decoder layer. This decoder attends to compressed features, specifically 'width' focused ones derived from pooling the height dimension of image features, to minimize the information loss and computation requirements typical in BEV transformations.
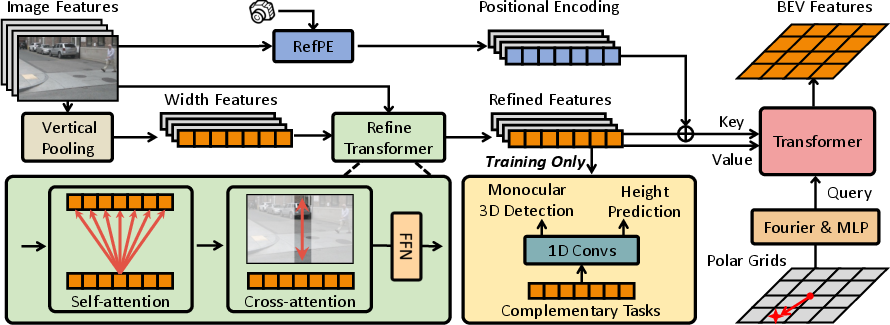
Figure 3: WidthFormer takes multi-view images and refines them via a transformer designed to suit compressed feature dimensions.
Feature Compressing and Compensation Techniques
WidthFormer employs image feature compression to width elements by pooling over height. To mitigate the information compromise usually associated with such compression, the Refine Transformer module is applied, refining and retrieving additional contextual data from the image space effectively.
Experimental Benchmark
Experiments on the nuScenes dataset underscore the benefits of WidthFormer where performance gains were reported both in terms of mean Average Precision (mAP) and reduced latency under computational edge limitations. The method achieves notable mAP improvements while maintaining strong downstream effects on NDS, a key metric for detection quality.
Conclusion
WidthFormer provides a significant step forward in real-time BEV view transformation by showcasing how efficient transformer structures and positional encoding can combine to enhance the applicability of autonomous driving frameworks. Future research could build upon WidthFormer by expanding on its current efficiency gains, potentially applying these concepts to broader perceptual tasks.
Overall, WidthFormer makes a substantive contribution to the field of real-time 3D object detection by delivering a streamlined and effective methodology to process multi-view images into coherent BEV representations with lower latency and enhanced robustness.