Model Editing at Scale leads to Gradual and Catastrophic Forgetting
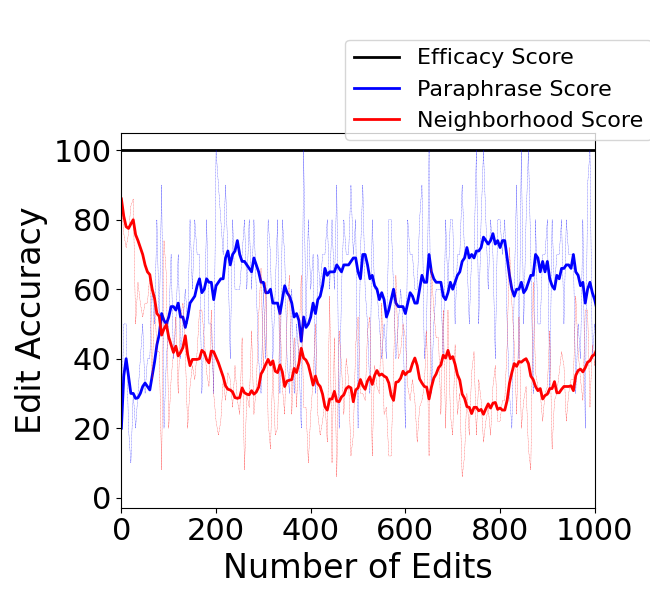
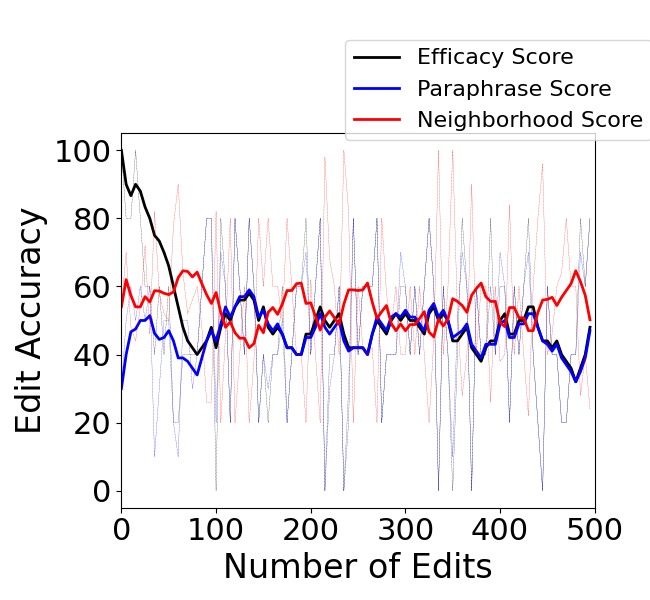
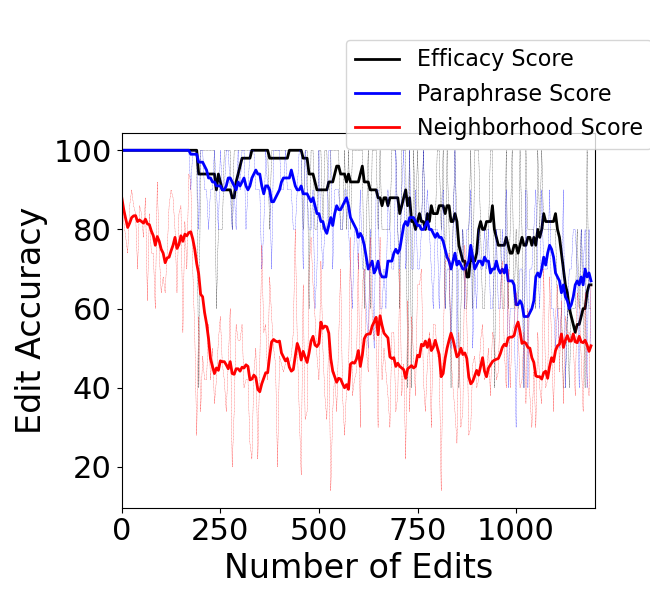
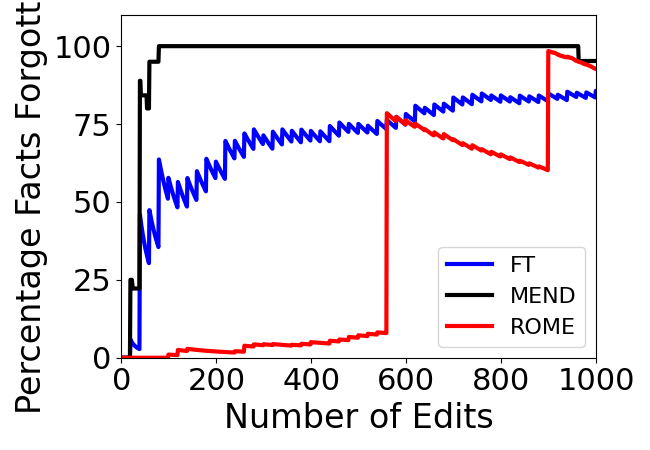
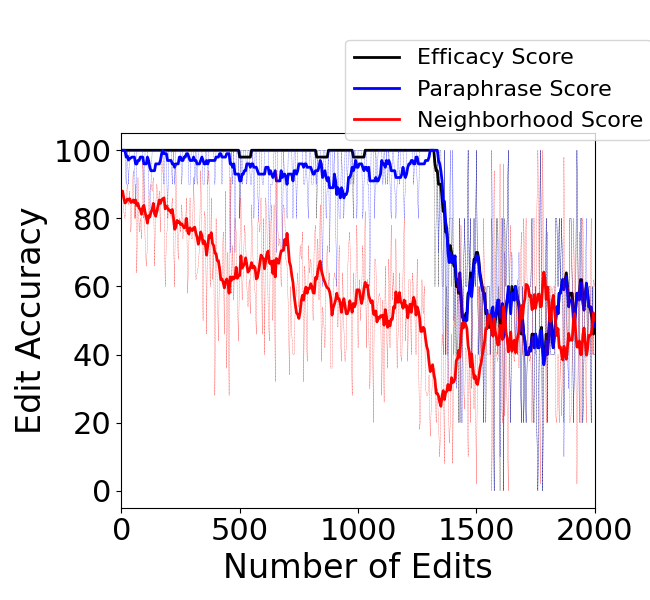
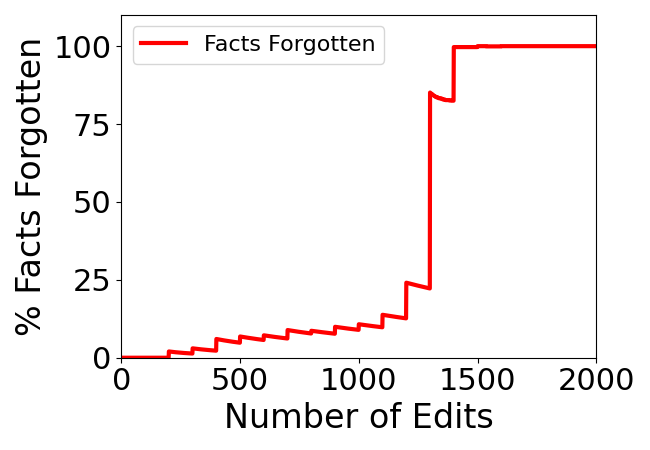
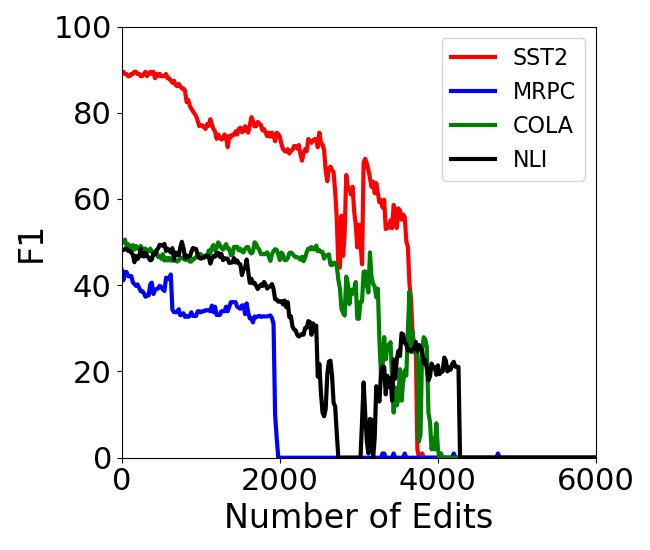
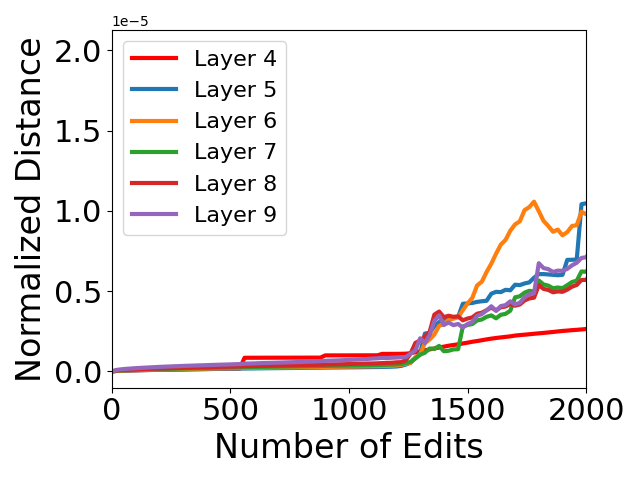
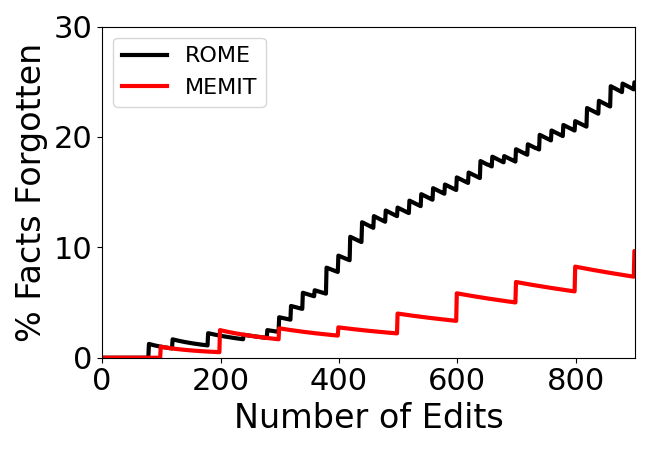
Abstract: Editing knowledge in LLMs is an attractive capability to have which allows us to correct incorrectly learnt facts during pre-training, as well as update the model with an ever-growing list of new facts. While existing model editing techniques have shown promise, they are usually evaluated using metrics for reliability, specificity and generalization over one or few edits. We argue that for model editing to have practical utility, we must be able to make multiple edits to the same model. With this in mind, we evaluate the current model editing methods at scale, focusing on two state of the art methods: ROME and MEMIT. We find that as the model is edited sequentially with multiple facts, it continually forgets previously edited facts and the ability to perform downstream tasks. This forgetting happens in two phases -- an initial gradual but progressive forgetting phase followed by abrupt or catastrophic forgetting phase. Both gradual and catastrophic forgetting limit the usefulness of model editing methods at scale -- the former making model editing less effective as multiple edits are made to the model while the latter caps the scalability of such model editing methods. Our analysis also highlights other key limitations of ROME and MEMIT at scale. With our work, we push for the development and evaluation of model editing methods keeping scalability in mind.
- Quantifying memorization across neural language models. arXiv preprint arXiv:2202.07646.
- A brief review of hypernetworks in deep learning. arXiv preprint arXiv:2306.06955.
- Evaluating the ripple effects of knowledge editing in language models. arXiv preprint arXiv:2307.12976.
- Editing factual knowledge in language models. arXiv preprint arXiv:2104.08164.
- Bill Dolan and Chris Brockett. 2005. Automatically constructing a corpus of sentential paraphrases. In Third International Workshop on Paraphrasing (IWP2005).
- A survey for in-context learning. arXiv preprint arXiv:2301.00234.
- Transformer feed-forward layers are key-value memories. arXiv preprint arXiv:2012.14913.
- An empirical investigation of catastrophic forgetting in gradient-based neural networks. arXiv preprint arXiv:1312.6211.
- Overcoming catastrophic forgetting in neural networks. Proceedings of the national academy of sciences, 114(13):3521–3526.
- Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474.
- Unveiling the pitfalls of knowledge editing for large language models. arXiv preprint arXiv:2310.02129.
- Locating and editing factual associations in gpt. Advances in Neural Information Processing Systems, 35:17359–17372.
- Mass-editing memory in a transformer. arXiv preprint arXiv:2210.07229.
- Fast model editing at scale. arXiv preprint arXiv:2110.11309.
- Memory-based model editing at scale. In International Conference on Machine Learning, pages 15817–15831. PMLR.
- Language models are unsupervised multitask learners. OpenAI blog, 1(8):9.
- Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 conference on empirical methods in natural language processing, pages 1631–1642.
- Attention is all you need. Advances in neural information processing systems, 30.
- Glue: A multi-task benchmark and analysis platform for natural language understanding. arXiv preprint arXiv:1804.07461.
- Editing large language models: Problems, methods, and opportunities. arXiv preprint arXiv:2305.13172.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.