- The paper presents CBVS, a large-scale benchmark for Chinese image-text pairing that tackles unique challenges in short video cover retrieval.
- It introduces UniCLIP, which uses presence-guided and semantic-guided encoders to optimize contrastive learning without relying on OCR during inference.
- Experimental results demonstrate significant improvements in recall and ranking metrics, underscoring the effectiveness of tailored domain-specific training.
CBVS: A Large-Scale Chinese Image-Text Benchmark for Real-World Short Video Search Scenarios
The paper "CBVS: A Large-Scale Chinese Image-Text Benchmark for Real-World Short Video Search Scenarios" (arXiv ID: (2401.10475)) addresses the challenge of developing effective Vision-LLMs (VLMs) for short video search scenarios, specifically focusing on the morphological differences between traditional open domain images and user-originated short video covers. The authors introduce CBVS, the largest publicly available Chinese dataset compiled for video cover-image-text pairing. The dataset is divided into unsupervised versions (CBVS-5M and CBVS-10M) and a curated benchmark version (CBVS-20K).
Introduction
Short video covers present a unique challenge in the domain of image-text retrieval due to their user-originated nature, including post-processing alterations such as cropping and splicing, contrasting sharply with open domain images (Figure 1). The semantic richness added by manually crafted cover texts further complicates this domain. The authors leveraged this distinction to create the CBVS dataset, designed to fill current gaps, offering extensive data for developing and evaluating models in Chinese short video search scenarios.

Figure 1: Morphological differences between open domain images and short video cover images.
UniCLIP is proposed to effectively train VLMs without explicit reliance on OCR systems during inference. The significant advantage of UniCLIP lies in its ability to utilize cover texts effectively during training, guiding semantic understanding without requiring these texts during inference, hence addressing the challenge of modality missing.
CBVS Dataset
Comparison and Collection: CBVS distinguishes itself from existing datasets, prioritizing the uniqueness and relevance of video cover images and texts. It comprises manually fine-labeled data (CBVS-20K) and larger unsupervised datasets (CBVS-5M and CBVS-10M). The dataset collection relied on collaborating with platforms like BiliBili and Tencent Video, ensuring diverse and high-quality data.

Figure 2: Top: Presentation of CBVS-20K data. Bottom: Presentation of CBVS-5M/10M data.
Annotation: The annotation process consisted of meticulous cross-validation by domain experts to ensure data quality, focusing on the relevance of user queries to video covers and incorporating semantic information from OCR texts. This rigorous process yielded over 20,000 unique annotated pairs.
Methodology
Image-Text Contrastive Learning: UniCLIP utilizes ViT and RoBERTa for contrastive learning, bridging visual and textual modalities efficiently through an enhanced InfoNCE loss. This approach harnesses large-scale unsupervised data for robust model alignment.
Presence and Semantic-Guided Encoding: Architectural innovations include separate encoders - a presence-guided encoder for identifying the presence of cover texts and a semantic-guided encoder to assess textual consistency (Figure 3). These modules come into play during training but abstain from inference, ensuring UniCLIP remains OCR-free and efficient during real-world deployment.
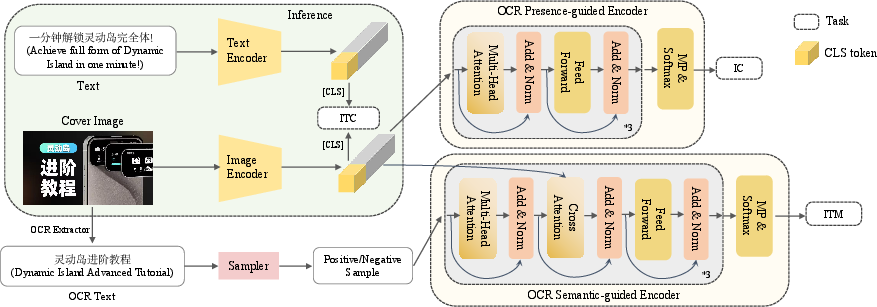
Figure 3: Model structure of UniCLIP. When the model performs inference, only the green area works.
Experiments
Evaluation: Extensive benchmarking on CBVS-20K demonstrated UniCLIP's superior performance compared to existing models, especially in recall metrics and rank metrics such as PNR and NDCG. Fine-tuning traditional models on CBVS data highlighted the importance of adapting to unique domain-specific features for improved retrieval accuracy.
Ablation Studies: Trials confirm the efficacy of presence and semantic-guided learning strategies. Their removal indicated noticeable performance drops across most metrics, proving their significance in the UniCLIP framework.
Assessment of Cover Text Utilization: UniCLIP outperformed OCR-dependent strategies in environments with missing modalities, displaying a significant advantage in handling varied textual presence scenarios compared to ALBEF-CLIP and QA-CLIP models.
Conclusion
CBVS provides a comprehensive benchmark to advance VLMs for short video search, significantly impacting domains with modality variances. UniCLIP emerges as a robust methodology, promising seamless integration into real-world applications without excessive computational overhead or reliance on cover text availability during inference. Future directions include expanding CBVS for related tasks such as title generation and exploring ways to bridge general and video-specific domains effectively.