- The paper introduces LLaRA2, which synergistically combines conventional recommendation methods and LLMs to mitigate data sparsity and long-tail issues.
- It employs mutual augmentation through data and prompt enhancements, leveraging semantic insights from LLMs alongside behavioral data.
- Adaptive aggregation optimally blends predictions based on user interaction patterns, achieving superior performance over traditional models on diverse datasets.
Integrating LLMs into Recommendation via Mutual Augmentation and Adaptive Aggregation
Introduction
Recommender systems are pivotal in addressing the challenge of information overload, encompassing tasks such as rating prediction and top-k recommendation. Traditional recommendation methods exploit collaborative filtering and sequential modeling but struggle with data sparsity and the long-tail problem. Meanwhile, LLMs are adept at processing textual semantics but are limited in mining collaborative or sequential information. The "Integrating LLMs into Recommendation via Mutual Augmentation and Adaptive Aggregation" paper proposes LLaRA2, a framework that synergistically combines the strengths of conventional recommendation systems and LLMs. By integrating data augmentation and prompt enhancement, followed by adaptive aggregation, LLaRA2 improves the recommendation quality through leveraging LLMs' semantic understanding and traditional models' user behavior insights. Empirical validations on diverse datasets substantiate LLaRA2’s efficacy, offering substantial enhancements over baseline methods.
Framework Architecture
The architecture of LLaRA2 is designed to integrate the strengths of traditional recommendation models and LLMs through mutual augmentation and adaptive aggregation.
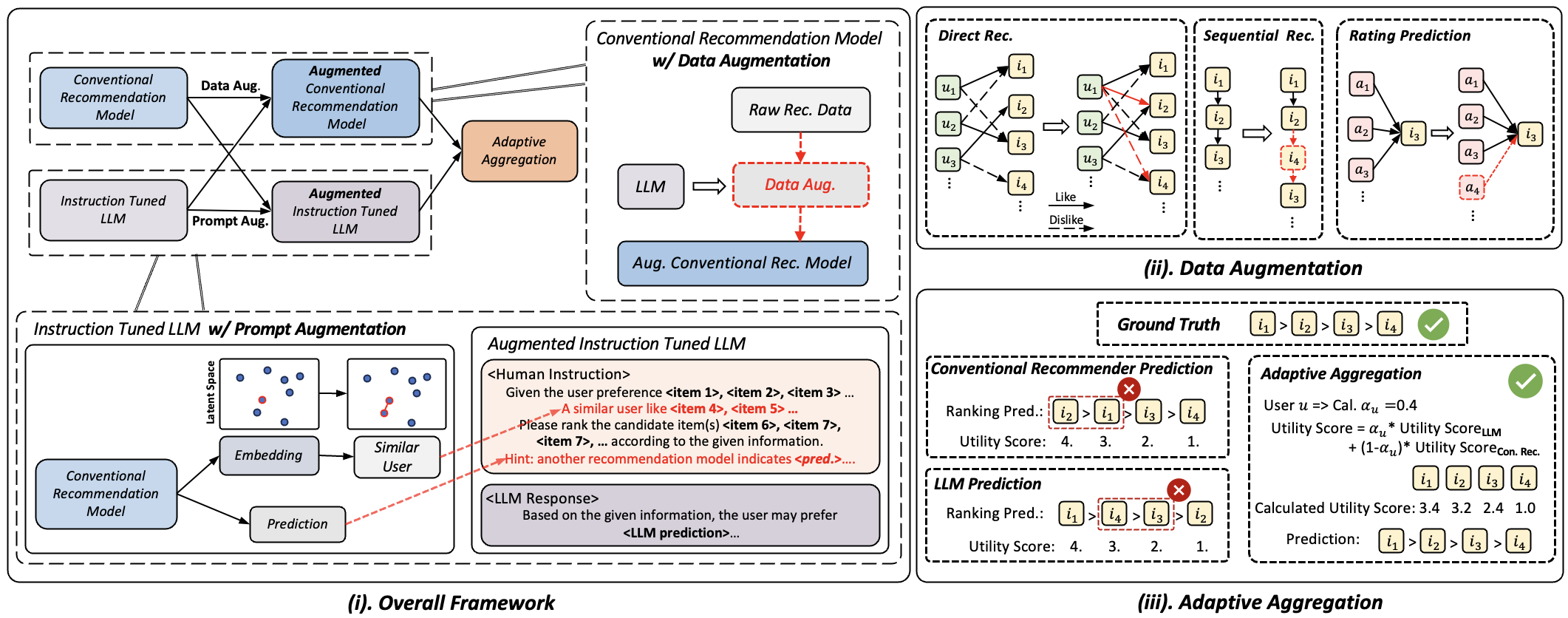
Figure 1: (i) The overall framework architecture of the proposed LLaRA2 consists of two main components: mutual augmentation and adaptive aggregation. The mutual augmentation includes data augmentation and prompt augmentation. (ii) Illustration of the data augmentation process encompasses three diverse recommendation scenarios. (iii) The pipeline of the adaptive aggregation module, which merges the predictions from the conventional recommendation model and the LLM.
Data Augmentation
Data augmentation within LLaRA2 is tailored to enhance conventional systems based on specific recommendation scenarios. For direct recommendations, LLaRA2 employs Bayesian Personalized Ranking (BPR) by leveraging LLMs to derive item preference predictions, thus enriching training datasets. Sequential recommendations are improved by inserting items likely preferred by the user into their interaction sequences. In rating prediction contexts, LLMs enrich the training datasets with additional side information, countering inherent data gaps like missing attributes.
Prompt Augmentation
Prompt augmentation empowers LLMs by incorporating pertinent collaborative information within the prompts. Techniques include embedding similar user interactions and conventional model predictions to guide LLM predictions. This augmentation fosters LLMs’ ability to process contextual and collaborative information, enhancing their effectiveness across recommendation tasks.
Adaptive Aggregation
Adaptive aggregation within LLaRA2 balances predictions from LLMs and conventional models based on user long-tail coefficients. This strategy allows the framework to address unique user interaction patterns effectively, thus optimizing recommendation outputs. The aggregate result leverages the strong semantic capabilities of LLMs, particularly for users with sparse interaction data.
Experimental Analysis
Extensive tests on several datasets demonstrate LLaRA2's superiority over traditional methods. Results consistently show enhanced recommendation accuracy for rating predictions and top-k recommendations across models like LightGCN, SASRec, and others. Notably, LLaRA2 outperforms Instruction Fine-Tuning (IFT) by significantly addressing the alignment challenges between general-purpose LLMs and specialized recommendation tasks.
Hyperparameter Impact
An analysis on hyperparameters α1 and α2 reveals their critical roles in adaptive aggregation performance. Incremental tuning suggests an optimal range where LLaRA2’s efficacy is maximized, underscoring the importance of tailored weight assignments in recommendation scenarios.
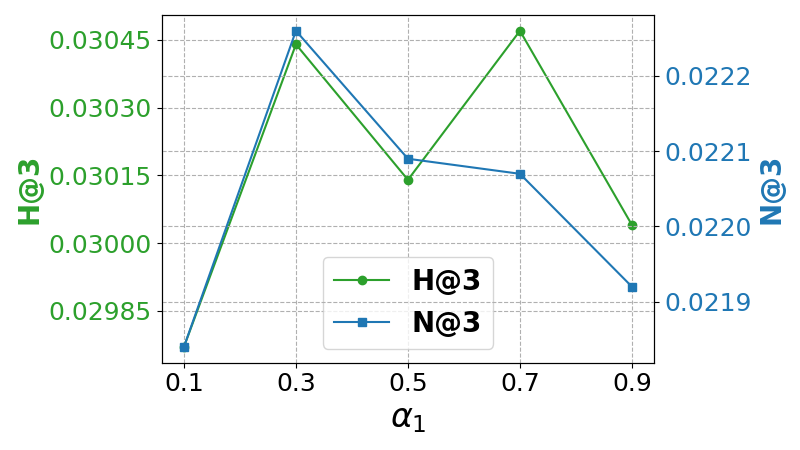
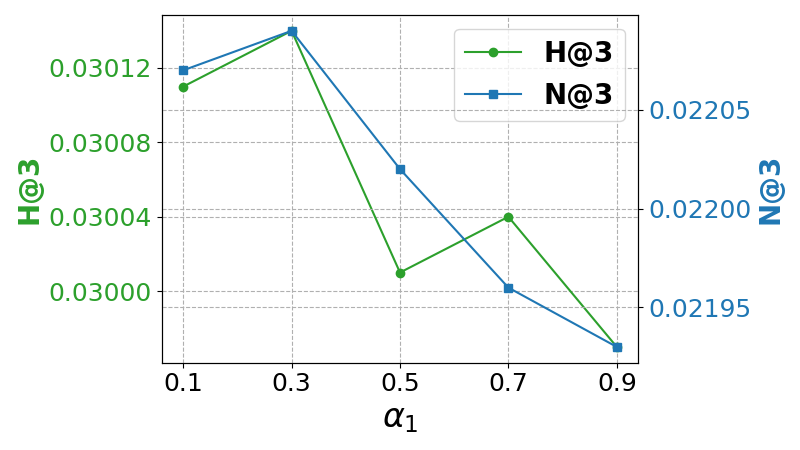
Figure 2: Impact of hyper-parameters α1 and α2 on ML-1M dataset with backbone model LightGCN.
Model and Data Scaling
Experiments illustrate performance variations with different LLaMA-2 model sizes and instruction dataset volumes. Larger models, such as LLaMA-2 13B, slightly outperform smaller models but with diminishing returns relative to computational cost. Meanwhile, increased instruction datasets enhance recommendation accuracy significantly, highlighting the benefits of substantial data exposure during LLM tuning.
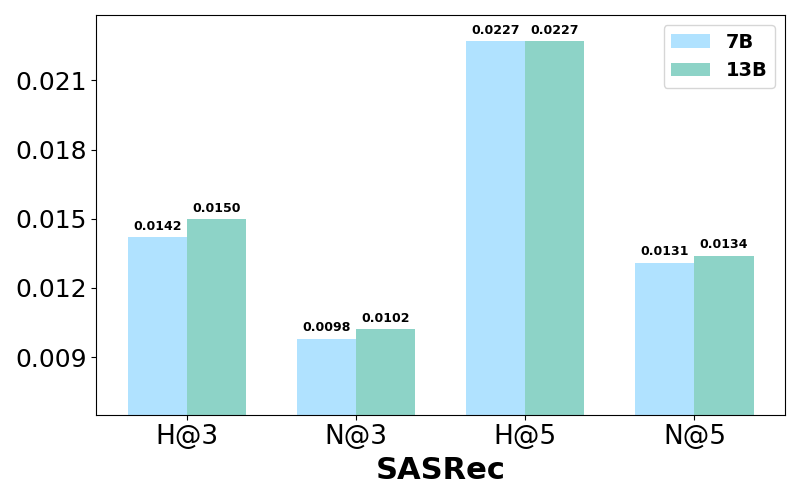
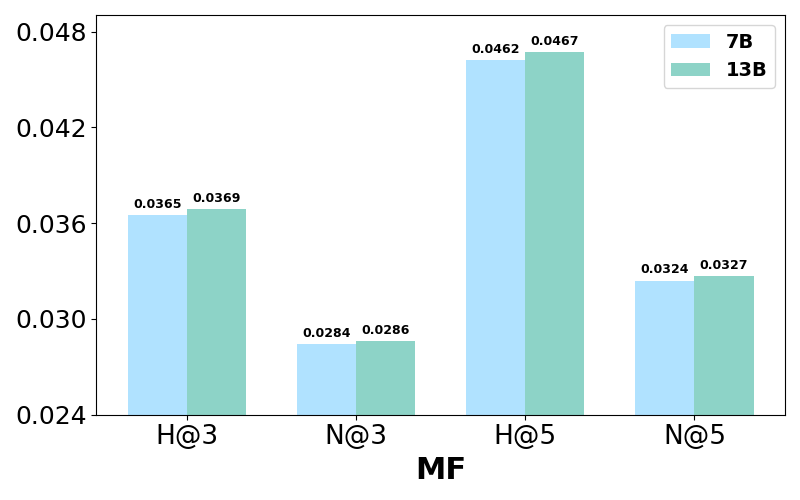
Figure 3: Performance comparison w.r.t different LLaMA-2 size for training LLaRA2 on the Bookcrossing dataset.
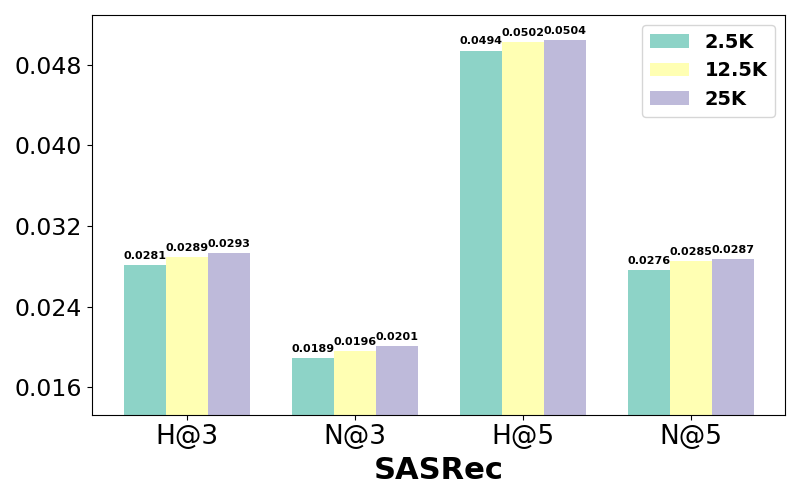
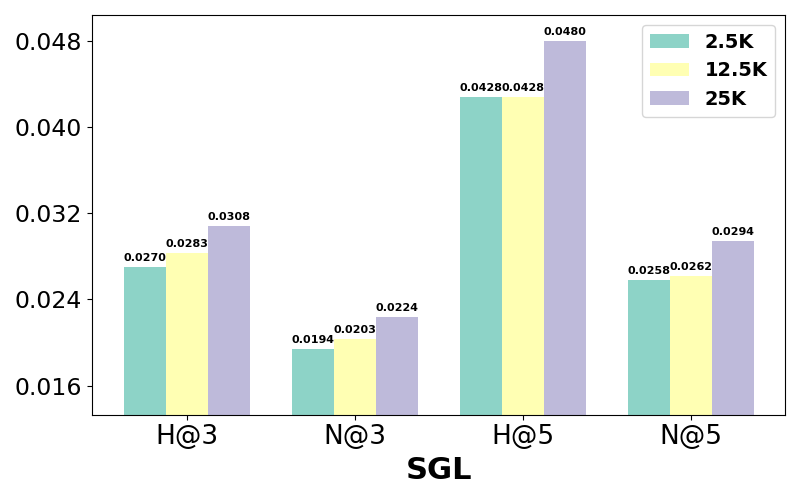
Figure 4: Performance comparison w.r.t different numbers of instructions for training LLaRA2 on the ML-1M dataset.
Conclusion
LLaRA2 presents a promising model-agnostic framework effectively integrating LLMs into conventional recommendation systems via mutual augmentation and adaptive aggregation. LLaRA2 not only improves recommendation accuracy through a nuanced blending of semantic and collaborative insights but also sets a precedent for future research in AI-driven recommendation systems. Continued advancements in AI hardware and algorithms may further optimize LLaRA2, paving the way for its application in large-scale, real-time recommendation environments.