- The paper introduces a policy-free SiMT system by fine-tuning LLaMA-2 with a novel <WAIT> token to dynamically manage input segmentation.
- It employs a causal alignment strategy using LoRA, ensuring that target tokens are generated after corresponding source words to maintain translation quality.
- The study demonstrates competitive BLEU scores and balanced quality-latency tradeoffs on en-de and en-ru datasets, highlighting potential for both supervised and zero-shot translation.
TransLLaMa: LLM-based Simultaneous Translation System
Introduction
The "TransLLaMa: LLM-based Simultaneous Translation System" paper explores the potential of using LLMs, specifically pre-trained decoder-only architectures, for simultaneous machine translation (SiMT) tasks, traditionally dominated by encoder-decoder transformers. Through fine-tuning with a causally aligned dataset, these models have been shown to handle SiMT tasks efficiently, utilizing a novel <WAIT> token to manage input segmentation without requiring separate translation policies. The performance of these models is competitive with state-of-the-art SiMT systems for English-German and English-Russian language pairs, achieving comparable BLEU scores and latency metrics.
Methodology
The proposed methodology involves fine-tuning pre-trained LLMs on causally aligned source-target sentence pairs. The causal alignment ensures that target content words do not appear before their source equivalents by introducing <WAIT> tokens in target sequences. This approach eliminates the need for a separate SiMT policy, allowing the LLM to decide when to generate a translation and when to read more of the source input dynamically.
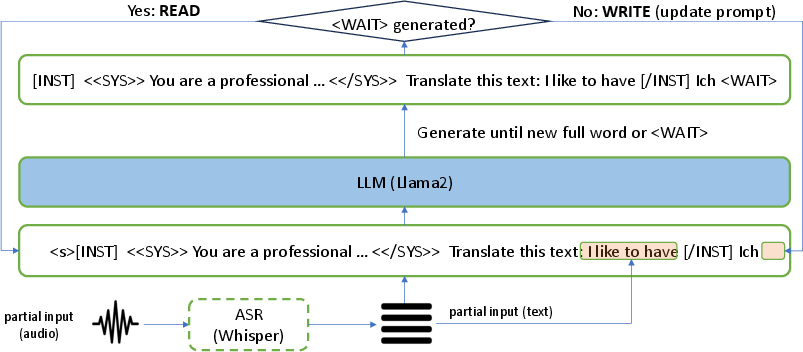
Figure 1: Model overview showing the processing of the source audio stream using an ASR model and integration with the initial and updated prompts in the LLM.
Causal alignment is achieved by using the SimAlign tool to map source words to target counterparts, inserting <WAIT> tokens as needed, and aligning source-target pairs in terms of word order and timing.
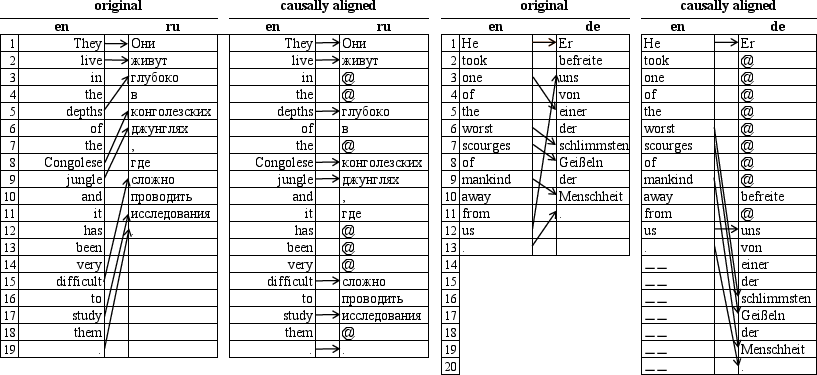
Figure 2: Causal alignment examples for en-ru and en-de language pairs, demonstrating the use of <WAIT> tokens to ensure causality.
Implementation and Inference
Fine-tuning the LLaMA-2 models involves optimizing the likelihood of predicting the next target token conditioned on previously generated tokens and given partial source inputs. Models are fine-tuned using LoRA for parameter-efficient training, implemented on large-scale hardware to accommodate LLAMA-2's size.
During inference, translation quality and latency are balanced by controlling when the model produces output tokens. The system uses a modified wait-k policy that dynamically adjusts the number of source words processed before writing a translated output, improving the quality-latency tradeoff.
Results and Comparison
The model's performance was evaluated on the MuST-C v2.0 and TED-TST-2023 datasets, showing that fine-tuning LLaMA-2 models performed comparably to current SiMT baselines.
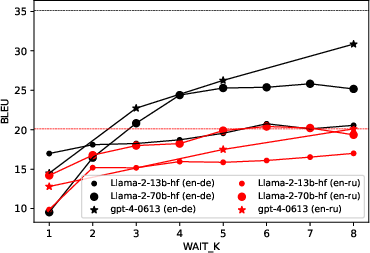
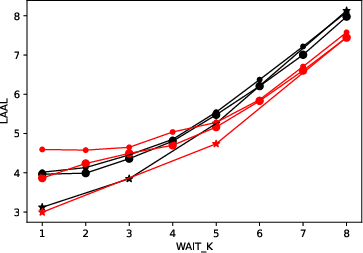
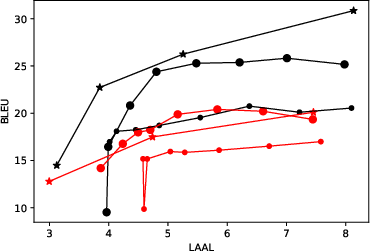
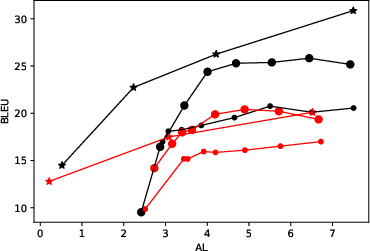
Figure 3: Quality-latency tradeoff curves for T2TT mode illustrates dependence on the number of words processed (k) for en-de and en-ru language pairs.
In S2TT mode, the LLMs were tested against recently published baselines and GPT-4 in zero-shot scenarios, highlighting the efficacy of the fine-tuned models in both supervised and zero-shot contexts. Despite a slight drop in BLEU scores in S2TT mode due to ASR errors, the results remain promising.
(Figure 4, Figure 5)
Figure 4: S2TT performance comparison of fine-tuned LLaMA-2 and baseline models in the en-de language pair.
Figure 5: Zero-shot S2TT performance illustrating the effectiveness of GPT-4 compared to LLaMA-2-CHAT.
Discussion and Future Directions
The results suggest that fine-tuning LLMs on causally aligned datasets can enable policy-free simultaneous translation, offering significant simplification over traditional approaches that rely on sophisticated policies and architectures. This method's success with additional training and prompt engineering points to future improvements in multilingual SiMT systems.
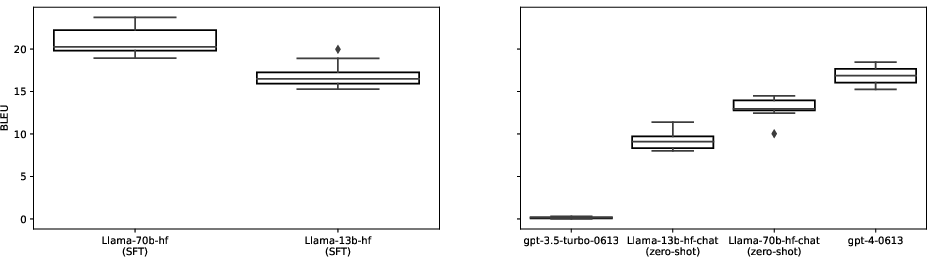
Figure 6: Performance degradation in T2TT compared to S2TT mode due to ASR-related errors.
Future work could aim to integrate background information into prompts for improved context-awareness, explore end-to-end ASR and translation models to reduce latency, and address potential biases by training on more linguistically balanced datasets.
Conclusion
The paper presents TransLLaMa as a compelling approach for SiMT tasks by leveraging the agential capabilities of LLMs through a simple yet effective fine-tuning strategy. This advancement suggests the potential of LLMs for applications beyond standard text translation, paving the way for further research into efficient and high-quality SiMT systems.