- The paper presents a novel boosting-based method for sequentially constructing meta-tree ensembles to reduce overfitting in decision trees.
- The methodology leverages CART to build representative trees and converts them into meta-trees including all subtrees, optimizing the mean squared error.
- Experimental results on synthetic and benchmark datasets show improved accuracy and smaller Bayes risk compared to GBDT and LightGBM.
The paper "Boosting-Based Sequential Meta-Tree Ensemble Construction for Improved Decision Trees" (2402.06386) introduces a novel method for constructing ensembles of meta-trees using a boosting approach, addressing the overfitting issues commonly associated with deepened decision trees. The proposed method leverages the statistical optimality of meta-trees, which are sets of subtrees derived from a representative tree, to enhance predictive performance while mitigating overfitting.
Background and Motivation
Decision trees are widely used in machine learning due to their interpretability and expressivity. However, they are prone to overfitting, especially when the tree depth is excessive. While pruning and penalty terms can help control tree depth, meta-trees offer an alternative approach. A meta-tree comprises all subtrees of a representative tree, allowing for a combination of predictions from both shallow and deep trees. Ensembles of decision trees, constructed via bagging or boosting, are known to improve predictive performance, motivating the exploration of meta-tree ensembles. This paper addresses the gap in existing research by proposing a boosting-based method for sequentially constructing meta-tree ensembles.
The proposed method constructs ensembles of B meta-trees sequentially, similar to boosting algorithms. The process involves minimizing an evaluation function, specifically the mean squared error (MSE), by iteratively adding meta-trees that reduce the gradient of the error.
- Initialization: Start with an initial prediction F0 and an empty meta-tree set M.
- Residual Calculation: Compute the residual ri between the true value yi and the current prediction Fb−1(xi) for each data point.
- Tree Building: Use CART to construct a representative tree (T,kb) by splitting the data to minimize the sample variance of the residuals.
- Meta-Tree Construction: Convert the representative tree to a meta-tree MT,kb, which includes all its subtrees.
- Ensemble Update: Add the new meta-tree to the ensemble and update the prediction function Fb.
- Iteration: Repeat steps 2-5 for B iterations.
The algorithm incorporates a learning rate γ to scale the predicted values, which helps prevent overfitting by slowing down the learning process.
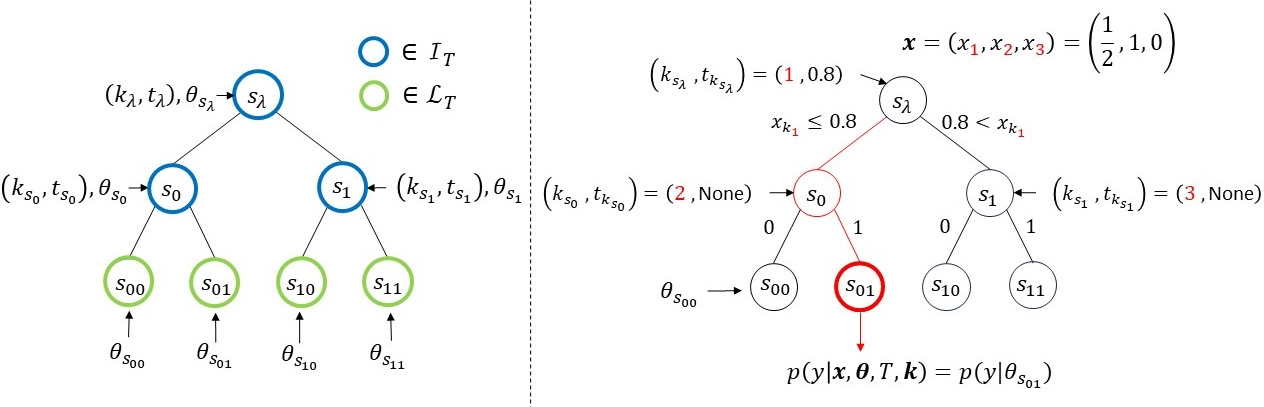
Figure 1: The notations for the binary model tree (left) and an example of the model tree (right). The subscript of x (red) represents the feature ks, and if xks is a continuous variable, it is divided by a threshold value tks. If xks is a binary variable, it is divided by a binary value of 0 or 1. If x is assigned to the root node of the model tree (right), following the red path leads to the leaf node s01. The output is generated from p(y∣θs01).
Prediction Models and Weighting Schemes
The paper explores different prediction models and weighting schemes for combining the meta-trees in the ensemble:
- GBDT-based Model: This model, similar to GBDT, learns the output of the b-th meta-tree as the residual between Fb−1 and y, using learning and predicting weights of 1.
- Probability Distribution-based Models: These models treat the weights as probabilities.
- Uniform Distribution: Analogous to Random Forest, this approach assigns uniform probabilities as weights.
- Posterior Distribution of k: This method uses the posterior distribution of the explanatory variable features k as weights. The posterior distribution is calculated based on the assumption that the prior distribution of k is uniform.
Experimental Results
The authors conducted experiments using synthetic and benchmark datasets to compare the performance of the proposed methods with conventional methods, including GBDT and LightGBM.
Experiment 1: Bayes Optimality
This experiment used synthetic data generated from a true model tree to assess the Bayes optimality of the proposed methods. The results showed that the proposed methods had smaller Bayes risk compared to GBDT and LightGBM. The method using the posterior probabilities of k (MT_pos-pos) achieved the smallest Bayes risk, indicating that the constructed meta-tree ensembles closely resembled the true model tree.
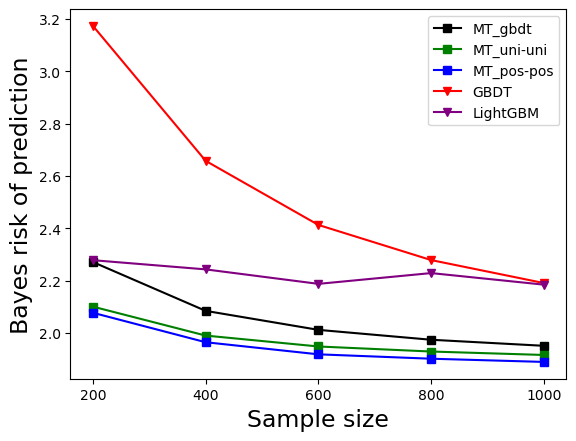
Figure 2: The result of Experiment 1
Experiment 2: Influence of Tree Depth
This experiment investigated the influence of the depth of the true model tree and the depth of the meta-trees. The results indicated that when the depth of the meta-trees increased, the methods using posterior probabilities of k exhibited smaller Bayes risk. However, when the meta-tree depth was shallower than the true model tree depth, the predictive performance of these methods was worse. In such cases, MT_gbdt and MT_uni-uni performed better.
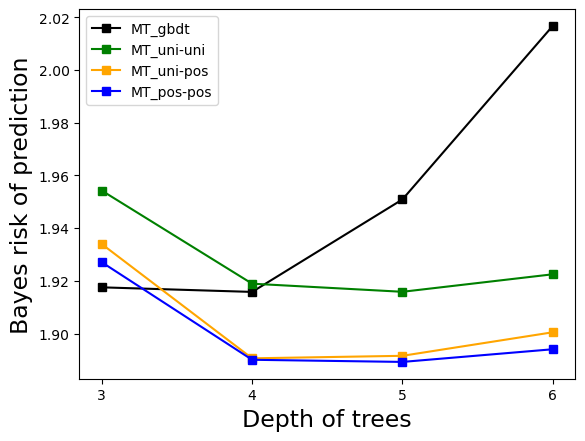
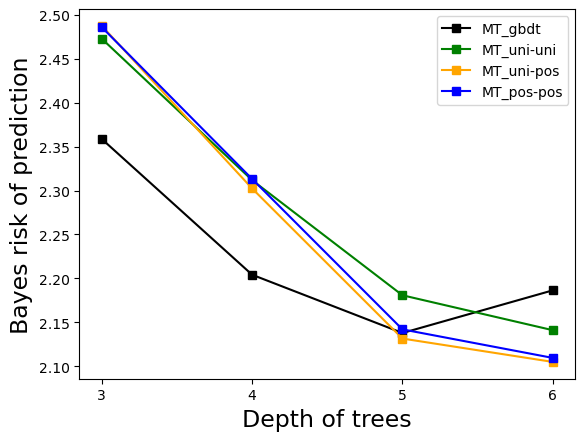
Figure 3: The result of Experiment 2. The maximum depth of the true model tree is 3,5,7, and the result of increasing the depth of the meta-trees to 3,4,5,6 is shown in (a), (b), and (c).
Experiment 3: Benchmark Datasets
The proposed methods were tested on multiple benchmark datasets for regression. The results showed that the proposed methods were generally more accurate than GBDT and LightGBM. MT_gbdt and MT_uni-uni performed better than MT_pos-pos, suggesting that these datasets might have difficulty representing the true model tree. Furthermore, the proposed methods prevented overfitting when the tree depth was increased.
Conclusion
The paper demonstrates a boosting-based approach for constructing ensembles of meta-trees, which effectively prevents overfitting even with deep trees. The experimental results confirm the properties of the proposed method on both synthetic and benchmark datasets, highlighting its potential for improving decision tree performance. The use of meta-trees and boosting provides a robust framework for handling complex datasets while maintaining statistical optimality.