- The paper introduces LoRA-drop, which prunes low-rank adaptation parameters based on output impact to retain only critical layers.
- It quantifies parameter importance using the squared norm of LoRA outputs averaged over task datasets to achieve up to 50% reduction in parameters.
- Experimental results on GLUE benchmarks and other datasets demonstrate comparable performance to full fine-tuning while improving parameter efficiency.
Summary of "LoRA-drop: Efficient LoRA Parameter Pruning based on Output Evaluation" (2402.07721)
Introduction to LoRA and Challenges
Low-Rank Adaptation (LoRA) is a method designed to fine-tune pre-trained LLMs using additional trainable parameters, marked by ΔW, for each layer to reduce computational costs while maintaining performance. Despite its success, LoRA faces resource limitations when applied to larger models. Current approaches attempt to prune LoRA parameters by evaluating parameter features like size or gradients, but these focus solely on parameter characteristics rather than analyzing the direct impact on model outputs. The paper introduces LoRA-drop, a methodology that assesses the importance of parameters by examining the output ΔWx of LoRA at each layer, thereby determining the layers that significantly affect the pre-trained model.
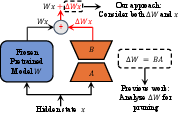
Figure 1: The diagram of LoRA.
LoRA-drop Methodology
LoRA-drop aims to enhance parameter efficiency by pruning based on LoRA output evaluation. This process begins by sampling subset datasets from specific tasks, using these to perform limited updates on LoRA. Each layer’s LoRA importance is quantified by the squared norm of its output, ΔWx, averaged over training data. Layers are then ranked by importance, preserving only those with high impact while sharing parameters for less significant layers. The final step involves model fine-tuning under this new parameter configuration.
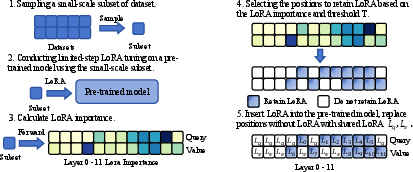
Figure 2: The overall workflow of LoRA-drop.
Experimental Validation
Extensive experiments were conducted on various NLU and NLG tasks, including GLUE benchmarks and datasets like E2E and DialogSum. Results indicate LoRA-drop achieves comparable performance to original LoRA while employing only 50% of its parameters.
For instance, on the GLUE benchmark with RoBERTa-base, LoRA-drop achieved an average score of 86.2 with a significant parameter reduction, compared to Full-FT (86.3) and LoRA (86.1). This success was mirrored in larger models like RoBERTa-large and Llama2-7b, where LoRA-drop outperformed LoRA and Full-FT in terms of parameter efficiency and task performance. These outcomes underscore the efficacy of output-based parameter pruning strategies.
Analysis and Insights
LoRA-drop demonstrates adaptability to diverse datasets as evidenced by different importance distributions across datasets, validating the approach's robustness in assessing parameter significance by output rather than pre-defined parameter metrics.
Additionally, sharing LoRA parameters among layers deemed less important minimizes impact on high-importance layers, maintaining overall performance. Sample proportion analysis showcases the method’s insensitivity to data size variations, establishing its robustness.
Threshold T plays a vital role, found optimal at 0.9, enabling effective layer selection without compromising task performance. Ablation studies confirm the necessity of shared parameters for low-importance layers and the rationale behind retaining high-impact layers.
Implications and Future Work
This research posits LoRA-drop as an effective strategy for enhancing parameter efficiency in fine-tuning pre-trained models, offering computational savings without sacrificing performance. The methodology paves the way for future work to explore its application across varied tasks and architectures, potentially refining the parameter pruning strategy and expanding its applicability beyond NLP models.
In conclusion, LoRA-drop showcases a significant stride in parameter-efficient model tuning, providing a practical framework for managing the computational needs of adapting and enhancing LLMs in diverse real-world applications.
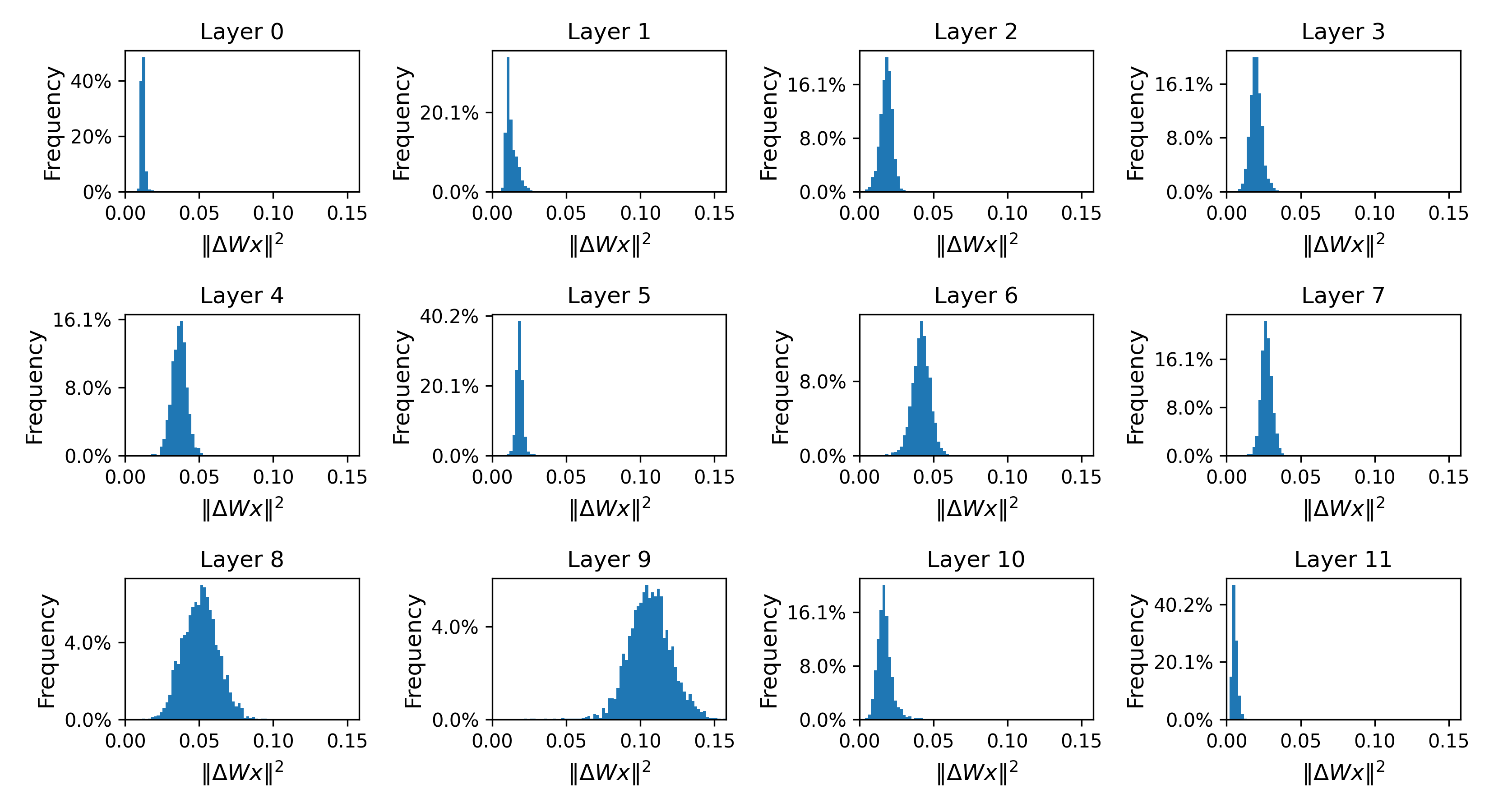
Figure 3: The frequency distribution of the squared norm of value LoRA output ΔW.