Careless Whisper: Speech-to-Text Hallucination Harms
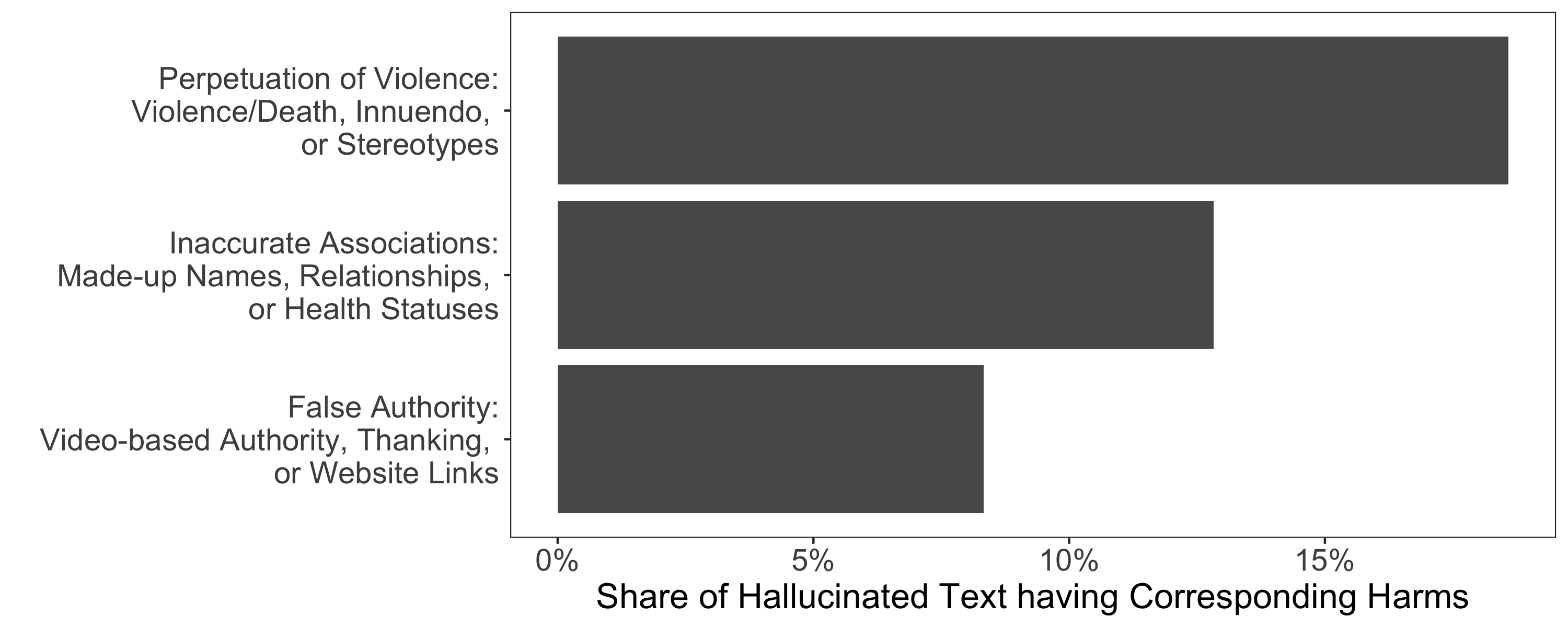
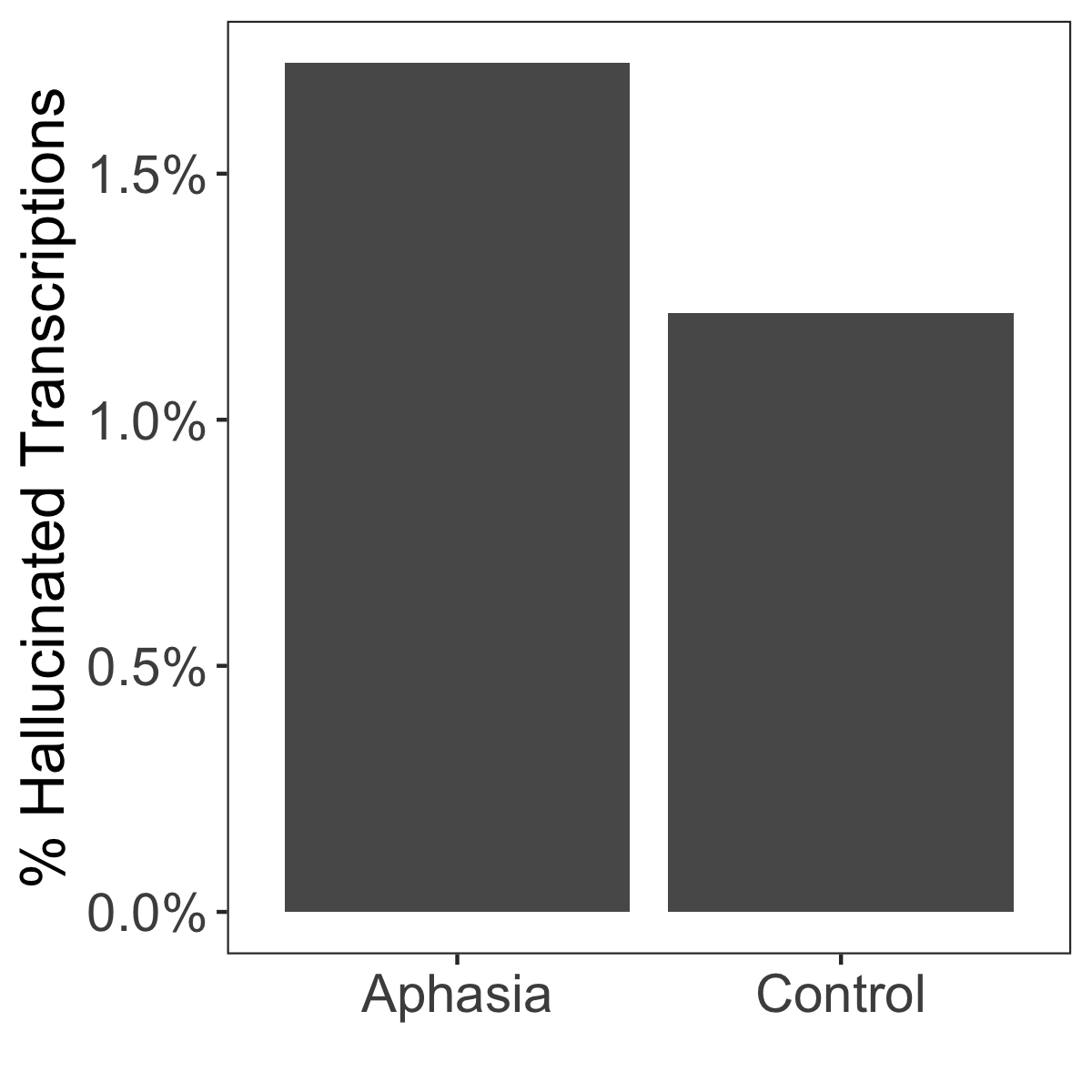
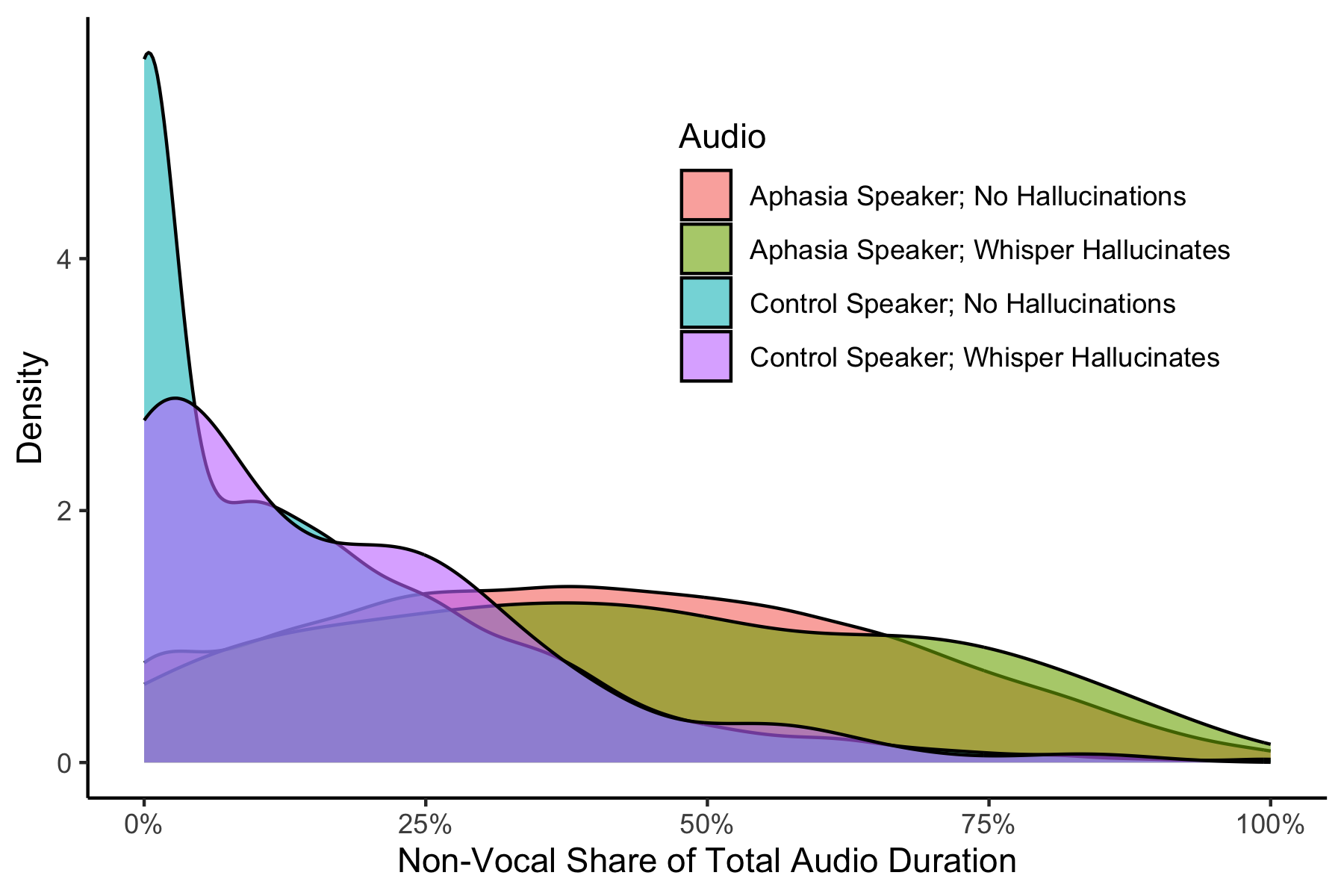
Abstract: Speech-to-text services aim to transcribe input audio as accurately as possible. They increasingly play a role in everyday life, for example in personal voice assistants or in customer-company interactions. We evaluate Open AI's Whisper, a state-of-the-art automated speech recognition service outperforming industry competitors, as of 2023. While many of Whisper's transcriptions were highly accurate, we find that roughly 1\% of audio transcriptions contained entire hallucinated phrases or sentences which did not exist in any form in the underlying audio. We thematically analyze the Whisper-hallucinated content, finding that 38\% of hallucinations include explicit harms such as perpetuating violence, making up inaccurate associations, or implying false authority. We then study why hallucinations occur by observing the disparities in hallucination rates between speakers with aphasia (who have a lowered ability to express themselves using speech and voice) and a control group. We find that hallucinations disproportionately occur for individuals who speak with longer shares of non-vocal durations -- a common symptom of aphasia. We call on industry practitioners to ameliorate these language-model-based hallucinations in Whisper, and to raise awareness of potential biases amplified by hallucinations in downstream applications of speech-to-text models.
- Fairness in machine learning. Nips tutorial 1 (2017), 2017.
- Fairness and Machine Learning: Limitations and Opportunities. MIT Press.
- David Frank Benson and Alfredo Ardila. 1996. Aphasia: A clinical perspective. Oxford University Press, USA.
- Hervé Bredin and Antoine Laurent. 2021. End-to-end speaker segmentation for overlap-aware resegmentation. In Proc. Interspeech 2021. Brno, Czech Republic.
- Chris Code and Brian Petheram. 2011. Delivering for aphasia. International Journal of Speech-Language Pathology 13, 1 (Feb. 2011), 3–10. https://doi.org/10.3109/17549507.2010.520090
- Antonio R. Damasio. 1992. Aphasia. New England Journal of Medicine 326, 8 (Feb. 1992), 531–539. https://doi.org/10.1056/nejm199202203260806
- Charles Ellis and Stephanie Urban. 2016. Age and aphasia: a review of presence, type, recovery and clinical outcomes. Topics in Stroke Rehabilitation 23, 6 (2016), 430–439. https://doi.org/10.1080/10749357.2016.1150412 arXiv:https://doi.org/10.1080/10749357.2016.1150412 PMID: 26916396.
- Gunther Eysenbach. 2023. The Role of ChatGPT, Generative Language Models, and Artificial Intelligence in Medical Education: A Conversation With ChatGPT and a Call for Papers. JMIR Medical Education 9 (March 2023), e46885. https://doi.org/10.2196/46885
- Graham R Gibbs. 2007. Thematic coding and categorizing. Analyzing qualitative data 703 (2007), 38–56.
- Survey of hallucination in natural language generation. Comput. Surveys 55, 12 (2023), 1–38.
- Racial disparities in automated speech recognition. Proceedings of the National Academy of Sciences 117, 14 (2020), 7684–7689.
- Quantifying and Improving the Performance of Speech Recognition Systems on Dysphonic Speech. Otolaryngology–Head and Neck Surgery 168, 5 (Jan. 2023), 1130–1138. https://doi.org/10.1002/ohn.170
- AphasiaBank: Methods for studying discourse. Aphasiology 25 (2011), 1286–1307.
- John Markoff. 2019. From Your Mouth to Your Screen, Transcribing Takes the Next Step. New York Times (October 2019).
- OpenAI. 2023a. GPT 3.5. https://platform.openai.com/docs/models/gpt-3-5. Accessed: 2023-11-25.
- OpenAI. 2023b. Speech to text. https://platform.openai.com/docs/guides/speech-to-text. Accessed: 2023-11-25.
- Augmented Datasheets for Speech Datasets and Ethical Decision-Making. In Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency. 881–904.
- Alexis Plaquet and Hervé Bredin. 2023. Powerset multi-class cross entropy loss for neural speaker diarization. In Proc. INTERSPEECH 2023.
- Robust Speech Recognition via Large-Scale Weak Supervision. arXiv (2022). arXiv:arXiv:2212.04356
- Donald B Rubin. 1980. Bias reduction using Mahalanobis-metric matching. Biometrics (1980), 293–298.
- Hallucination of Speech Recognition Errors With Sequence to Sequence Learning. IEEE/ACM Transactions on Audio, Speech, and Language Processing 30 (2022), 890–900. https://doi.org/10.1109/taslp.2022.3145313
- David Sherfinski and Avi Asher-Schapiro. 2021. U.S. prisons mull AI to analyze inmate phone calls. Thomson Reuters Foundation News (August 2021).
- Silero Team. 2021. Silero VAD: pre-trained enterprise-grade Voice Activity Detector (VAD), Number Detector and Language Classifier. https://github.com/snakers4/silero-vad.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.