- The paper presents DataDreamer, a Python library that unifies synthetic data generation, fine-tuning, and evaluation in LLM workflows.
- It uses a standardized API with caching and multi-GPU training to optimize performance and reduce redundant computations.
- Implications include enhanced reproducibility, simplified implementation, and improved open science practices in NLP research.
"DataDreamer: A Tool for Synthetic Data Generation and Reproducible LLM Workflows" introduces a Python library aimed at simplifying and standardizing the implementation of advanced workflows involving LLMs. The paper articulates a solution to the challenges posed by these workflows, such as complexity, high computational costs, and reproducibility concerns. DataDreamer enhances the accessibility and reproducibility of such tasks, streamlining synthetic data generation, fine-tuning, model alignment, and other LLM-related research workflows.
Motivation and Context
The introduction of LLMs has significantly impacted the landscape of NLP research. However, their deployment presents unique challenges such as non-standardized implementations, closed-source constraints, and expensive computational requirements, which complicate reproducibility and open science initiatives. DataDreamer emerges as a response to these issues, facilitating a unified approach to handling various LLM workflows while promoting consistency and reproducibility.
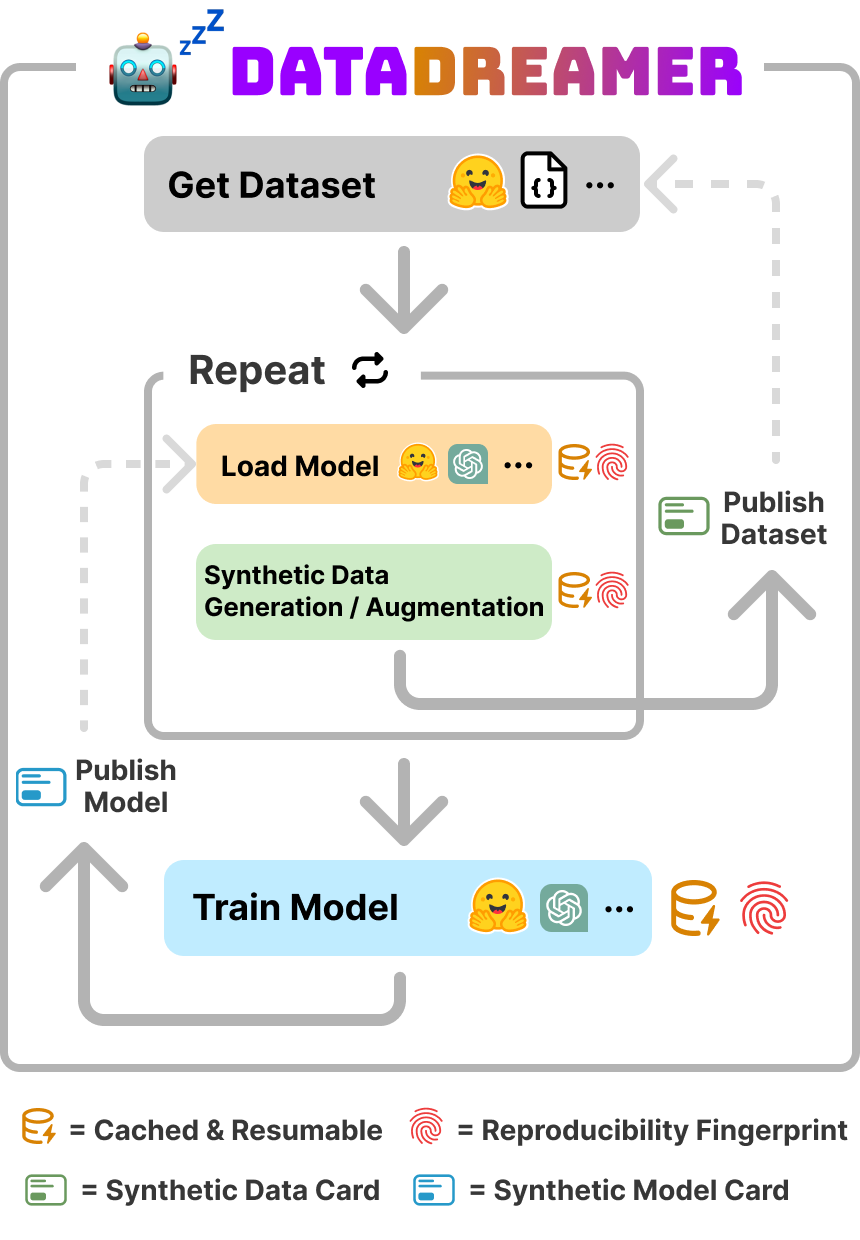
Figure 1: DataDreamer helps researchers implement many types of LLM workflows easier and makes reproducibility automatic and simple. These workflows often involve synthetic data generation with a LLM-in-the-loop and/or fine-tuning, aligning, and distilling models.
Supported LLM Workflows
DataDreamer supports a range of workflows frequently used in contemporary NLP research:
- Synthetic Data Generation: LLMs are used to augment existing datasets or create new synthetic datasets, which are increasingly vital for task performance enhancement and adversarial robustness.
- Task Evaluation with LLMs: The tool leverages LLMs as evaluators to streamline performance assessment against specific tasks, addressing reproducibility challenges related to prompt sensitivity.
- Fine-tuning and Alignment: Efficient fine-tuning workflows are supported to allow tailored task-specific models, using techniques like instruction-tuning and alignment optimizations such as RLHF and DPO.
- Self-Improving LLMs: DataDreamer enables complex self-improvement loops wherein models generate and evaluate their outputs for iterative enhancement.
These workflows have typically been fragmented and challenging to replicate, but DataDreamer's cohesive framework seeks to integrate them under a standardized API.
Key Features and Implementation Details
DataDreamer addresses practical and infrastructural challenges with a suite of features:
- Standardized Interface: The library abstracts diverse LLM APIs under a unified interface, facilitating model substitution and workflow adaptations without extensive re-coding efforts.
- Caching and Resumability: A multi-tier caching system minimizes redundant computations, allowing users to resume interrupted workflows and share cached outputs for reproducibility and peer validation.
- Parallelization and Multi-GPU Training: The tool supports multi-GPU configurations and leverages PyTorch FSDP for distributed processing, making it suitable for high-performance computing environments.
- Synthetic Data and Model Cards: Automatically generated documents trace the data lineage and configuration specifics, playing a crucial role in preventing misutilization of synthetic data and ensuring compliance with licensing and attribution norms.
Practical Considerations and Limitations
While DataDreamer significantly simplifies LLM workflows, its reliance on closed-source models reveals limitations in guaranteeing complete reproducibility, as remote APIs and underlying model architectures may change over time. The tool's caching methodology mitigates this by preserving state and intermediate outputs. Nevertheless, users are encouraged to embrace open models when possible to maximize reproducibility and transparency.
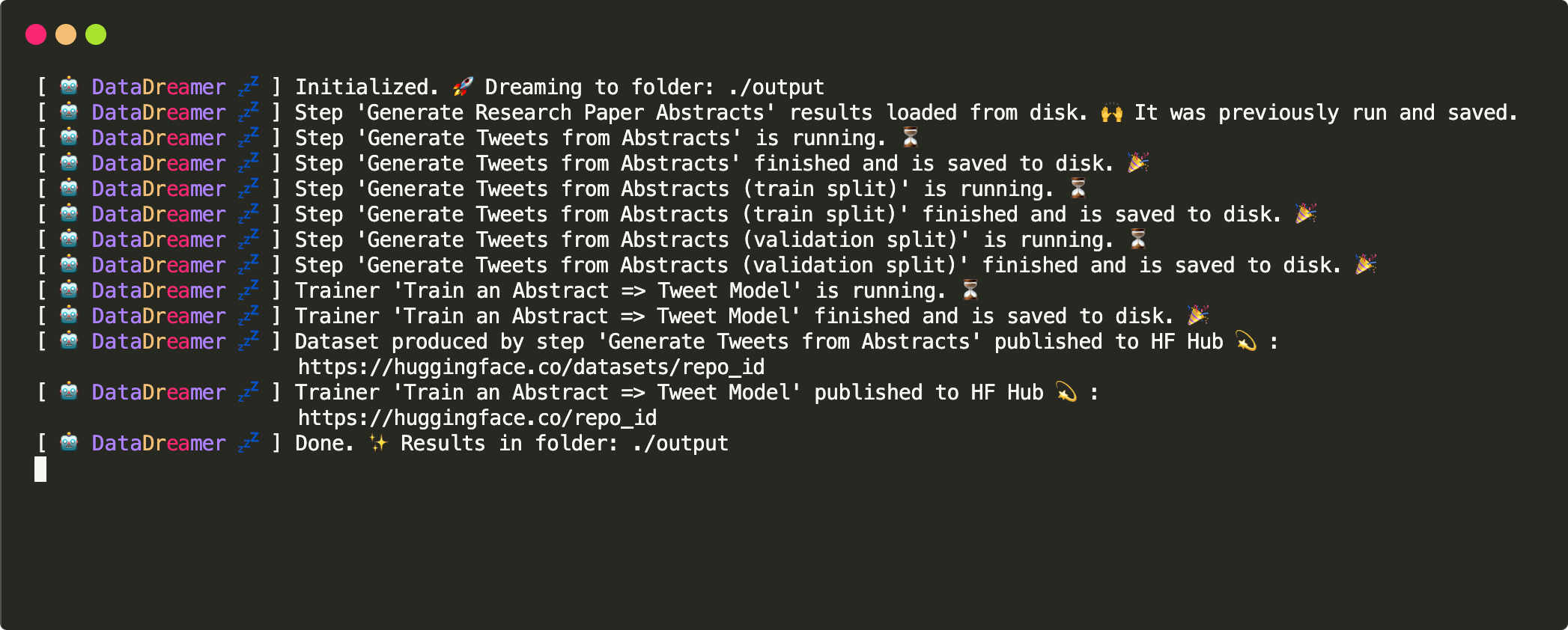
Figure 2: DataDreamer logs produced by the workflow in Example when resuming from a prior interrupted run.
Conclusion
DataDreamer represents a progressive step towards standardized LLM research workflows, addressing the pressing challenges of reproducibility and open science in the field of NLP. By providing a structured environment conducive to reproducible experimentation, it empowers researchers to focus more on advancing task performance and less on navigating the intricacies of implementation and resource management. The tool's design reflects an acute awareness of practical constraints in contemporary AI research, making it a valuable asset for the community.