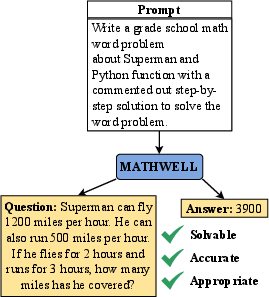
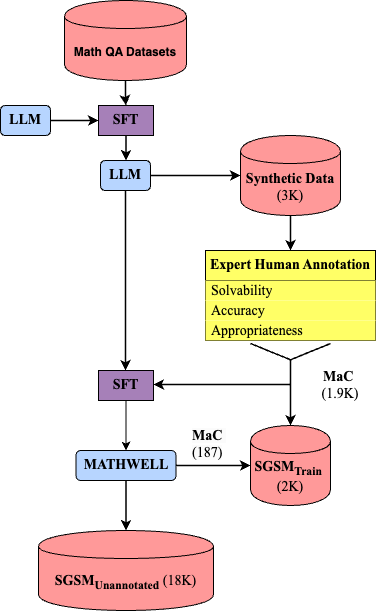
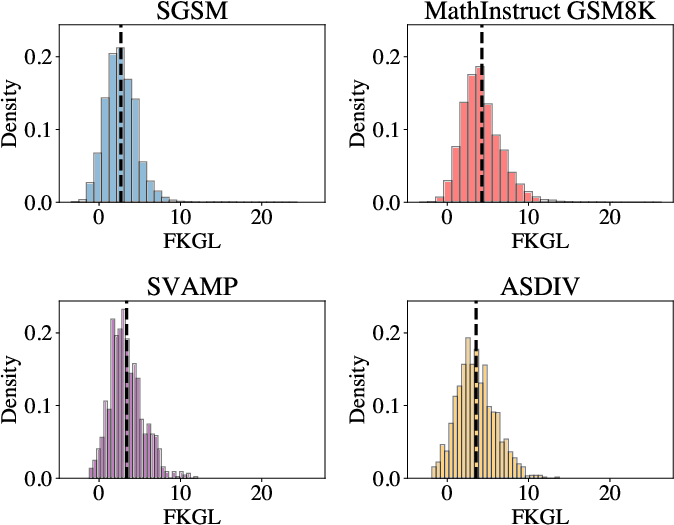
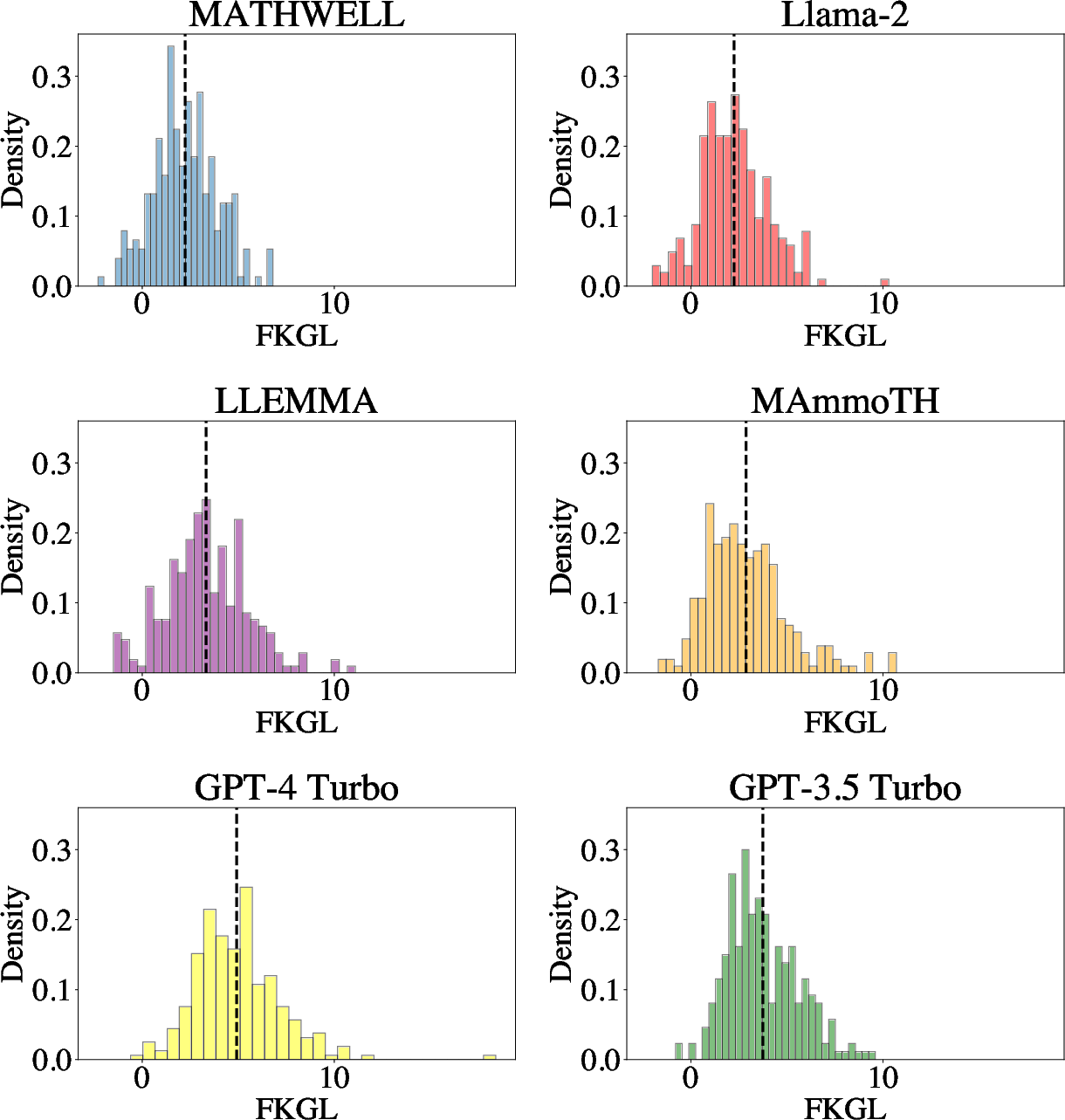
MATHWELL: Generating Educational Math Word Problems Using Teacher Annotations
Abstract: Math word problems are critical K-8 educational tools, but writing them is time consuming and requires extensive expertise. To be educational, problems must be solvable, have accurate answers, and, most importantly, be educationally appropriate. We propose that LLMs have potential to support K-8 math education by automatically generating word problems. However, evaluating educational appropriateness is hard to quantify. We fill this gap by having teachers evaluate problems generated by LLMs, who find existing models and data often fail to be educationally appropriate. We then explore automatically generating educational word problems, ultimately using our expert annotations to finetune a 70B LLM. Our model, MATHWELL, is the first K-8 word problem generator targeted at educational appropriateness. Further expert studies find MATHWELL generates problems far more solvable, accurate, and appropriate than public models. MATHWELL also matches GPT-4's problem quality while attaining more appropriate reading levels for K-8 students and avoiding generating harmful questions.
- Shivam Bansal Aggarwal, Chaitanya. textstat: Calculate statistical features from text.
- Llemma: An Open Language Model For Mathematics. ArXiv:2310.10631 [cs].
- Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback. ArXiv:2204.05862 [cs].
- Matthew L. Bernacki and Candace Walkington. 2018. The role of situational interest in personalized learning. Journal of Educational Psychology, 110(6):864–881. Place: US Publisher: American Psychological Association.
- Jeanne Sternlicht Chall and Edgar Dale. 1995. Readability Revisited: The New Dale-Chall Readability Formula. Brookline Books. Google-Books-ID: 2nbuAAAAMAAJ.
- Training Verifiers to Solve Math Word Problems. ArXiv:2110.14168 [cs].
- Word problems: a review of linguistic and numerical factors contributing to their difficulty. Frontiers in Psychology, 6:348.
- QLoRA: Efficient Finetuning of Quantized LLMs. ArXiv:2305.14314 [cs].
- R. Flesch. 1948. A new readability yardstick. The Journal of Applied Psychology, 32(3):221–233.
- PAL: Program-aided Language Models. ArXiv:2211.10435 [cs].
- Human-instruction-free llm self-alignment with limited samples.
- Measuring Massive Multitask Language Understanding. ArXiv:2009.03300 [cs].
- Measuring Mathematical Problem Solving With the MATH Dataset. ArXiv:2103.03874 [cs].
- Automatic Educational Question Generation with Difficulty Level Controls. In Artificial Intelligence in Education, Lecture Notes in Computer Science, pages 476–488, Cham. Springer Nature Switzerland.
- K5Learning. Free worksheets.
- Derivation of New Readability Formulas (Automated Readability Index, Fog Count and Flesch Reading Ease Formula) for Navy Enlisted Personnel:. Technical report, Defense Technical Information Center, Fort Belvoir, VA.
- A theme-rewriting approach for generating algebra word problems. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 1617–1628, Austin, Texas. Association for Computational Linguistics.
- Solving Quantitative Reasoning Problems with Language Models. ArXiv:2206.14858 [cs].
- Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct.
- A Diverse Corpus for Evaluating and Developing English Math Word Problem Solvers. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 975–984, Online. Association for Computational Linguistics.
- LILA: A Unified Benchmark for Mathematical Reasoning. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 5807–5832, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- NumGLUE: A Suite of Fundamental yet Challenging Mathematical Reasoning Tasks. ArXiv:2204.05660 [cs].
- Math Word Problem Generation with Multilingual Language Models. In Proceedings of the 15th International Conference on Natural Language Generation, pages 144–155, Waterville, Maine, USA and virtual meeting. Association for Computational Linguistics.
- Rewriting math word problems with large language models. Proceedings of the Workshop on Empowering Education with LLMs-the Next-Gen Interface and Content Generation 2023 co-located with 24th International Conference on Artificial Intelligence in Education (AIED 2023), 3487:163–172.
- Training language models to follow instructions with human feedback. ArXiv:2203.02155 [cs].
- Are NLP Models really able to Solve Simple Math Word Problems? ArXiv:2103.07191 [cs].
- What teachers say about student difficulties solving mathematical word problems in grades 2-5. International Electronic Journal of Mathematics Education, 8:3–19.
- A Mathematical Word Problem Generator with Structure Planning and Knowledge Enhancement. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’23, pages 1750–1754, New York, NY, USA. Association for Computing Machinery.
- Anne Roche. 2013. Choosing, creating and using story problems: Some helpful hints. Australian Primary Mathematics Classroom, 18(1):30–35.
- Distilbert, a distilled version of BERT: smaller, faster, cheaper and lighter. CoRR, abs/1910.01108.
- Sarah Schwartz. 2023. Why Word Problems Are Such a Struggle for Students—And What Teachers Can Do. Education Week.
- Learning to summarize from human feedback. ArXiv:2009.01325 [cs].
- Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca.
- Llama 2: Open foundation and fine-tuned chat models.
- TPT. Teaching Resources & Lesson Plans | TPT.
- VDOE. SOL Practice Items (All Subjects) | Virginia Department of Education.
- Word Problems in Mathematics Education: A Survey. ZDM: The International Journal on Mathematics Education, 52(1):1–16. Publisher: Springer ERIC Number: EJ1243930.
- Candace A. Walkington. 2013. Using adaptive learning technologies to personalize instruction to student interests: The impact of relevant contexts on performance and learning outcomes. Journal of Educational Psychology, 105(4):932–945. Place: US Publisher: American Psychological Association.
- Step-on-feet tuning: Scaling self-alignment of llms via bootstrapping.
- Self-Consistency Improves Chain of Thought Reasoning in Language Models. ArXiv:2203.11171 [cs].
- Math Word Problem Generation with Mathematical Consistency and Problem Context Constraints. ArXiv:2109.04546 [cs].
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. ArXiv:2201.11903 [cs].
- HuggingFace’s Transformers: State-of-the-art Natural Language Processing. ArXiv:1910.03771 [cs].
- MAmmoTH: Building Math Generalist Models through Hybrid Instruction Tuning. ArXiv:2309.05653 [cs].
- Bertscore: Evaluating text generation with bert.
- GPT-Fathom: Benchmarking Large Language Models to Decipher the Evolutionary Path towards GPT-4 and Beyond. ArXiv:2309.16583 [cs].
- Qingyu Zhou and Danqing Huang. 2019. Towards Generating Math Word Problems from Equations and Topics. In Proceedings of the 12th International Conference on Natural Language Generation, pages 494–503, Tokyo, Japan. Association for Computational Linguistics.
- Learning by analogy: Diverse questions generation in math word problem.
- Fine-Tuning Language Models from Human Preferences. ArXiv:1909.08593 [cs, stat].
- Mingyu Zong and Bhaskar Krishnamachari. 2023. Solving Math Word Problems concerning Systems of Equations with GPT-3. Proceedings of the AAAI Conference on Artificial Intelligence, 37(13):15972–15979. Number: 13.
- Zooniverse. Zooniverse.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.