- The paper demonstrates that training data contamination inflates performance metrics in code generation benchmarks.
- It employs both surface-level (Levenshtein distance) and semantic (AST-based k-gram) similarity measures to detect contamination.
- Results show performance gaps up to 50% between seen and unseen tasks, emphasizing the need for de-contaminated benchmarks.
Quantifying Data Contamination in Evaluating Code Generation Capabilities of LLMs
Introduction
The paper "Quantifying Contamination in Evaluating Code Generation Capabilities of LLMs" (2403.04811) investigates how data contamination impacts the evaluation benchmarks commonly used for assessing the code generation abilities of LLMs. With LLMs increasingly trained on large-scale datasets, there's a critical need to understand the overlap between the pretraining corpus and the test benchmarks, especially in the programming domain. This contamination can lead to artificially inflated performance metrics when models encounter tasks they have essentially "seen" during training.
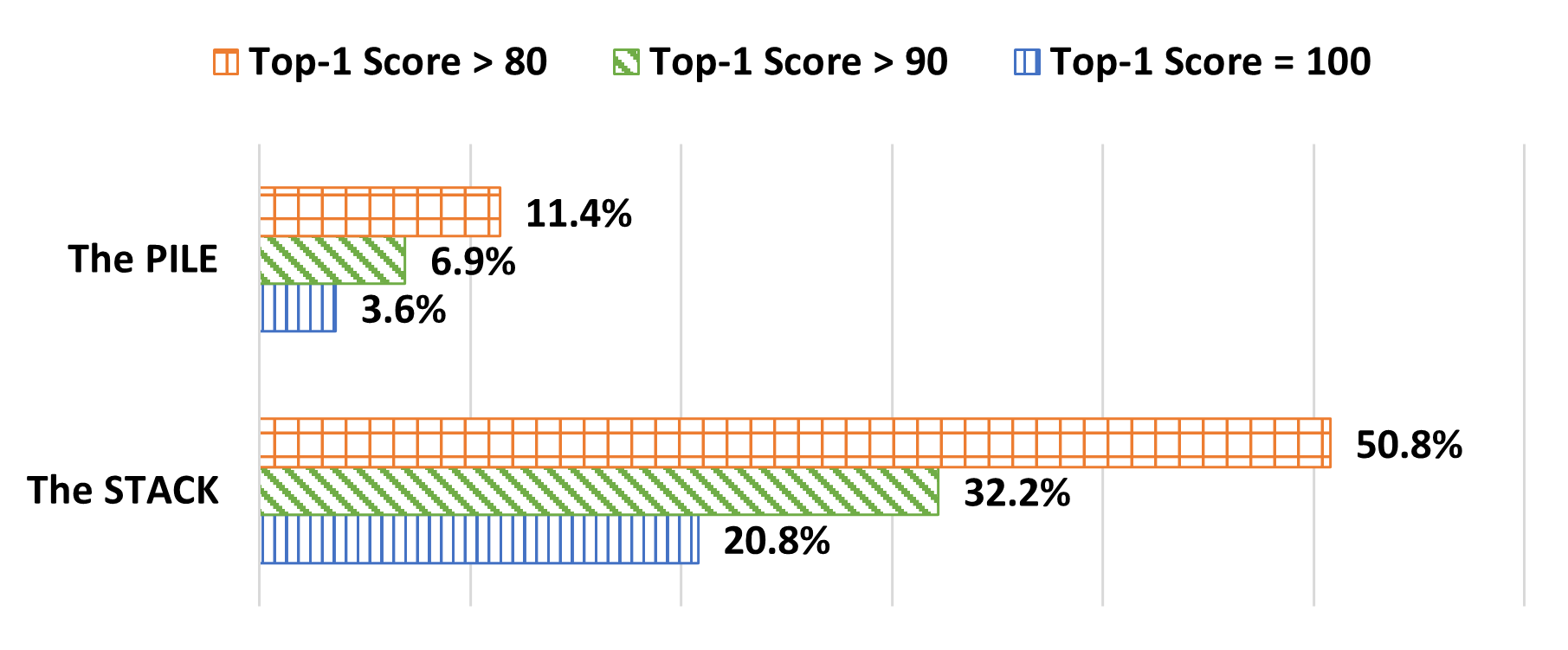

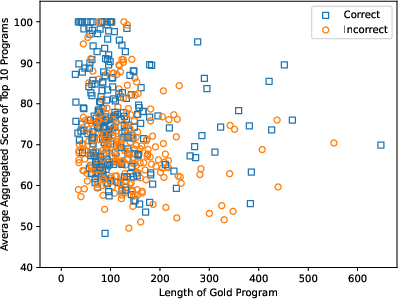
Figure 1: Data contamination on the MBPP benchmark.
LLMs are known to perform significantly better on evaluation samples that resemble the data encountered during their training phases, which raises concerns over their generalization capabilities. This paper specifically explores these concerns within the context of code generation, differing from natural language generation due to unique attributes like syntax requirements and naming conventions. These differences necessitate a specialized approach for identifying contamination beyond surface-level document comparisons.
Methodology
Measuring Program Similarity
The study employs two primary methods to gauge program similarity: surface-level and semantic-level comparisons.
Quantifying Data Contamination
Data contamination is quantified by searching for substring and semantic matches between test benchmarks (MBPP and HumanEval) and pretraining corpora (The Pile and The Stack). This involves a rigorous comparison of each benchmark problem's gold solution against pretraining data, leveraging computationally intensive substring matching before applying detailed semantic evaluations. Aggregated similarity scores are then computed, reflecting the maximum score from both similarity measurement types.
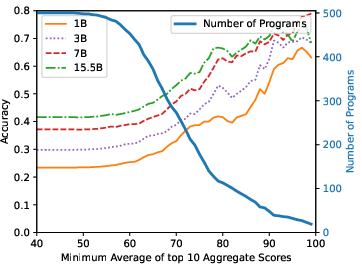
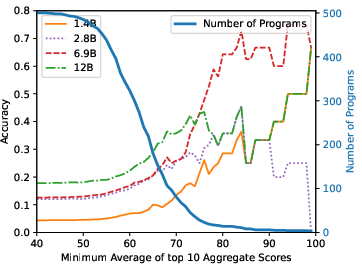
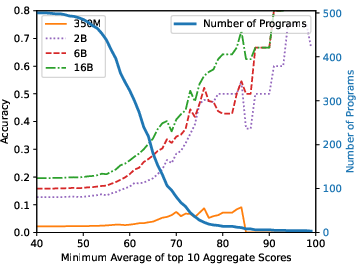
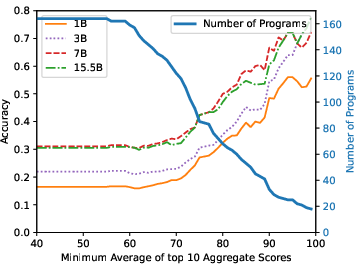
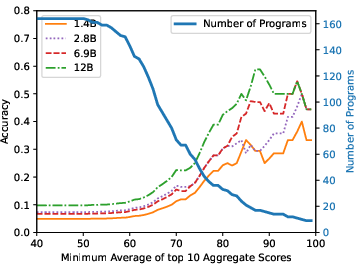
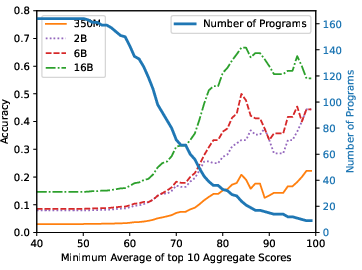
Figure 3: StarCoderBase on MBPP.
Results
The research finds substantive contamination in popular benchmarks, with direct overlap rates ranging from 3.6% to 20.8% for subsets of test problems. Models trained on contaminated data show notably higher performance on tasks with seen solutions, underscoring the issue. For instance, StarCoderBase-15.5B achieves an accuracy of 72% on the top 10% most similar questions but only 22% on the least similar. This performance variability is consistent across different model series studied, indicating a pervasive impact of contamination on perceived model capability.
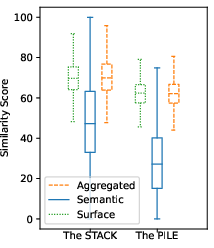
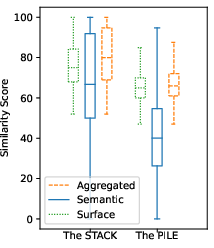
Figure 4: Top-10 Scores.
Despite attempts at dataset de-contamination, performance diminished significantly upon removal of questions with high similarity scores. This result suggests that while improvements in model architecture might contribute to performance differences, contamination is a significant factor in observed accuracies.
Analysis and Future Directions
The study further explores the relationship between question difficulty, model size, and contamination effects. Larger models exhibited superior performance, indicating improved generalization and memorization capabilities. Analysis also revealed that model performance on instances with known solutions isn't merely a function of question simplicity, supporting the need for de-contamination in benchmark assessments.
The implications for future research are profound: developing evaluation frameworks that minimize contamination is crucial for providing accurate assessments of a model's true generalization capability. Enhancing contamination detection methods and expanding the availability of non-contaminated benchmarks may aid in achieving more reliable evaluations. Furthermore, as training datasets expand and evolve, ongoing attention to the integrity of test benchmarks will be necessary to maintain trust in model performance metrics.
Conclusion
The study "Quantifying Contamination in Evaluating Code Generation Capabilities of LLMs" systematically demonstrates the impact of training data contamination on code generation benchmark evaluations. It highlights the need for more rigorous methodologies to assess model performance fairly, advocating for adjustments in testing practices to better capture genuine generalization abilities. This work serves as a critical step towards refining the evaluation of LLMs in programming contexts and ensuring their reliability across unseen and novel tasks.