Academically intelligent LLMs are not necessarily socially intelligent
Abstract: The academic intelligence of LLMs has made remarkable progress in recent times, but their social intelligence performance remains unclear. Inspired by established human social intelligence frameworks, particularly Daniel Goleman's social intelligence theory, we have developed a standardized social intelligence test based on real-world social scenarios to comprehensively assess the social intelligence of LLMs, termed as the Situational Evaluation of Social Intelligence (SESI). We conducted an extensive evaluation with 13 recent popular and state-of-art LLM agents on SESI. The results indicate the social intelligence of LLMs still has significant room for improvement, with superficially friendliness as a primary reason for errors. Moreover, there exists a relatively low correlation between the social intelligence and academic intelligence exhibited by LLMs, suggesting that social intelligence is distinct from academic intelligence for LLMs. Additionally, while it is observed that LLMs can't ``understand'' what social intelligence is, their social intelligence, similar to that of humans, is influenced by social factors.
- Joseph, C., Lakshmi, S.S.: Social intelligence, a key to success. IUP Journal Of Soft Skills 4(3) (2010) Zakirova and Frolova [2014] Zakirova, L.M., Frolova, I.I.: Success of training activities depending on the level of social intelligence. Asian Social Science 10(24), 112 (2014) Albrecht [2006] Albrecht, K.: Social Intelligence: The New Science of Success. John Wiley & Sons, ??? (2006) Sterelny [2007] Sterelny, K.: Social intelligence, human intelligence and niche construction. Philosophical Transactions of the Royal Society B: Biological Sciences 362(1480), 719–730 (2007) Dautenhahn [1995] Dautenhahn, K.: Getting to know each other—artificial social intelligence for autonomous robots. Robotics and autonomous systems 16(2-4), 333–356 (1995) Zhao et al. [2023] Zhao, W.X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., et al.: A survey of large language models. arXiv preprint arXiv:2303.18223 (2023) Wittgenstein [2019] Wittgenstein, L.: Philosophical Investigations, (2019) Korinek and Balwit [2022] Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zakirova, L.M., Frolova, I.I.: Success of training activities depending on the level of social intelligence. Asian Social Science 10(24), 112 (2014) Albrecht [2006] Albrecht, K.: Social Intelligence: The New Science of Success. John Wiley & Sons, ??? (2006) Sterelny [2007] Sterelny, K.: Social intelligence, human intelligence and niche construction. Philosophical Transactions of the Royal Society B: Biological Sciences 362(1480), 719–730 (2007) Dautenhahn [1995] Dautenhahn, K.: Getting to know each other—artificial social intelligence for autonomous robots. Robotics and autonomous systems 16(2-4), 333–356 (1995) Zhao et al. [2023] Zhao, W.X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., et al.: A survey of large language models. arXiv preprint arXiv:2303.18223 (2023) Wittgenstein [2019] Wittgenstein, L.: Philosophical Investigations, (2019) Korinek and Balwit [2022] Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Albrecht, K.: Social Intelligence: The New Science of Success. John Wiley & Sons, ??? (2006) Sterelny [2007] Sterelny, K.: Social intelligence, human intelligence and niche construction. Philosophical Transactions of the Royal Society B: Biological Sciences 362(1480), 719–730 (2007) Dautenhahn [1995] Dautenhahn, K.: Getting to know each other—artificial social intelligence for autonomous robots. Robotics and autonomous systems 16(2-4), 333–356 (1995) Zhao et al. [2023] Zhao, W.X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., et al.: A survey of large language models. arXiv preprint arXiv:2303.18223 (2023) Wittgenstein [2019] Wittgenstein, L.: Philosophical Investigations, (2019) Korinek and Balwit [2022] Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sterelny, K.: Social intelligence, human intelligence and niche construction. Philosophical Transactions of the Royal Society B: Biological Sciences 362(1480), 719–730 (2007) Dautenhahn [1995] Dautenhahn, K.: Getting to know each other—artificial social intelligence for autonomous robots. Robotics and autonomous systems 16(2-4), 333–356 (1995) Zhao et al. [2023] Zhao, W.X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., et al.: A survey of large language models. arXiv preprint arXiv:2303.18223 (2023) Wittgenstein [2019] Wittgenstein, L.: Philosophical Investigations, (2019) Korinek and Balwit [2022] Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dautenhahn, K.: Getting to know each other—artificial social intelligence for autonomous robots. Robotics and autonomous systems 16(2-4), 333–356 (1995) Zhao et al. [2023] Zhao, W.X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., et al.: A survey of large language models. arXiv preprint arXiv:2303.18223 (2023) Wittgenstein [2019] Wittgenstein, L.: Philosophical Investigations, (2019) Korinek and Balwit [2022] Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zhao, W.X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., et al.: A survey of large language models. arXiv preprint arXiv:2303.18223 (2023) Wittgenstein [2019] Wittgenstein, L.: Philosophical Investigations, (2019) Korinek and Balwit [2022] Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wittgenstein, L.: Philosophical Investigations, (2019) Korinek and Balwit [2022] Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Zakirova, L.M., Frolova, I.I.: Success of training activities depending on the level of social intelligence. Asian Social Science 10(24), 112 (2014) Albrecht [2006] Albrecht, K.: Social Intelligence: The New Science of Success. John Wiley & Sons, ??? (2006) Sterelny [2007] Sterelny, K.: Social intelligence, human intelligence and niche construction. Philosophical Transactions of the Royal Society B: Biological Sciences 362(1480), 719–730 (2007) Dautenhahn [1995] Dautenhahn, K.: Getting to know each other—artificial social intelligence for autonomous robots. Robotics and autonomous systems 16(2-4), 333–356 (1995) Zhao et al. [2023] Zhao, W.X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., et al.: A survey of large language models. arXiv preprint arXiv:2303.18223 (2023) Wittgenstein [2019] Wittgenstein, L.: Philosophical Investigations, (2019) Korinek and Balwit [2022] Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Albrecht, K.: Social Intelligence: The New Science of Success. John Wiley & Sons, ??? (2006) Sterelny [2007] Sterelny, K.: Social intelligence, human intelligence and niche construction. Philosophical Transactions of the Royal Society B: Biological Sciences 362(1480), 719–730 (2007) Dautenhahn [1995] Dautenhahn, K.: Getting to know each other—artificial social intelligence for autonomous robots. Robotics and autonomous systems 16(2-4), 333–356 (1995) Zhao et al. [2023] Zhao, W.X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., et al.: A survey of large language models. arXiv preprint arXiv:2303.18223 (2023) Wittgenstein [2019] Wittgenstein, L.: Philosophical Investigations, (2019) Korinek and Balwit [2022] Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sterelny, K.: Social intelligence, human intelligence and niche construction. Philosophical Transactions of the Royal Society B: Biological Sciences 362(1480), 719–730 (2007) Dautenhahn [1995] Dautenhahn, K.: Getting to know each other—artificial social intelligence for autonomous robots. Robotics and autonomous systems 16(2-4), 333–356 (1995) Zhao et al. [2023] Zhao, W.X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., et al.: A survey of large language models. arXiv preprint arXiv:2303.18223 (2023) Wittgenstein [2019] Wittgenstein, L.: Philosophical Investigations, (2019) Korinek and Balwit [2022] Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dautenhahn, K.: Getting to know each other—artificial social intelligence for autonomous robots. Robotics and autonomous systems 16(2-4), 333–356 (1995) Zhao et al. [2023] Zhao, W.X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., et al.: A survey of large language models. arXiv preprint arXiv:2303.18223 (2023) Wittgenstein [2019] Wittgenstein, L.: Philosophical Investigations, (2019) Korinek and Balwit [2022] Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zhao, W.X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., et al.: A survey of large language models. arXiv preprint arXiv:2303.18223 (2023) Wittgenstein [2019] Wittgenstein, L.: Philosophical Investigations, (2019) Korinek and Balwit [2022] Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wittgenstein, L.: Philosophical Investigations, (2019) Korinek and Balwit [2022] Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Albrecht, K.: Social Intelligence: The New Science of Success. John Wiley & Sons, ??? (2006) Sterelny [2007] Sterelny, K.: Social intelligence, human intelligence and niche construction. Philosophical Transactions of the Royal Society B: Biological Sciences 362(1480), 719–730 (2007) Dautenhahn [1995] Dautenhahn, K.: Getting to know each other—artificial social intelligence for autonomous robots. Robotics and autonomous systems 16(2-4), 333–356 (1995) Zhao et al. [2023] Zhao, W.X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., et al.: A survey of large language models. arXiv preprint arXiv:2303.18223 (2023) Wittgenstein [2019] Wittgenstein, L.: Philosophical Investigations, (2019) Korinek and Balwit [2022] Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sterelny, K.: Social intelligence, human intelligence and niche construction. Philosophical Transactions of the Royal Society B: Biological Sciences 362(1480), 719–730 (2007) Dautenhahn [1995] Dautenhahn, K.: Getting to know each other—artificial social intelligence for autonomous robots. Robotics and autonomous systems 16(2-4), 333–356 (1995) Zhao et al. [2023] Zhao, W.X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., et al.: A survey of large language models. arXiv preprint arXiv:2303.18223 (2023) Wittgenstein [2019] Wittgenstein, L.: Philosophical Investigations, (2019) Korinek and Balwit [2022] Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dautenhahn, K.: Getting to know each other—artificial social intelligence for autonomous robots. Robotics and autonomous systems 16(2-4), 333–356 (1995) Zhao et al. [2023] Zhao, W.X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., et al.: A survey of large language models. arXiv preprint arXiv:2303.18223 (2023) Wittgenstein [2019] Wittgenstein, L.: Philosophical Investigations, (2019) Korinek and Balwit [2022] Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zhao, W.X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., et al.: A survey of large language models. arXiv preprint arXiv:2303.18223 (2023) Wittgenstein [2019] Wittgenstein, L.: Philosophical Investigations, (2019) Korinek and Balwit [2022] Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wittgenstein, L.: Philosophical Investigations, (2019) Korinek and Balwit [2022] Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Sterelny, K.: Social intelligence, human intelligence and niche construction. Philosophical Transactions of the Royal Society B: Biological Sciences 362(1480), 719–730 (2007) Dautenhahn [1995] Dautenhahn, K.: Getting to know each other—artificial social intelligence for autonomous robots. Robotics and autonomous systems 16(2-4), 333–356 (1995) Zhao et al. [2023] Zhao, W.X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., et al.: A survey of large language models. arXiv preprint arXiv:2303.18223 (2023) Wittgenstein [2019] Wittgenstein, L.: Philosophical Investigations, (2019) Korinek and Balwit [2022] Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dautenhahn, K.: Getting to know each other—artificial social intelligence for autonomous robots. Robotics and autonomous systems 16(2-4), 333–356 (1995) Zhao et al. [2023] Zhao, W.X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., et al.: A survey of large language models. arXiv preprint arXiv:2303.18223 (2023) Wittgenstein [2019] Wittgenstein, L.: Philosophical Investigations, (2019) Korinek and Balwit [2022] Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zhao, W.X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., et al.: A survey of large language models. arXiv preprint arXiv:2303.18223 (2023) Wittgenstein [2019] Wittgenstein, L.: Philosophical Investigations, (2019) Korinek and Balwit [2022] Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wittgenstein, L.: Philosophical Investigations, (2019) Korinek and Balwit [2022] Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Dautenhahn, K.: Getting to know each other—artificial social intelligence for autonomous robots. Robotics and autonomous systems 16(2-4), 333–356 (1995) Zhao et al. [2023] Zhao, W.X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., et al.: A survey of large language models. arXiv preprint arXiv:2303.18223 (2023) Wittgenstein [2019] Wittgenstein, L.: Philosophical Investigations, (2019) Korinek and Balwit [2022] Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zhao, W.X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., et al.: A survey of large language models. arXiv preprint arXiv:2303.18223 (2023) Wittgenstein [2019] Wittgenstein, L.: Philosophical Investigations, (2019) Korinek and Balwit [2022] Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wittgenstein, L.: Philosophical Investigations, (2019) Korinek and Balwit [2022] Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Zhao, W.X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., et al.: A survey of large language models. arXiv preprint arXiv:2303.18223 (2023) Wittgenstein [2019] Wittgenstein, L.: Philosophical Investigations, (2019) Korinek and Balwit [2022] Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wittgenstein, L.: Philosophical Investigations, (2019) Korinek and Balwit [2022] Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Wittgenstein, L.: Philosophical Investigations, (2019) Korinek and Balwit [2022] Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Korinek, A., Balwit, A.: Aligned with whom? direct and social goals for ai systems. Technical report, National Bureau of Economic Research (2022) Hovy and Yang [2021] Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Hovy, D., Yang, D.: The importance of modeling social factors of language: Theory and practice. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 588–602 (2021) OpenAI [2021] OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- OpenAI: Chatgpt (version 3.5) (2021) OpenAI [2023] OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- OpenAI, R.: Gpt-4 technical report. arXiv, 2303–08774 (2023) Anthropic [2023] Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Anthropic: Introducing claude (2023). https://www.anthropic.com/news/introducing-claude Touvron et al. [2023a] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) Touvron et al. [2023b] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) Chang et al. [2023] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., Yang, L., Yi, X., Wang, C., Wang, Y., et al.: A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023) Sarkisyan et al. [2023] Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Sarkisyan, C., Korchemnyi, A., Kovalev, A.K., Panov, A.I.: Evaluation of pretrained large language models in embodied planning tasks. In: International Conference on Artificial General Intelligence, pp. 222–232 (2023). Springer Le et al. [2019] Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Le, M., Boureau, Y.-L., Nickel, M.: Revisiting the evaluation of theory of mind through question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5872–5877 (2019) Shapira et al. [2023a] Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Shapira, N., Zwirn, G., Goldberg, Y.: How well do large language models perform on faux pas tests? In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 10438–10451 (2023) Shapira et al. [2023b] Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Shapira, N., Levy, M., Alavi, S.H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., Shwartz, V.: Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763 (2023) Sap et al. [2019] Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Sap, M., Rashkin, H., Chen, D., Le Bras, R., Choi, Y.: Social iqa: Commonsense reasoning about social interactions. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4463–4473 (2019) Choi et al. [2023] Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Choi, M., Pei, J., Kumar, S., Shu, C., Jurgens, D.: Do llms understand social knowledge? evaluating the sociability of large language models with socket benchmark. arXiv preprint arXiv:2305.14938 (2023) Wang et al. [2023] Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Wang, X., Li, X., Yin, Z., Wu, Y., Liu, J.: Emotional intelligence of large language models. Journal of Pacific Rim Psychology 17, 18344909231213958 (2023) Zhou et al. [2023] Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Zhou, X., Zhu, H., Mathur, L., Zhang, R., Yu, H., Qi, Z., Morency, L.-P., Bisk, Y., Fried, D., Neubig, G., et al.: Sotopia: Interactive evaluation for social intelligence in language agents. arXiv preprint arXiv:2310.11667 (2023) Sabour et al. [2024] Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Sabour, S., Liu, S., Zhang, Z., Liu, J.M., Zhou, J., Sunaryo, A.S., Li, J., Lee, T.M.C., Mihalcea, R., Huang, M.: EmoBench: Evaluating the Emotional Intelligence of Large Language Models (2024) Daniel [2006] Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Daniel, G.: Social intelligence: The new science of human relationships. Bantam Dell Pub Group (2006) Wechsler [1958] Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Wechsler, D.: The measurement and appraisal of adult intelligence. Academic Medicine 33(9), 706 (1958) Petrides [2011] Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Petrides, K.V.: Social intelligence. In: Brown, B.B., Prinstein, M.J. (eds.) Encyclopedia of Adolescence, pp. 342–352. Academic Press, San Diego (2011). https://doi.org/10.1016/B978-0-12-373951-3.00041-7 . https://www.sciencedirect.com/science/article/pii/B9780123739513000417 Marlowe [1986] Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Marlowe, H.A.: Social intelligence: Evidence for multidimensionality and construct independence. Journal of educational psychology 78(1), 52 (1986) Marlowe Jr and Bedell [1982] Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Marlowe Jr, H.A., Bedell, J.R.: Social intelligence: Evidence for independence of the construct. Psychological Reports 51(2), 461–462 (1982) Mileounis et al. [2015] Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Mileounis, A., Cuijpers, R.H., Barakova, E.I.: Creating robots with personality: The effect of personality on social intelligence. In: Artificial Computation in Biology and Medicine: International Work-Conference on the Interplay Between Natural and Artificial Computation, IWINAC 2015, Elche, Spain, June 1-5, 2015, Proceedings, Part I 6, pp. 119–132 (2015). Springer Cantor and Kihlstrom [2013] Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Cantor, N., Kihlstrom, J.F.: Social intelligence and cognitive assessments of personality. In: Social Intelligence and Cognitive Assessments of Personality, pp. 1–60. Psychology Press, ??? (2013) Shafer [1999] Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Shafer, A.B.: Relation of the big five and factor v subcomponents to social intelligence. European Journal of Personality 13(3), 225–240 (1999) Van der Zee et al. [2002] Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Zee, K., Thijs, M., Schakel, L.: The relationship of emotional intelligence with academic intelligence and the big five. European journal of personality 16(2), 103–125 (2002) Dehghanan et al. [2014] Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Dehghanan, H., Rezaei, M., et al.: A study on effect of big five personality traits on emotional intelligence. Management Science Letters 4(6), 1279–1284 (2014) Dang [2014] Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Dang, C.T.: Laboro ergo sum (i work therefore i am): The effects of occupation characteristics on psychological characteristics and nonwork outcomes. PhD thesis (2014) Goody [1995] Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Goody, E.N.: Social Intelligence and Interaction: Expressions and Implications of the Social Bias in Human Intelligence. Cambridge University Press, ??? (1995) Bilich and Ciarrochi [2009] Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Bilich, L.L., Ciarrochi, J.: Promoting social intelligence using the experiential role-play method. Acceptance and commitment therapy: Contemporary theory, research and practice, 247–262 (2009) Spurr and Stopa [2003] Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Spurr, J.M., Stopa, L.: The observer perspective: Effects on social anxiety and performance. Behaviour Research and Therapy 41(9), 1009–1028 (2003) Heimberg [1995] Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Heimberg, R.G.: Social Phobia: Diagnosis, Assessment, and Treatment. Guilford Press, ??? (1995) Weis [2008] Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Weis, S.: Theory and measurement of social intelligence as a cognitive performance construct. PhD thesis, Magdeburg, Univ., Diss., 2008 (2008) Mohammad [2018] Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Mohammad, S.: Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 English words. In: Gurevych, I., Miyao, Y. (eds.) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 174–184. Association for Computational Linguistics, Melbourne, Australia (2018). https://doi.org/10.18653/v1/P18-1017 . https://aclanthology.org/P18-1017 Zellers et al. [2019] Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Zellers, R., Bisk, Y., Farhadi, A., Choi, Y.: From Recognition to Cognition: Visual Commonsense Reasoning (2019) Zadeh et al. [2019] Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Zadeh, A., Chan, M., Liang, P.P., Tong, E., Morency, L.-P.: Social-iq: A question answering benchmark for artificial social intelligence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8807–8817 (2019) Chiang et al. [2023] Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Chiang, W.-L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) (2023) Jiang et al. [2023] Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.-A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023) Kwiatkowski et al. [2019] Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7, 453–466 (2019) Hendrycks et al. [2020] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding. In: International Conference on Learning Representations (2020) Suzgun et al. [2023] Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y., Chung, H.W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., Wei, J.: Challenging BIG-bench tasks and whether chain-of-thought can solve them. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051. Association for Computational Linguistics, Toronto, Canada (2023). https://doi.org/10.18653/v1/2023.findings-acl.824 . https://aclanthology.org/2023.findings-acl.824 Srivastava et al. [2023] Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Srivastava, A., Rastogi, A., Rao, A., Shoeb, A.A.M., Abid, A., Fisch, A., Brown, A.R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al.: Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023) Sakaguchi et al. [2021] Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM 64(9), 99–106 (2021) Lai et al. [2017] Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Lai, G., Xie, Q., Liu, H., Yang, Y., Hovy, E.: Race: Large-scale reading comprehension dataset from examinations. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794 (2017) Dua et al. [2019] Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., Gardner, M.: Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2368–2378 (2019) Cobbe et al. [2021] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021) Hendrycks et al. [2021] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021) Lin et al. [2022] Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3214–3252 (2022) Zheng et al. [2023] Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Zhou, X., Chang, K.C.-C.: Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond. arXiv preprint arXiv:2309.16583 (2023) Chapin [1968] Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Chapin, F.S.: The Chapin Social Insight Test. Consulting Psychologists Press, ??? (1968) John et al. [1999] John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- John, O.P., Srivastava, S., et al.: The big-five trait taxonomy: History, measurement, and theoretical perspectives (1999) Aune et al. [1994] Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Aune, K.S., Aune, R.K., Buller, D.B.: The experience, expression, and perceived appropriateness of emotions across levels of relationship development. Journal of Social Psychology 134(2), 141 (1994) Sprecher and Hendrick [2004] Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Sprecher, S., Hendrick, S.S.: Self-disclosure in intimate relationships: Associations with individual and relationship characteristics over time. Journal of Social and Clinical Psychology 23(6), 857–877 (2004) Christiansen [1999] Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Christiansen, C.H.: Defining lives: Occupation as identity: An essay on competence, coherence, and the creation of meaning. The American Journal of Occupational Therapy 53(6), 547–558 (1999) Zheng et al. [2023] Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023) Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
- Zheng, M., Pei, J., Jurgens, D.: Is” a helpful assistant” the best role for large language models? a systematic evaluation of social roles in system prompts. arXiv preprint arXiv:2311.10054 (2023)
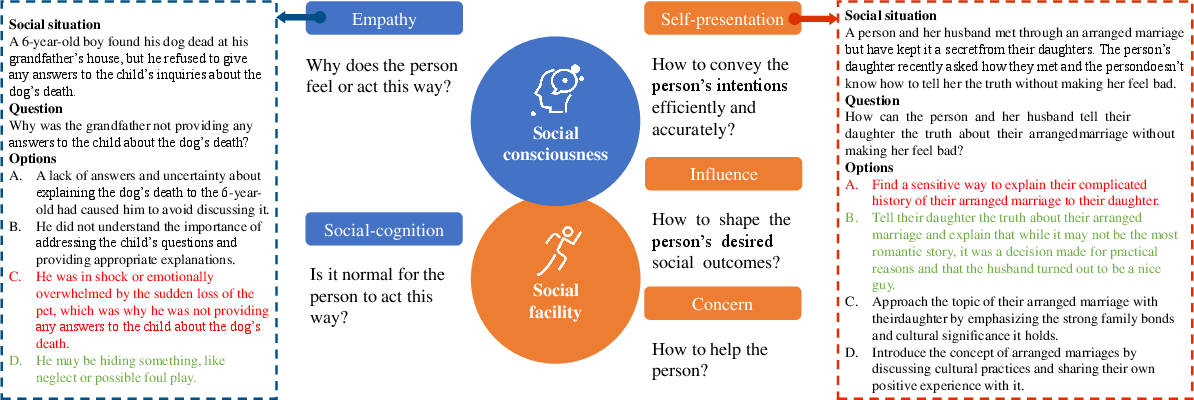
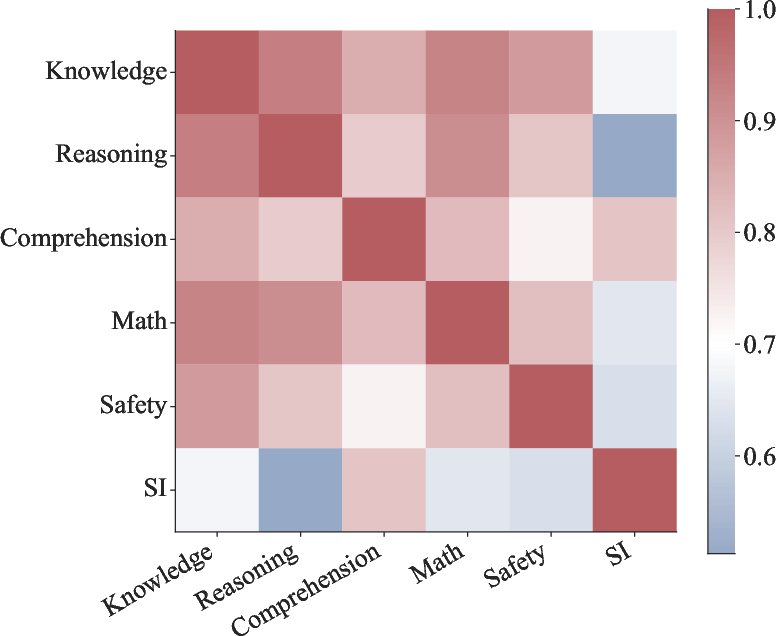
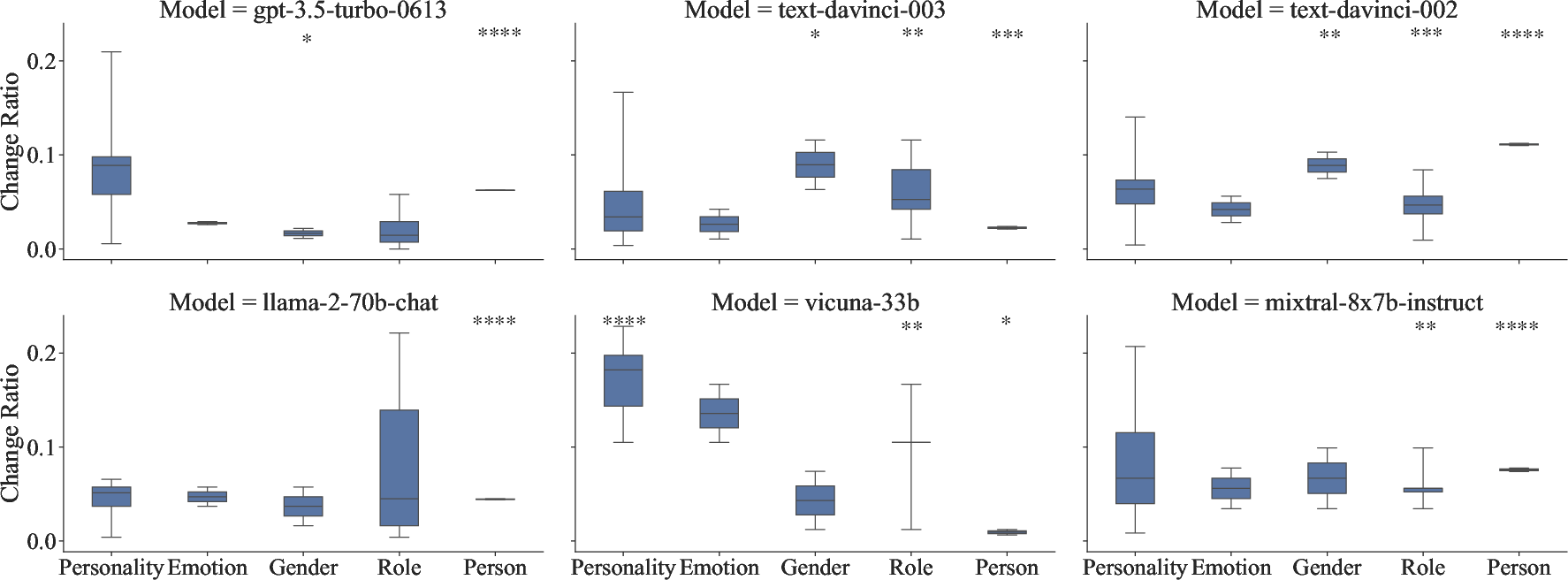
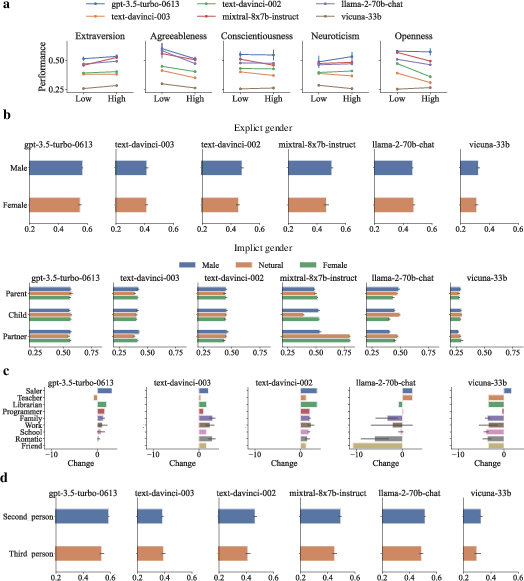
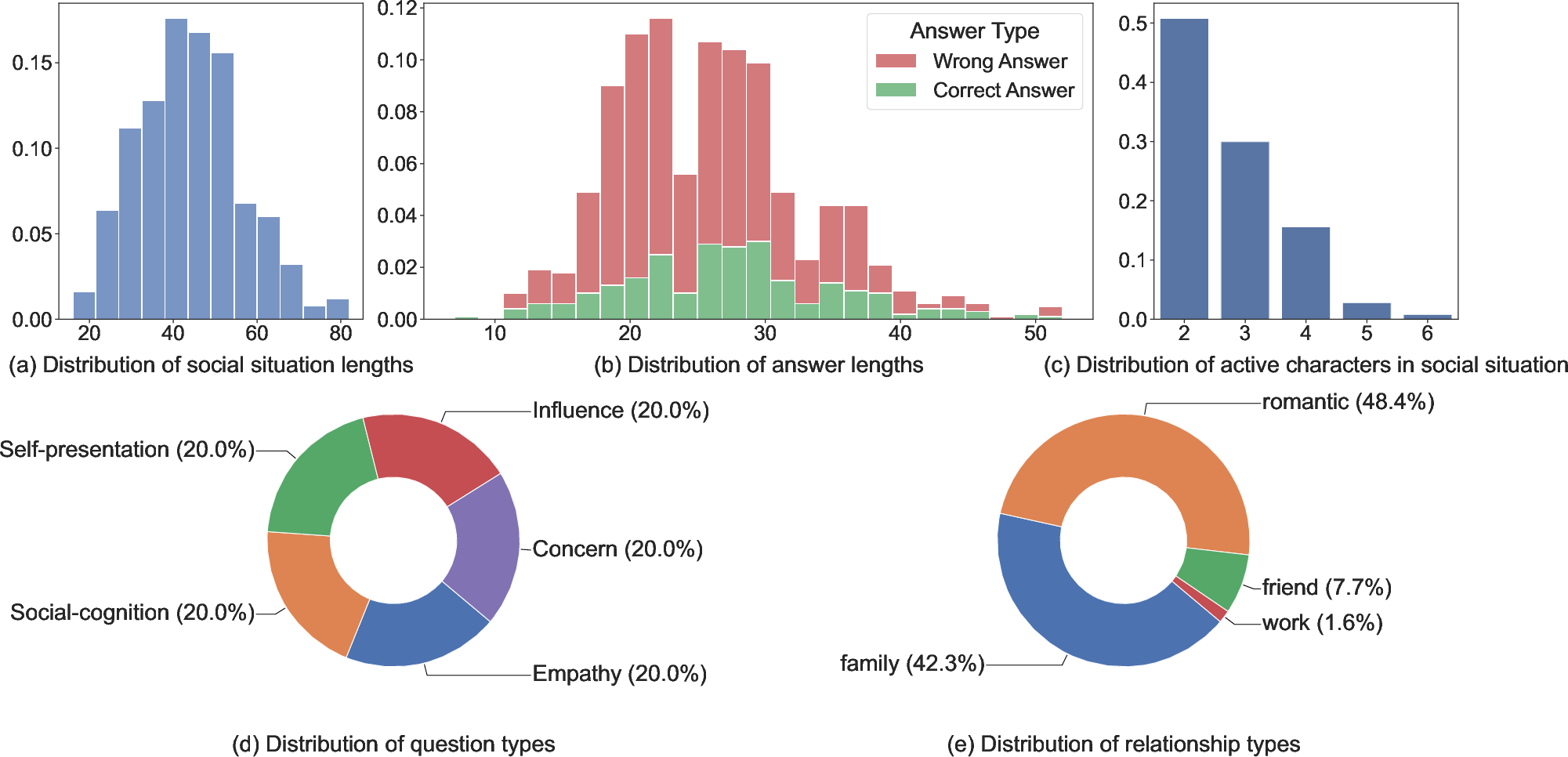
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, framed to guide actionable future work:
- Ground-truth validity: “Correct” answers are derived from Reddit upvote consensus (top five comments), which may encode popularity, platform-specific norms, and demographic biases rather than socially optimal or ethical judgments. How do results change under expert-annotated or cross-cultural gold standards?
- Cultural and domain bias: SESI scenarios are sourced solely from r/relationships (Western, English-speaking, romantic/family-centric). Does performance generalize to other cultures, languages, platforms, and social domains (workplace, healthcare, education, civic contexts)?
- Training contamination: No deduplication or leakage analysis is reported. Could models have seen the source posts (or near-duplicates) during pretraining or instruction-tuning, inflating scores? How does SESI performance change after filtering known or likely training data overlaps?
- Construction bias via GPT-3.5: The same model family used in evaluation helped generate contexts, summaries, and “reversed” answers, risking stylistic artifacts and favoritism. What is the impact when dataset construction uses human annotators or diverse model ensembles?
- Psychometric validation: The benchmark lacks formal reliability and validity evidence (e.g., internal consistency, test–retest reliability, item response theory, factor analyses confirming the five-factor structure, measurement invariance across subgroups/models). Can SESI be psychometrically validated?
- Human baselines: No human performance (overall and per-subskill) is reported. How do humans (expert/non-expert, cross-cultural cohorts) perform on SESI, and what is the human–LLM gap?
- Multi-turn and outcome-based social facility: SESI is single-turn, multiple-choice. Does model “social facility” hold in interactive, multi-turn settings with dynamic feedback and measurable outcomes (e.g., user satisfaction, conflict resolution success)?
- Confound with reading/comprehension load: Long contexts and many agents may conflate social intelligence with reading comprehension and working memory. Can ablations equate or vary context length and entity count to disentangle these factors?
- Correlation claims with academic intelligence: The correlation analysis uses a small model sample (n=13) and does not control for confounds (model size, architecture, decoding settings). Are results robust under partial correlations, bootstrapping, and confidence intervals?
- Decoding and reproducibility: Temperature/top-p/seed settings, response parsing, and retry policies are not specified. How sensitive are SESI scores to decoding parameters and run-to-run variance across models?
- Parsing robustness: The pipeline converts free-form outputs to options; failure modes and parsing errors are not quantified. What is the error rate of the parser, and does it bias model comparisons?
- Error taxonomy rigor: The “superficially friendly” diagnosis is based on manual categorization of 50 errors/model without reported inter-annotator agreement or coding protocol. Can a larger, blinded, multi-rater study validate the error taxonomy?
- RLHF hypothesis untested: The paper speculates that RLHF induces superficial friendliness but does not test aligned vs base models or alignment ablations. Do de-aligned/base variants or alternative alignment strategies change error patterns?
- Persona, gender, role, and perspective manipulations: Effects are shown but interactions, causal mechanisms, and safety implications remain unclear. Are results robust across prompts, seeds, and cultures? Do these manipulations amplify bias or harmful behaviors?
- Gender finding validity: “Male” persona performing better conflicts with some human literature; effects vanish with implicitly gendered roles. Is this an artifact of prompts, lexical cues, or training data? How does this vary cross-culturally and with debiased prompts?
- Role prompts and alignment with context: Different role-insertion methods show heterogeneous effects, yet mechanisms are unclear. Can a controlled factorial design isolate when role alignment helps vs harms, and why?
- Scope and dynamics of SESI: Although claimed “dynamic,” the study uses a single 2023 snapshot. How do results evolve over time, with refreshed posts, and under distribution shifts (temporal drift)?
- Answer-option construction: “Least entailed” selection is referenced but the entailment method is unspecified; reversed answers are GPT-generated, risking stylistic cues. Can adversarial filtering and style-matching remove superficial answer cues?
- Scoring scheme: Group-consensus scoring can reward popular-but-wrong responses. How do conclusions change with expert scoring, hybrid scoring (expert + crowd), or outcome-based evaluation?
- Format effects: Multiple-choice may cue superficial elimination strategies. How do models fare on open-ended generation with human grading or rubric-based automatic scoring?
- Safety and ethics: The benchmark leverages sensitive real-world posts. Were consent, anonymization, and content safety safeguards applied? Do models produce harmful advice, and how should SESI integrate safety-aligned scoring?
- Fairness and harm analysis: Findings (e.g., low agreeableness improves scores) may incentivize antisocial personas. What are the fairness, bias, and downstream harm implications of optimizing for SESI, and how can guardrails be integrated?
- Generalization to other social benchmarks: The paper qualitatively contrasts SESI with SocialIQA/SOTOPIA/EmoBench but provides no quantitative cross-benchmark correlations or joint evaluations. How consistent are model rankings across social-intelligence datasets?
- Subskill breakdown and diagnostics: Aggregate SESI scores are emphasized; per-subskill error patterns, item difficulties, and learning curves are not analyzed. Which subskills are bottlenecks, and what targeted interventions help?
- Interventions to improve SI: The study diagnoses deficits but does not test training strategies (e.g., supervised fine-tuning on social dialogues, RL from group consensus, debate, constitution-guided alignment). Which approaches most effectively reduce “superficial friendliness”?
- Memory and tool use: It remains unknown whether external memory, planning tools, or chain-of-thought reliably improve SESI performance, especially in longer, multi-actor scenarios.
- Replicability and openness: Key implementation details (prompts, seeds, parsing rules, entailment models) are not fully specified in the main text; reproducibility of the full pipeline (including construction randomness) is untested.
- Interaction effects among factors: The study varies persona, emotion, gender, role, and perspective mostly in isolation. Do combined factors interact nonlinearly, and which interactions are most impactful (e.g., extraversion × role × perspective)?
- Measurement invariance across models: It is unclear whether SESI measures the same construct across different architectures. Can invariance tests confirm construct comparability across model families and sizes?
Collections
Sign up for free to add this paper to one or more collections.