- The paper introduces CT2Rep, a framework employing an auto-regressive causal transformer for generating radiology reports from 3D chest CT images.
- It integrates a 3D vision feature extractor with transformer modules enhanced by relational memory and MCLN to capture complex spatial features.
- CT2RepLong extends the approach by incorporating longitudinal multimodal data using cross-attention to boost report accuracy and contextual detail.
Automated Radiology Report Generation for 3D Medical Imaging
The paper "CT2Rep: Automated Radiology Report Generation for 3D Medical Imaging" (2403.06801) introduces a novel approach to automate the generation of radiology reports for 3D medical imaging, specifically chest CT volumes. The method addresses the existing gap in the field, as current report generation techniques are primarily focused on 2D medical images due to the computational complexity and data scarcity associated with 3D data. The paper presents two main contributions: CT2Rep, a framework employing a new auto-regressive causal transformer for 3D medical imaging report generation, and CT2RepLong, an extension that incorporates longitudinal data to enhance the accuracy and context of the generated reports.
Methodological Innovations of CT2Rep
CT2Rep consists of three primary components: a 3D vision feature extractor, a transformer encoder, and a transformer decoder. The 3D vision feature extractor, Φencvisual, segments the 3D chest CT volumes into distinct patches and transforms them into a lower-dimensional latent space, effectively capturing essential information from the volumetric data.
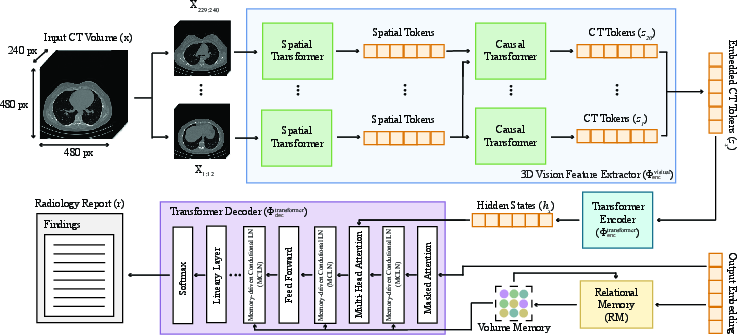
Figure 1: CT2Rep features a novel auto-regressive causal transformer for 3D vision feature extraction, complemented by RM and MCLN-enhanced transformer-based encoder and decoder network for clinically accurate report generation.
The transformer encoder, Φenctransformer, encodes the extracted CT features using an attention mechanism to capture feature interdependencies. The transformer decoder, Φdectransformer, is enhanced with relational memory (RM) and memory-driven conditional layer normalization (MCLN) to refine pattern information across generation steps and make the model more contextually aware. The inference process of CT2Rep, denoted as rout=ΦCT2Rep(x)=Φdectransformer(Φenctransformer(Φencvisual(x))), generates a radiology report (rout) for a given 3D chest CT volume (x).
Longitudinal Data Integration in CT2RepLong
To leverage information from previous visits, the authors extended CT2Rep to incorporate longitudinal multimodal data, resulting in CT2RepLong. This extension includes a cross-attention-based fusion module that integrates representations from previous CT volumes and their corresponding reports. The fusion process involves computing cross-attention between previous volume and report representations, enhancing the performance of the longitudinal framework, ΦCT2RepLong.
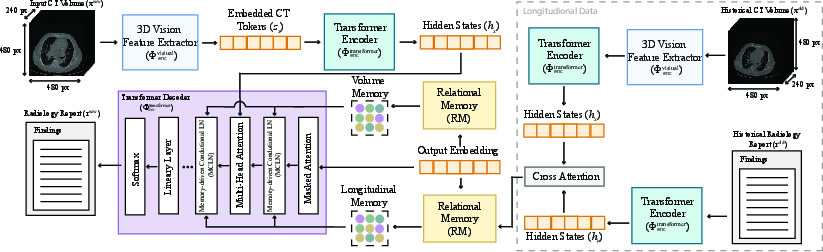
Figure 2: CT2RepLong enhances CT2Rep with a cross-attention multi-modal fusion module and longitudinal memory for effective historical data integration.
The multimodal transformer decoder in CT2RepLong employs two additional cross-attention mechanisms, Φlongattn, to analyze the relationships between previous reports and volumes, and vice versa. The resulting cross-attention outputs are then utilized in MCLN, formalized as:
rTout=Φdectransformer(h1,...,hN,MCLN(Φmemattn(RM(r1out,...,rT−1out),Φlongattn(rold,xold)))).
The inference process for CT2RepLong is defined as:
routnew=ΦCT2RepLong(xnew,xold,rold) =Φdectransformer(Φenctransformer(Φencvisual(xnew)),Φlongattn(rold,xold)).
Experimental Evaluation and Results
The models were trained using a dataset of 25,701 non-contrast 3D chest CT volumes from 21,314 unique patients. The dataset was divided into training and validation sets, and the radiology reports were segmented into clinical information, technique, findings, and impression sections, with only the findings section used for training.
To evaluate the model's efficacy, the authors used natural language generation (NLG) metrics, including BLEU, METEOR, and ROUGE-L, as well as clinical efficacy (CE) metrics. For CE metrics, the CXR-Bert model was fine-tuned for multi-label classification of reports on 18 abnormalities, and classification scores, including precision, recall, and F1 score, were computed to measure the clinical accuracy of the generated reports.
Given the absence of directly comparable methods, the authors established a baseline using CT-Net, a state-of-the-art vision encoder used in 3D medical imaging. CT2Rep outperformed this baseline, demonstrating the effectiveness of the proposed auto-regressive causal transformer.

Figure 3: Comparison of ground-truth with reports generated by a CT-Net-based baseline and CT2Rep, highlighting CT2Rep's medical precision with color codes.
An ablation study was conducted to evaluate the impact of incorporating prior data in CT2RepLong. The results demonstrated the advantages of prior multimodal data and the unique cross-attention mechanism. Despite the limited size of the longitudinal data, CT2RepLong's performance was comparable to the original CT2Rep, highlighting its effectiveness even with a constrained dataset.
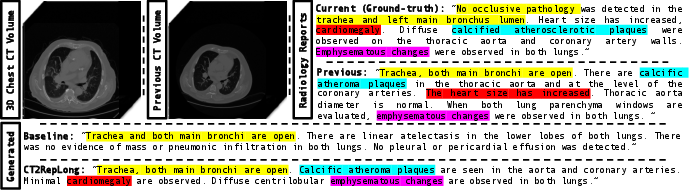
Figure 4: CT2RepLong surpasses the baseline, leveraging longitudinal data for enhanced medical detail accuracy, with related terms color-coded for clarity.
Implementation Details
CT2Rep and the baseline method were trained on 49,138 3D CT volumes and their corresponding reports. The Adam optimizer was used with specific hyperparameters, and a StepLR scheduler was employed. CT2RepLong and the ablation methods were trained on 28,441 pairs, utilizing the same hyperparameters as CT2Rep. The training duration for all models was one week on a single NVIDIA A100 GPU, achieving 20 epochs.
Conclusion
The paper presents CT2Rep, a framework for automated radiology report generation for 3D medical imaging, specifically chest CT volumes. The framework leverages an innovative auto-regressive causal transformer architecture and integrates relational memory to enhance accuracy in report generation. The authors establish a benchmark using a state-of-the-art vision encoder in 3D chest CT volume interpretation to showcase CT2Rep's effectiveness. Additionally, the extension of the framework with longitudinal data integration, resulting in CT2RepLong, further enhances the context and accuracy of the generated reports.