Chronos: Learning the Language of Time Series
Abstract: We introduce Chronos, a simple yet effective framework for pretrained probabilistic time series models. Chronos tokenizes time series values using scaling and quantization into a fixed vocabulary and trains existing transformer-based LLM architectures on these tokenized time series via the cross-entropy loss. We pretrained Chronos models based on the T5 family (ranging from 20M to 710M parameters) on a large collection of publicly available datasets, complemented by a synthetic dataset that we generated via Gaussian processes to improve generalization. In a comprehensive benchmark consisting of 42 datasets, and comprising both classical local models and deep learning methods, we show that Chronos models: (a) significantly outperform other methods on datasets that were part of the training corpus; and (b) have comparable and occasionally superior zero-shot performance on new datasets, relative to methods that were trained specifically on them. Our results demonstrate that Chronos models can leverage time series data from diverse domains to improve zero-shot accuracy on unseen forecasting tasks, positioning pretrained models as a viable tool to greatly simplify forecasting pipelines.
- GluonTS: Probabilistic and Neural Time Series Modeling in Python. The Journal of Machine Learning Research, 21(1):4629–4634, 2020.
- Deep Explicit Duration Switching Models for Time Series. Advances in Neural Information Processing Systems, 34, 2021.
- V. Assimakopoulos and K. Nikolopoulos. The theta model: a decomposition approach to forecasting. International Journal of Forecasting, 16(4):521–530, 2000.
- The tourism forecasting competition. International Journal of Forecasting, 27(3):822–844, 2011.
- Deep learning for time series forecasting: Tutorial and literature survey. ACM Comput. Surv., 55(6), 2022.
- Language models are few-shot learners. In Advances in Neural Information Processing Systems, 2020.
- Neural Contextual Anomaly Detection for Time Series. arXiv:2107.07702, 2021.
- N-HiTS: Neural Hierarchical Interpolation for Time Series Forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, 2023.
- PaLM: Scaling Language Modeling with Pathways. Journal of Machine Learning Research, 24(240):1–113, 2023.
- Scaling Instruction-Finetuned Language Models. arXiv:2210.11416, 2022.
- Tri Dao. FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning. arXiv:2307.08691, 2023.
- A decoder-only foundation model for time-series forecasting. arXiv:2310.10688, 2023.
- The UCR Time Series Classification Archive, October 2018. https://www.cs.ucr.edu/~eamonn/time_series_data_2018/.
- LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale. arXiv:2208.07339, 2022.
- SimMTM: A Simple Pre-Training Framework for Masked Time-Series Modeling. arXiv:2302.00861, 2023.
- ForecastPFN: Synthetically-Trained Zero-Shot Forecasting. In Advances in Neural Information Processing Systems, 2023.
- Structure Discovery in Nonparametric Regression through Compositional Kernel Search. In International Conference on Machine Learning, pp. 1166–1174. PMLR, 2013.
- BuildingsBench: A Large-Scale Dataset of 900K Buildings and Benchmark for Short-Term Load Forecasting. arXiv:2307.00142, 2023.
- Hierarchical Neural Story Generation. arXiv:1805.04833, 2018.
- How not to lie with statistics: the correct way to summarize benchmark results. Communications of the ACM, 29(3):218–221, 1986.
- Beam Search Strategies for Neural Machine Translation. arXiv:1702.01806, 2017.
- Breaking the Sequential Dependency of LLM Inference Using Lookahead Decoding, November 2023. URL https://lmsys.org/blog/2023-11-21-lookahead-decoding/.
- The Pile: An 800GB Dataset of Diverse Text for Language Modeling. arXiv:2101.00027, 2020.
- StatsForecast: Lightning fast forecasting with statistical and econometric models. PyCon Salt Lake City, Utah, US 2022, 2022. URL https://github.com/Nixtla/statsforecast.
- Probabilistic Forecasting with Spline Quantile Function RNNs. In Proceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics, volume 89 of Proceedings of Machine Learning Research, pp. 1901–1910. PMLR, 2019.
- Strictly proper scoring rules, prediction, and estimation. Journal of the American statistical Association, 102(477):359–378, 2007.
- Monash Time Series Forecasting Archive. In Neural Information Processing Systems Track on Datasets and Benchmarks, 2021.
- Moment: A family of open time-series foundation models. arXiv preprint arXiv:2402.03885, 2024.
- Large Language Models Are Zero-Shot Time Series Forecasters. In Advances in Neural Information Processing Systems, 2023.
- The curious case of neural text degeneration. arXiv:1904.09751, 2019.
- LoRA: Low-rank adaptation of large language models. arXiv:2106.09685, 2021.
- Forecasting with exponential smoothing: the state space approach. Springer Science & Business Media, 2008.
- Forecasting: principles and practice. OTexts, 2018.
- Another look at measures of forecast accuracy. International journal of forecasting, 22(4):679–688, 2006.
- Deep learning for time series classification: a review. Data mining and knowledge discovery, 33(4):917–963, 2019.
- Time-LLM: Time series forecasting by reprogramming large language models. In The Twelfth International Conference on Learning Representations, 2024.
- Domain adaptation for time series forecasting via attention sharing. In International Conference on Machine Learning, pp. 10280–10297. PMLR, 2022.
- LightGBM: A Highly Efficient Gradient Boosting Decision Tree. Advances in neural information processing systems, 30, 2017.
- Quantile regression. Journal of economic perspectives, 15(4):143–156, 2001.
- A classification of business forecasting problems. Foresight, 52, 2019.
- Predict, Refine, Synthesize: Self-Guiding Diffusion Models for Probabilistic Time Series Forecasting. In Advances in Neural Information Processing Systems, volume 36, pp. 28341–28364. Curran Associates, Inc., 2023.
- Fast inference from transformers via speculative decoding. In International Conference on Machine Learning, pp. 19274–19286. PMLR, 2023.
- BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. arXiv:1910.13461, 2019.
- Temporal fusion transformers for interpretable multi-horizon time series forecasting. International Journal of Forecasting, 37(4):1748–1764, 2021.
- Largest: A benchmark dataset for large-scale traffic forecasting. arXiv:2306.08259, 2023.
- The M3-Competition: results, conclusions and implications. International journal of forecasting, 16(4):451–476, 2000.
- Accuracy of forecasting: An empirical investigation. Journal of the Royal Statistical Society. Series A (General), 142(2):97–145, 1979.
- The M4 Competition: 100,000 time series and 61 forecasting methods. International Journal of Forecasting, 36(1):54–74, 2020.
- M5 accuracy competition: Results, findings, and conclusions. International Journal of Forecasting, 38(4):1346–1364, 2022.
- Pointer sentinel mixture models. arXiv:1609.07843, 2016.
- Large language models as general pattern machines. In Proceedings of The 7th Conference on Robot Learning, volume 229 of Proceedings of Machine Learning Research, pp. 2498–2518. PMLR, 2023.
- A time series is worth 64 words: Long-term forecasting with transformers. In International Conference on Learning Representations, 2023.
- NeuralForecast: User friendly state-of-the-art neural forecasting models. PyCon Salt Lake City, Utah, US 2022, 2022. URL https://github.com/Nixtla/neuralforecast.
- Wavenet: A generative model for raw audio. arXiv:1609.03499, 2016.
- N-BEATS: Neural basis expansion analysis for interpretable time series forecasting. In International Conference on Learning Representations, 2020.
- Meta-learning framework with applications to zero-shot time-series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2021.
- Zero-shot and few-shot time series forecasting with ordinal regression recurrent neural networks. In 28th European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, pp. 503–508, 2020.
- The effectiveness of discretization in forecasting: An empirical study on neural time series models. arXiv:2005.10111, 2020.
- Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1):5485–5551, 2020.
- Integrating multimodal information in large pretrained transformers. In Proceedings of the conference. Association for Computational Linguistics. Meeting, volume 2020, pp. 2359. NIH Public Access, 2020.
- Deep state space models for time series forecasting. Advances in neural information processing systems, 31, 2018.
- Autoregressive denoising diffusion models for multivariate probabilistic time series forecasting. In International Conference on Machine Learning, pp. 8857–8868. PMLR, 2021.
- Lag-llama: Towards foundation models for time series forecasting, 2023.
- Conformalized quantile regression. Advances in neural information processing systems, 32, 2019.
- Deepar: Probabilistic forecasting with autoregressive recurrent networks. International Journal of Forecasting, 36(3):1181–1191, 2020.
- Neural machine translation of rare words with subword units. arXiv:1508.07909, 2015.
- Autogluon–timeseries: Automl for probabilistic time series forecasting. In International Conference on Automated Machine Learning, pp. 9–1. PMLR, 2023.
- Conformal time-series forecasting. Advances in neural information processing systems, 34:6216–6228, 2021.
- A length-extrapolatable transformer. arXiv:2212.10554, 2022.
- Rethinking the inception architecture for computer vision, 2015.
- Scale efficiently: Insights from pre-training and fine-tuning transformers. arXiv:2109.10686, 2021.
- Stacking bagged and dagged models. In Proceedings of the Fourteenth International Conference on Machine Learning, 1997.
- Regression using Classification Algorithms. Intelligent Data Analysis, 1(4):275–292, 1997.
- Llama 2: Open Foundation and Fine-Tuned Chat Models, 2023.
- Attention Is All You Need. In Advances in Neural Information Processing Systems, 2017.
- A Multi-Horizon Quantile Recurrent Forecaster. arXiv:1711.11053, 2017.
- Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pp. 38–45. Association for Computational Linguistics, 2020.
- Unified training of universal time series forecasting transformers. arXiv:2402.02592, 2024.
- TimesNet: Temporal 2D-Variation Modeling for General Time Series Analysis. In International Conference on Learning Representations, 2023.
- Current Time Series Anomaly Detection Benchmarks are Flawed and are Creating the Illusion of Progress. IEEE Transactions on Knowledge and Data Engineering, 2021.
- Conformal Prediction Interval for Dynamic Time-Series. In International Conference on Machine Learning, pp. 11559–11569. PMLR, 2021.
- PromptCast: A New Prompt-based Learning Paradigm for Time Series Forecasting. arXiv:2210.08964, 2023.
- A novel transfer learning framework for time series forecasting. Knowledge-Based Systems, 156:74–99, 2018.
- Are Transformers Effective for Time Series Forecasting? In Proceedings of the AAAI conference on artificial intelligence, volume 37, 2023.
- mixup: Beyond Empirical Risk Minimization. arXiv:1710.09412, 2017.
- Adaptive budget allocation for parameter-efficient fine-tuning. arXiv:2303.10512, 2023.
- A survey of large language models. arXiv:2303.18223, 2023.
- Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting. In The Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Virtual Conference, volume 35, pp. 11106–11115. AAAI Press, 2021.
- One Fits All: Power general time series analysis by pretrained LM. In Advances in Neural Information Processing Systems, 2023a.
- Improving time series forecasting with mixup data augmentation. In ECML PKDD 2023 International Workshop on Machine Learning for Irregular Time Series, 2023b.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Brief Overview
This paper introduces Chronos, a new way to forecast time series (data that changes over time, like daily temperatures or sales). The key idea is to treat numbers in a time series like words in a sentence so that a LLM (the kind of AI used for text) can learn to “read” time series and predict what comes next.
Key Objectives and Questions
The paper asks and answers a few simple questions:
- Can we teach a LLM to understand time series by turning the numbers into “tokens” (like words)?
- If we do this, will the model make good predictions for both familiar datasets and brand-new ones without extra training (zero-shot)?
- Can simple, widely available LLM architectures work well without special time-series tricks?
- Can we boost performance by creating extra training examples through clever data mixing and realistic synthetic data?
How Chronos Works (Methods and Approach)
Think of a time series as a line of numbers over time. Chronos changes how the model sees those numbers so it can use the same tools that work for language. Here’s the approach:
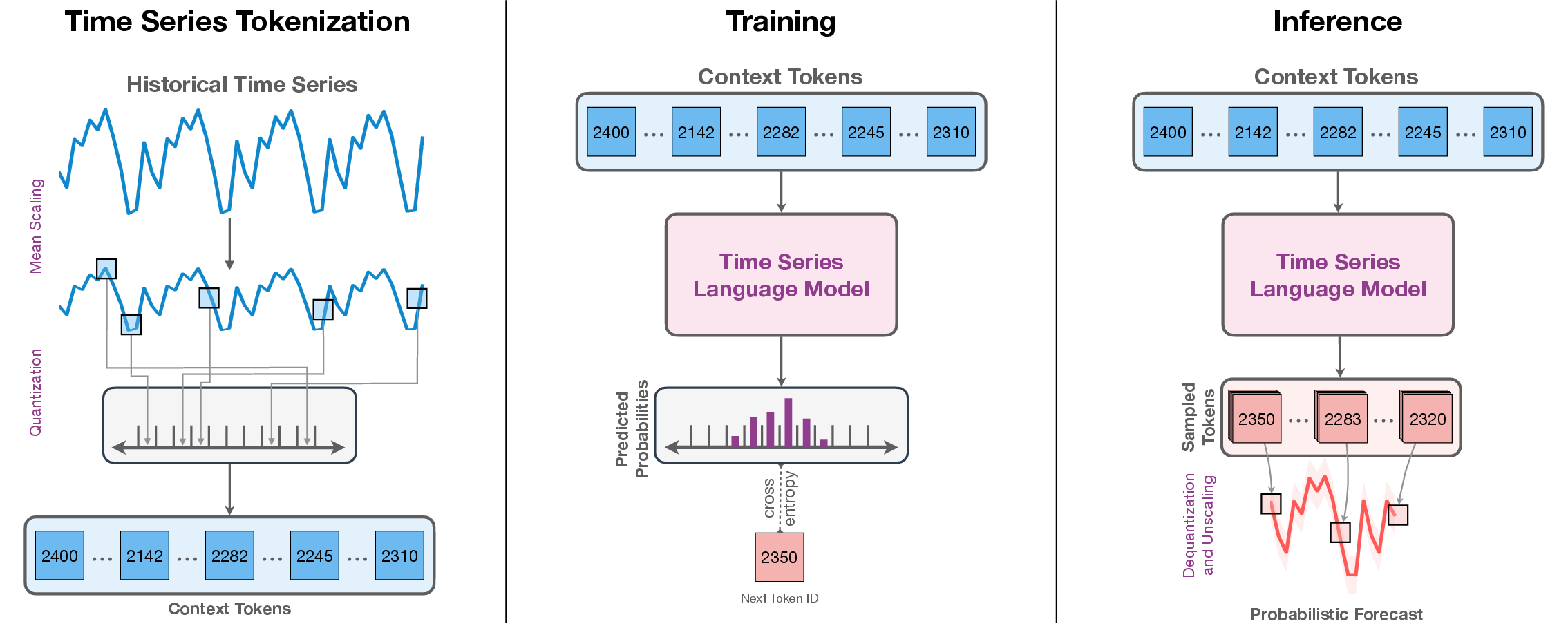
- Turning numbers into tokens:
- Scaling: First, Chronos adjusts each series to a similar size, like resizing photos so they’re easier to compare. They divide each value by the average size of past values. This helps the model learn patterns without being confused by big or small scales.
- Quantization: Then, Chronos puts each scaled number into one of many “buckets” (bins). Imagine sorting scores into ranges: 0–1, 1–2, 2–3, etc. Each bucket gets an ID, which becomes a token. This is like turning numbers into “words” from a fixed vocabulary.
- Vocabulary: In addition to number tokens, Chronos uses special tokens like PAD (for missing/padding) and EOS (end of sequence), just like LLMs do.
- The model:
- Chronos trains existing transformer-based LLMs (mainly T5 variants from 20M to 710M parameters). Transformers are powerful AI models that learn patterns in sequences, whether text or, in this case, time series tokens.
- No fancy time-series-specific architecture is added. The only change is the size of the input/output vocabulary to match the number of bins.
- Training:
- Loss: Chronos uses cross-entropy loss, a standard way to train LLMs by making the predicted token distribution match the true token.
- Data: They gather lots of public time series from different fields (energy, retail, health, weather, finance, etc.). Because good public time-series data is limited, they add:
- TSMixup: Mix several real time series together (like blending songs) to create new patterns. They pick 1–3 series and combine them with random weights to make training more varied.
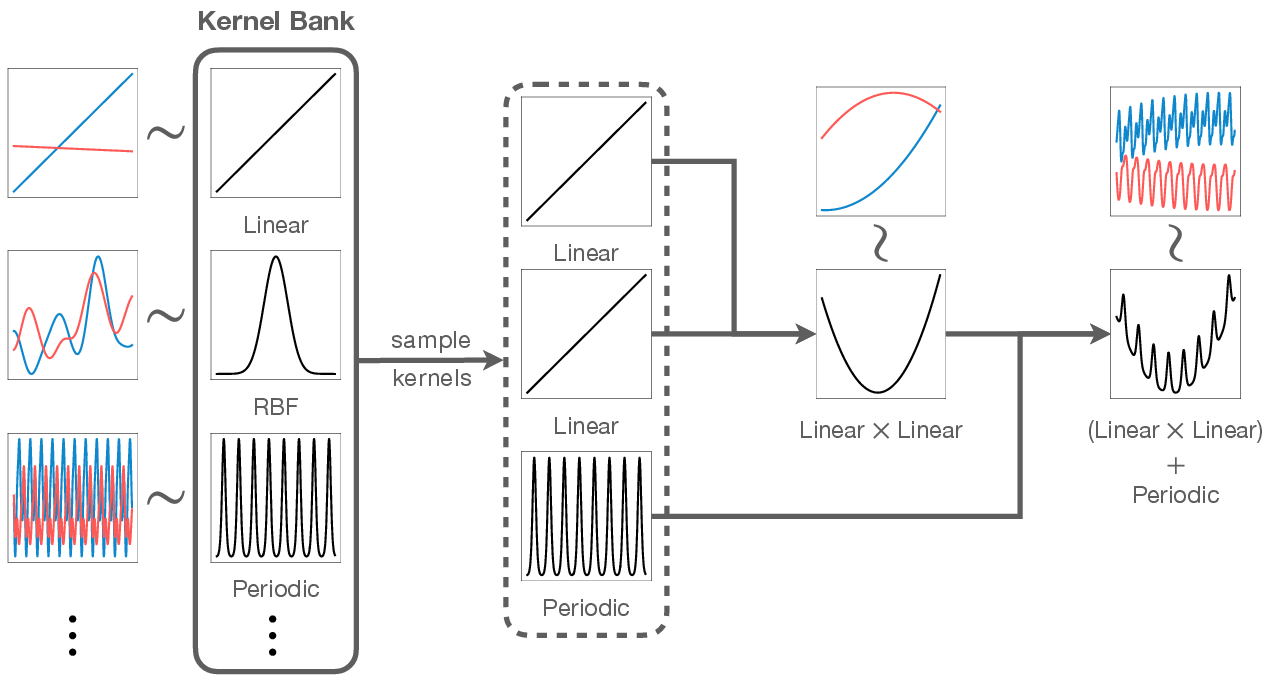
- KernelSynth: Generate realistic synthetic time series using Gaussian processes. This is like a pattern generator: they pick simple building-block patterns (trend, smooth changes, periodic cycles), randomly combine them with plus or times, and sample new series. This creates rich, believable curves for training.
- Forecasting (making predictions):
- The model predicts the next token step by step (autoregressive), like guessing the next word in a sentence.
- The predicted tokens are turned back into numbers (dequantization) and then unscaled to the original size.
- Because the model predicts a probability distribution over tokens, you can sample multiple future paths to get probabilistic forecasts (not just one point).
- A note on “regression via classification”:
- Instead of predicting exact numbers directly, Chronos predicts which bin a number falls into (classification). Since bins are ordered, nearby bins mean similar values. This keeps the model simple and flexible and allows it to learn complex, even multi-peaked distributions.
Main Findings and Why They Matter
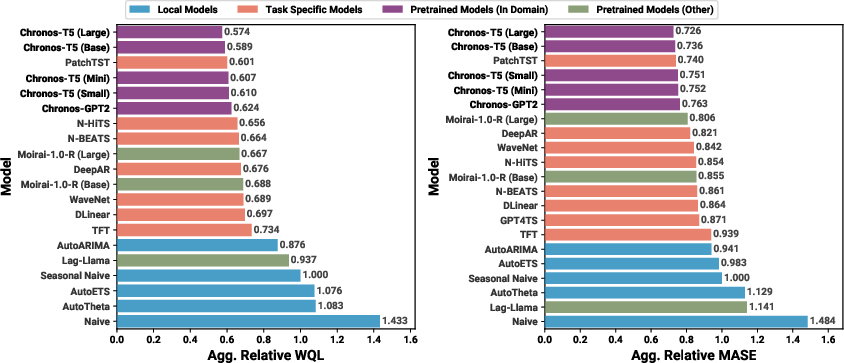
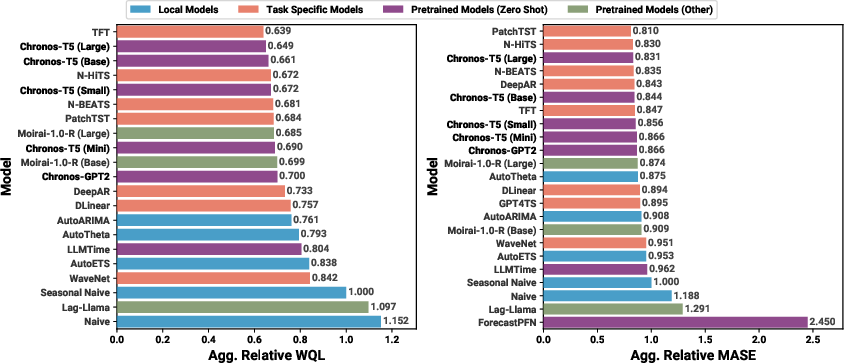
Across a large benchmark of 42 datasets, Chronos shows strong results:
- In-domain performance (datasets the model was trained on):
- Chronos (especially larger T5 models) beats traditional statistical methods like ARIMA and ETS.
- It also outperforms many deep learning models that are trained separately for each dataset.
- It competes strongly against other pretrained time-series models, sometimes with far fewer parameters.
- Zero-shot performance (new datasets the model never saw during training):
- Chronos performs as well as, and sometimes better than, models trained specifically on those new datasets.
- It clearly outperforms traditional baselines in zero-shot settings.
- This means Chronos can forecast well “out of the box” without extra tuning or prompt engineering.
- Efficiency and practicality:
- Chronos uses standard LLMs and simple tokenization. It doesn’t require huge, expensive LLMs or complicated time-series-specific architectures.
- Smaller Chronos models already show strong performance, making them more practical and faster to use.
- Evaluation:
- They judge both probabilistic forecasts (using weighted quantile loss) and point forecasts (using mean absolute scaled error).
- Results are fairly combined across datasets by comparing each model against a simple baseline (Seasonal Naive) and aggregating those ratios with geometric means. This avoids misleading averages.
Why it’s important:
- Chronos shows that time series can be treated like a “language,” making powerful LLM tools useful for forecasting.
- Good zero-shot performance reduces the need for per-dataset training and tuning, which can save time, money, and complexity in real-world systems.
Implications and Potential Impact
- Simpler forecasting pipelines: With Chronos, organizations could use one pretrained model for many different forecasting tasks without retraining for each dataset.
- Probabilistic forecasts by default: This helps decision-makers plan for uncertainty, not just point estimates.
- Foundation for general time-series AI: Since Chronos plugs into standard LLM frameworks, future LLM advances can directly benefit time-series forecasting. It may also help with other time-series tasks like anomaly detection, classification, and imputation.
- Practical and scalable: Smaller, efficient models that still perform well make forecasting more accessible, especially for teams without huge compute resources.
- Limitations and future work: Because values are quantized into bins, extremely strong trends or values outside the chosen range can be harder to model. The authors discuss this and show that in practice the approach works well, but finer or adaptive binning, trend handling, or time features could improve it further.
Overall, Chronos is an exciting step toward “learning the language of time” — using the strengths of LLMs to understand and predict the patterns of real-world data over time.
Collections
Sign up for free to add this paper to one or more collections.