Effective Gradient Sample Size via Variation Estimation for Accelerating Sharpness aware Minimization
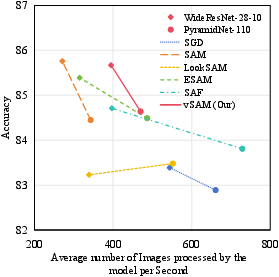
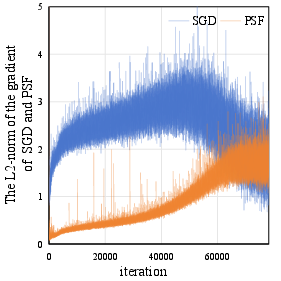
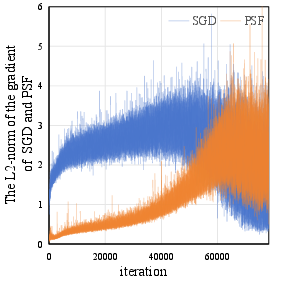
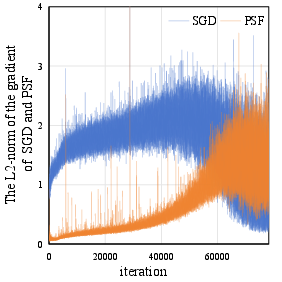
Abstract: Sharpness-aware Minimization (SAM) has been proposed recently to improve model generalization ability. However, SAM calculates the gradient twice in each optimization step, thereby doubling the computation costs compared to stochastic gradient descent (SGD). In this paper, we propose a simple yet efficient sampling method to significantly accelerate SAM. Concretely, we discover that the gradient of SAM is a combination of the gradient of SGD and the Projection of the Second-order gradient matrix onto the First-order gradient (PSF). PSF exhibits a gradually increasing frequency of change during the training process. To leverage this observation, we propose an adaptive sampling method based on the variation of PSF, and we reuse the sampled PSF for non-sampling iterations. Extensive empirical results illustrate that the proposed method achieved state-of-the-art accuracies comparable to SAM on diverse network architectures.
- Towards understanding sharpness-aware minimization. In Proceedings of the International Conference on Machine Learning (ICML), pages 639–668. PMLR, 2022.
- Entropy-sgd: Biasing gradient descent into wide valleys. Journal of Statistical Mechanics: Theory and Experiment, 2019(12):124018, 2019.
- When vision transformers outperform resnets without pre-training or strong data augmentations. 2022.
- Improved regularization of convolutional neural networks with cutout. arXiv preprint arXiv:1708.04552, 2017.
- Sharp minima can generalize for deep nets. In Proceedings of the International Conference on Machine Learning (ICML), pages 1019–1028. PMLR, 2017.
- Efficient sharpness-aware minimization for improved training of neural networks. 2022.
- Sharpness-aware training for free. Advances in Neural Information Processing Systems (NeurIPS), 35:23439–23451, 2022.
- Learned step size quantization. In Proceedings of the International Conference on Learning Representations (ICLR), 2020.
- Sharpness-aware minimization for efficiently improving generalization. 2021.
- Deep pyramidal residual networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), pages 5927–5935, 2017.
- Deep residual learning for image recognition. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016.
- Simplifying neural nets by discovering flat minima. Advances in Neural Information Processing Systems (NeurIPS), 7, 1994.
- Averaging weights leads to wider optima and better generalization. pages 876–885.
- Fantastic generalization measures and where to find them. 2020.
- An adaptive policy to employ sharpness-aware minimization. In Proceedings of the International Conference on Learning Representations (ICLR), 2023.
- On large-batch training for deep learning: Generalization gap and sharp minima. Proceedings of the International Conference on Learning Representations (ICLR), 2017.
- Learning multiple layers of features from tiny images. 2009.
- Asam: Adaptive sharpness-aware minimization for scale-invariant learning of deep neural networks. In Proceedings of the International Conference on Machine Learning (ICML), pages 5905–5914. PMLR, 2021.
- Visualizing the loss landscape of neural nets. Advances in Neural Information Processing Systems (NeurIPS), pages 6391–6401, 2018.
- On the loss landscape of adversarial training: Identifying challenges and how to overcome them. Advances in Neural Information Processing Systems (NeurIPS), 33:21476–21487, 2020.
- Towards efficient and scalable sharpness-aware minimization. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), pages 12360–12370, 2022.
- Sgdr: Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983, 2016.
- Unique properties of flat minima in deep networks. In Proceedings of the International Conference on Machine Learning (ICML), pages 7108–7118. PMLR, 2020.
- Overcoming oscillations in quantization-aware training. In Proceedings of the International Conference on Machine Learning (ICML), pages 16318–16330. PMLR, 2022.
- Exploring the vulnerability of deep neural networks: A study of parameter corruption. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), volume 35, pages 11648–11656, 2021.
- Improved sample complexities for deep neural networks and robust classification via an all-layer margin. In Proceedings of the International Conference on Learning Representations (ICLR), 2019.
- Qdrop: Randomly dropping quantization for extremely low-bit post-training quantization. In Proceedings of the International Conference on Learning Representations (ICLR), 2021.
- Wide residual networks. arXiv preprint arXiv:1605.07146, 2016.
- Understanding deep learning (still) requires rethinking generalization. Communications of the ACM, 64(3):107–115, 2021.
- Gradient norm aware minimization seeks first-order flatness and improves generalization. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), pages 20247–20257, 2023.
- Regularizing neural networks via adversarial model perturbation. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), pages 8156–8165, 2021.
- Towards understanding why lookahead generalizes better than sgd and beyond. Advances in Neural Information Processing Systems (NeurIPS), 34:27290–27304, 2021.
- Understanding the robustness in vision transformers. In Proceedings of the International Conference on Machine Learning (ICML), pages 27378–27394. PMLR, 2022.
- Surrogate gap minimization improves sharpness-aware training. 2022.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.