- The paper demonstrates that modernizing DenseNets with widened architectures and advanced training methods can outperform ResNets and rival ViTs.
- The methodology leverages techniques like Label Smoothing, RandAugment, and modified block designs to boost speed, memory efficiency, and accuracy.
- Experimental results on ImageNet-1K, ADE20K, and COCO validate RDNet's competitive performance against state-of-the-art models.
DenseNets Reloaded: Paradigm Shift Beyond ResNets and ViTs
This paper revisits Densely Connected Convolutional Networks (DenseNets) and demonstrates their potential to surpass ResNet-style architectures. The authors contend that DenseNets have been overlooked due to outdated training methodologies and design elements. By refining these suboptimal components, the paper aims to widen DenseNets and improve memory efficiency while retaining concatenation shortcuts. The revitalized models achieve performance on par with Swin Transformer, ConvNeXt, and DeiT-III on ImageNet-1K and exhibit competitive results on downstream tasks like ADE20k semantic segmentation and COCO object detection/instance segmentation. The authors also provide empirical analyses highlighting the advantages of concatenation over additive shortcuts.
Introduction and Motivation
The introduction of residual learning with additive skip connections in ResNet provided a solution to the gradient vanishing problem, allowing for the creation of deeper networks. DenseNets, however, employ feature concatenation as an alternative to additive shortcuts, promoting feature reuse and compact models. While DenseNets initially showed promise, their popularity declined due to limitations in scalability and memory management. This paper argues that the core design concept of DenseNets remains potent but requires modernization to compete with current architectures. The authors hypothesize that concatenation can outperform additive shortcuts and that memory concerns can be mitigated through strategic design.
Methodology: Revitalizing DenseNets
The paper's methodology centers on revitalizing DenseNets by modernizing their architecture and training. This involves widening the networks while maintaining memory efficiency, abandoning ineffective components, and enhancing architectural and block designs.
The process starts with a pilot study involving 15k networks trained on Tiny-ImageNet to validate the claim that concatenation can surpass additive shortcuts. The authors train a DenseNet-201 baseline with a modern training setup, including techniques such as Label Smoothing, RandAugment, Random Erasing, Mixup, Cutmix, and Stochastic Depth, along with the AdamW optimizer and cosine learning rate schedule. The next step involves modifying DenseNet to be wider and shallower by increasing the growth rate (GR) while reducing depth. The number of blocks per stage is reduced from (6, 12, 48, 32) to (3, 3, 12, 3). This modification leads to a reduction in latency and improved memory efficiency.
(Figure 1)
Figure 1: Schematic illustration of RDNet.
The base block is then replaced with a modern feature mixer block, incorporating Layer Normalization (LN), post-activation, depthwise convolution, fewer normalizations and activations, and a kernel size of 7. The output channel (GR) is smaller than the input channel (C), resulting in more compressed features. The authors then increase the intermediate channel dimensions by decoupling the expansion ratio (ER) from the growth rate (GR), leading to faster training speed and improved accuracy. More transition layers are added within each stage to reduce the number of channels, and variable GRs are introduced at different stages. A patchification stem is employed to accelerate computational speed without sacrificing precision. The transition layers are refined by removing average pooling and adjusting the kernel size and stride and channel re-scaling is investigated. Finally, the Revitalized DenseNet (RDNet) architecture is introduced (Figure 1), achieving both enhanced precision and faster speed.
Experimental Results and Analysis
The RDNet model family is evaluated on ImageNet-1K, ADE20K semantic segmentation, and COCO object detection/instance segmentation. The ImageNet-1K experiments follow the training setups of Swin Transformer and ConvNeXt. The results demonstrate that RDNet models achieve competitive performance compared to state-of-the-art models, with a favorable trade-off between accuracy and speed.
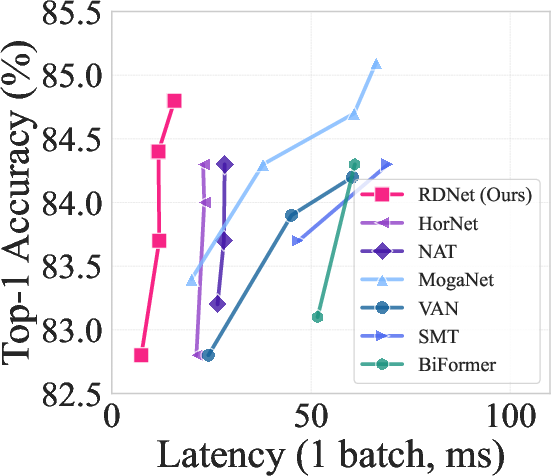
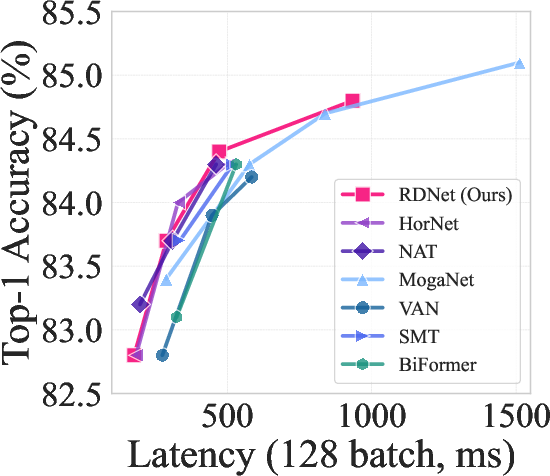
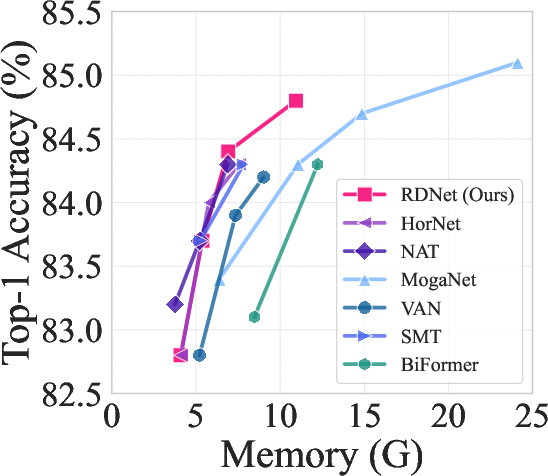
Figure 2: ImageNet-1K performance trade-off among state-of-the-arts.
RDNet also exhibits competitive performance in zero-shot image classification using CLIP. The models are further evaluated on downstream tasks such as semantic segmentation on ADE20K and object detection on COCO, demonstrating strong performance and effectiveness on dense prediction tasks. Ablation studies are conducted to analyze the impact of various design choices on performance.
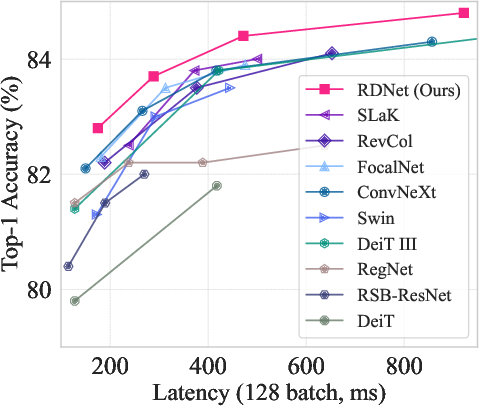
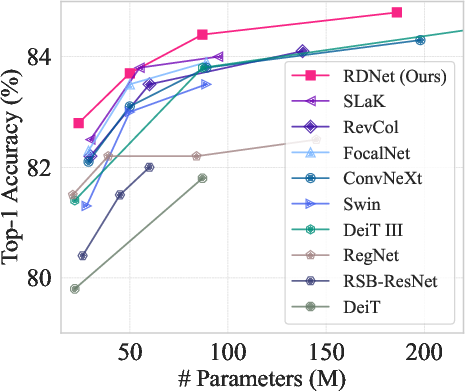
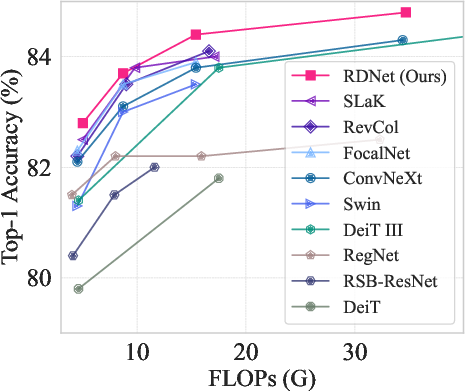
Figure 3: ImageNet-1K performance trade-off among previous milestones.
The paper includes a discussion of several key findings. First, RDNet exhibits adaptability to input size variations, attributed to the effectiveness of dense connections. Second, RDNet's optimized width avoids latency and memory loss, unlike width-oriented networks. Third, CKA analysis reveals that RDNet learns distinct features at every layer compared to ConvNeXt, showcasing different learning dynamics. Finally, Stochastic Depth improves the model's performance, suggesting its importance in DenseNet architectures.
Conclusion
This paper successfully revisits DenseNets, demonstrating their ability to compete with modern architectures through architectural and training modernizations. The authors rediscover the potential of DenseNets, highlighting the underappreciated fact that DenseNet's concatenation shortcuts surpass the expressivity of addition-based shortcuts. The RDNet models achieve competitive performance on ImageNet-1K and exhibit enhanced performance in dense prediction tasks.
This work highlights the advantages of using concatenations in network design, advocating for the consideration of DenseNet-style architectures alongside ResNet-style ones.