GaitSTR: Gait Recognition with Sequential Two-stream Refinement
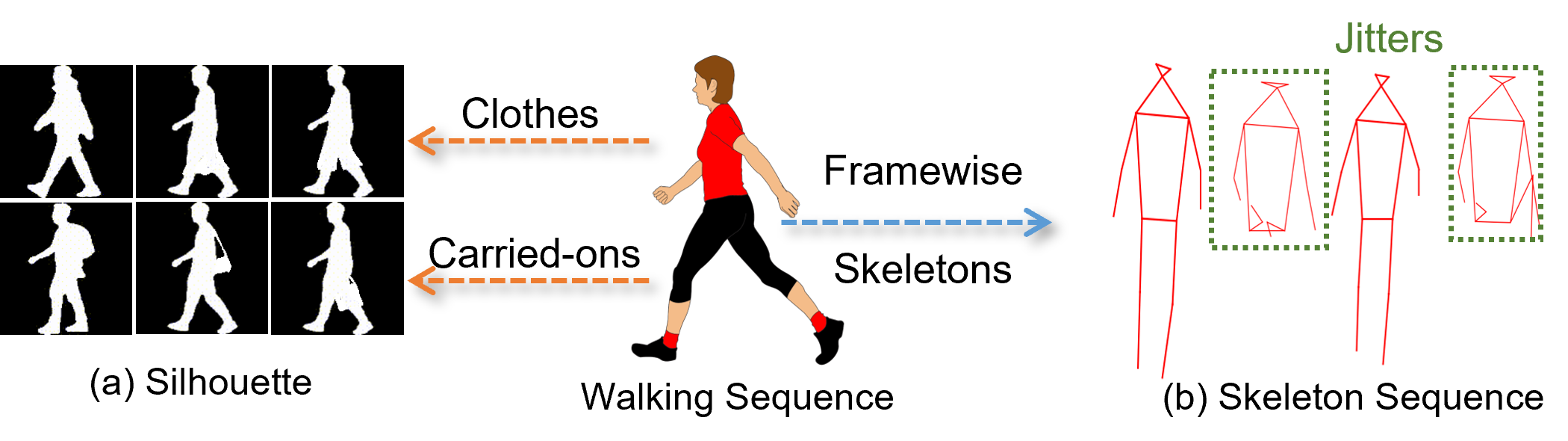
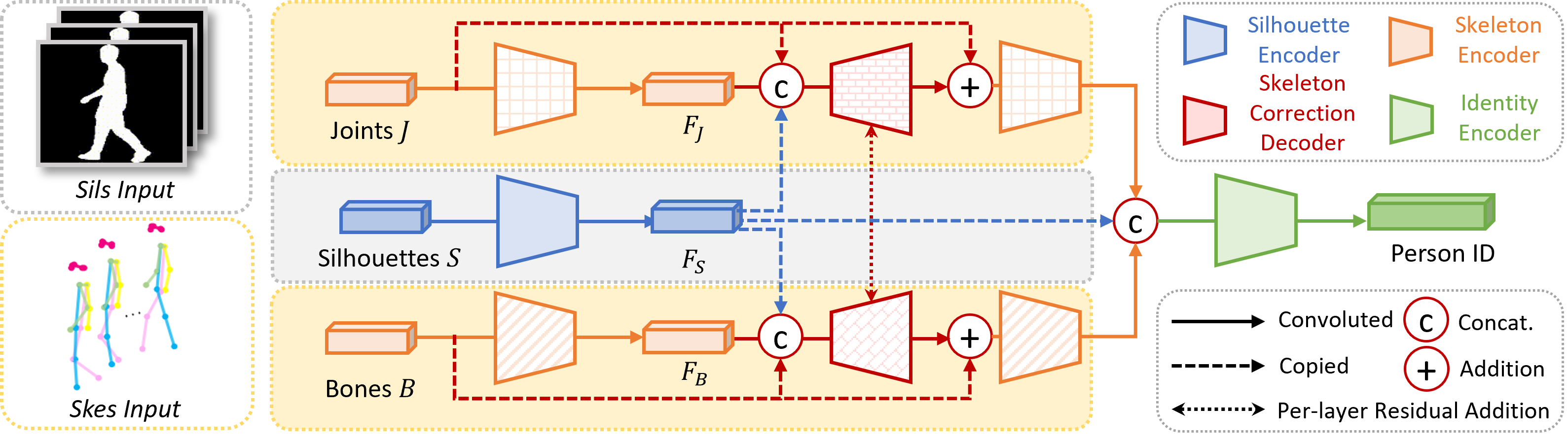
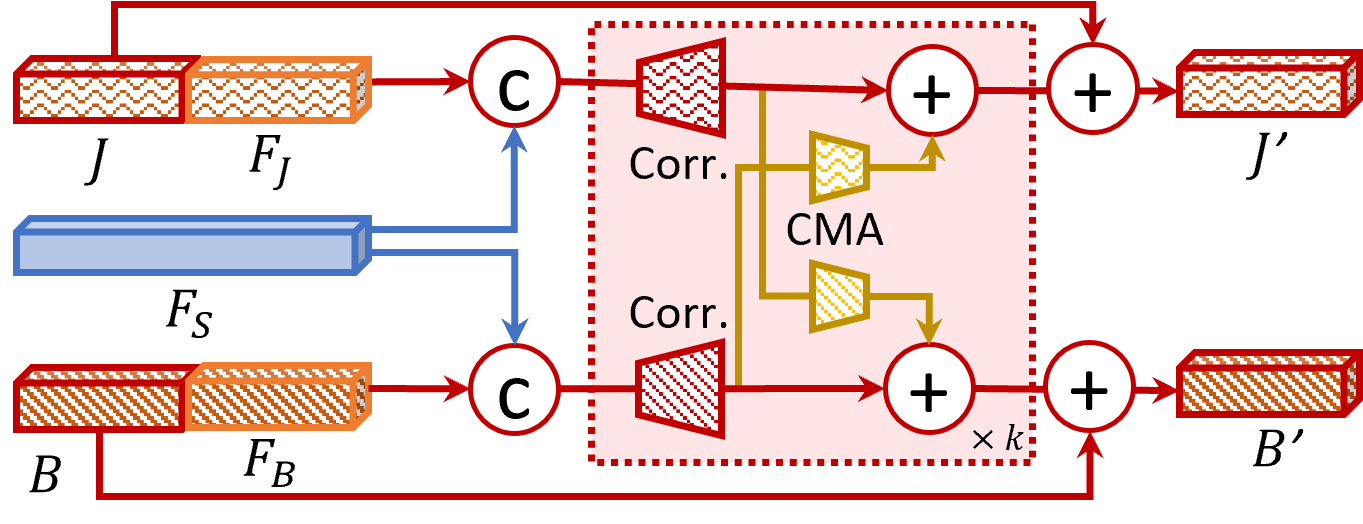
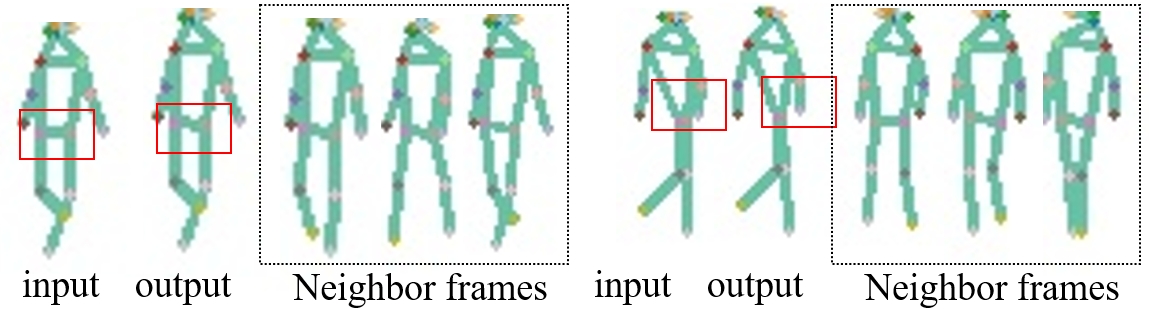
Abstract: Gait recognition aims to identify a person based on their walking sequences, serving as a useful biometric modality as it can be observed from long distances without requiring cooperation from the subject. In representing a person's walking sequence, silhouettes and skeletons are the two primary modalities used. Silhouette sequences lack detailed part information when overlapping occurs between different body segments and are affected by carried objects and clothing. Skeletons, comprising joints and bones connecting the joints, provide more accurate part information for different segments; however, they are sensitive to occlusions and low-quality images, causing inconsistencies in frame-wise results within a sequence. In this paper, we explore the use of a two-stream representation of skeletons for gait recognition, alongside silhouettes. By fusing the combined data of silhouettes and skeletons, we refine the two-stream skeletons, joints, and bones through self-correction in graph convolution, along with cross-modal correction with temporal consistency from silhouettes. We demonstrate that with refined skeletons, the performance of the gait recognition model can achieve further improvement on public gait recognition datasets compared with state-of-the-art methods without extra annotations.
- Y. He, J. Zhang, H. Shan, and L. Wang, “Multi-task gans for view-specific feature learning in gait recognition,” TIFS, vol. 14, no. 1, pp. 102–113, 2018.
- C. Song, Y. Huang, Y. Huang, N. Jia, and L. Wang, “Gaitnet: An end-to-end network for gait based human identification,” PR, vol. 96, p. 106988, 2019.
- Z. Wu, Y. Huang, L. Wang, X. Wang, and T. Tan, “A comprehensive study on cross-view gait based human identification with deep cnns,” TPAMI, vol. 39, no. 2, pp. 209–226, 2016.
- S. Yu, H. Chen, Q. Wang, L. Shen, and Y. Huang, “Invariant feature extraction for gait recognition using only one uniform model,” Neurocomputing, vol. 239, pp. 81–93, 2017.
- H. Chao, Y. He, J. Zhang, and J. Feng, “Gaitset: Regarding gait as a set for cross-view gait recognition,” in AAAI, 2019, pp. 8126–8133.
- C. Fan, Y. Peng, C. Cao, X. Liu, S. Hou, J. Chi, Y. Huang, Q. Li, and Z. He, “Gaitpart: Temporal part-based model for gait recognition,” in CVPR, 2020, pp. 14 225–14 233.
- B. Lin, S. Zhang, and X. Yu, “Gait recognition via effective global-local feature representation and local temporal aggregation,” in ICCV, 2021, pp. 14 648–14 656.
- T. Teepe, A. Khan, J. Gilg, F. Herzog, S. Hörmann, and G. Rigoll, “Gaitgraph: Graph convolutional network for skeleton-based gait recognition,” in ICIP, 2021, pp. 2314–2318.
- A. Zeng, L. Yang, X. Ju, J. Li, J. Wang, and Q. Xu, “Smoothnet: A plug-and-play network for refining human poses in videos,” ECCV, 2022.
- H. Zhu, W. Zheng, Z. Zheng, and R. Nevatia, “Gaitref: Gait recognition with refined sequential skeletons,” IJCB, 2023.
- L. Shi, Y. Zhang, J. Cheng, and H. Lu, “Two-stream adaptive graph convolutional networks for skeleton-based action recognition,” in CVPR, 2019, pp. 12 026–12 035.
- H. Zhu, Z. Zheng, and R. Nevatia, “Temporal shift and attention modules for graphical skeleton action recognition,” in ICPR, 2022, pp. 3145–3151.
- S. Yan, Y. Xiong, and D. Lin, “Spatial temporal graph convolutional networks for skeleton-based action recognition,” in AAAI, 2018.
- K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in CVPR, 2016, pp. 770–778.
- S. Yu, D. Tan, and T. Tan, “A framework for evaluating the effect of view angle, clothing and carrying condition on gait recognition,” in ICPR, vol. 4, 2006, pp. 441–444.
- N. Takemura, Y. Makihara, D. Muramatsu, T. Echigo, and Y. Yagi, “Multi-view large population gait dataset and its performance evaluation for cross-view gait recognition,” TCVA, vol. 10, no. 1, pp. 1–14, 2018.
- J. Zheng, X. Liu, W. Liu, L. He, C. Yan, and T. Mei, “Gait recognition in the wild with dense 3d representations and a benchmark,” in CVPR, 2022, pp. 20 228–20 237.
- Z. Zhu, X. Guo, T. Yang, J. Huang, J. Deng, G. Huang, D. Du, J. Lu, and J. Zhou, “Gait recognition in the wild: A benchmark,” in ICCV, 2021, pp. 14 789–14 799.
- H. Dou, P. Zhang, W. Su, Y. Yu, Y. Lin, and X. Li, “Gaitgci: Generative counterfactual intervention for gait recognition,” in CVPR, 2023, pp. 5578–5588.
- M. Wang, X. Guo, B. Lin, T. Yang, Z. Zhu, L. Li, S. Zhang, and X. Yu, “Dygait: Exploiting dynamic representations for high-performance gait recognition,” ICCV, 2023.
- K. Ma, Y. Fu, D. Zheng, C. Cao, X. Hu, and Y. Huang, “Dynamic aggregated network for gait recognition,” in CVPR, 2023, pp. 22 076–22 085.
- Z. Huang, D. Xue, X. Shen, X. Tian, H. Li, J. Huang, and X.-S. Hua, “3d local convolutional neural networks for gait recognition,” in ICCV, 2021, pp. 14 920–14 929.
- C. Fan, J. Liang, C. Shen, S. Hou, Y. Huang, and S. Yu, “Opengait: Revisiting gait recognition toward better practicality,” 2023.
- W. An, S. Yu, Y. Makihara, X. Wu, C. Xu, Y. Yu, R. Liao, and Y. Yagi, “Performance evaluation of model-based gait on multi-view very large population database with pose sequences,” TBIOM, vol. 2, no. 4, pp. 421–430, 2020.
- Y. Sun, X. Feng, L. Ma, L. Hu, and M. Nixon, “Trigait: Aligning and fusing skeleton and silhouette gait data via a tri-branch network,” in IJCB, 2023.
- H. Guo and Q. Ji, “Physics-augmented autoencoder for 3d skeleton-based gait recognition,” in ICCV, 2023, pp. 19 627–19 638.
- X. Huang, X. Wang, Z. Jin, B. Yang, B. He, B. Feng, and W. Liu, “Condition-adaptive graph convolution learning for skeleton-based gait recognition,” TIP, 2023.
- Y. Cui and Y. Kang, “Multi-modal gait recognition via effective spatial-temporal feature fusion,” in CVPR, 2023, pp. 17 949–17 957.
- S. Hou, C. Cao, X. Liu, and Y. Huang, “Gait lateral network: Learning discriminative and compact representations for gait recognition,” in ECCV, 2020, pp. 382–398.
- X. Li, Y. Makihara, C. Xu, Y. Yagi, S. Yu, and M. Ren, “End-to-end model-based gait recognition,” in ACCV, 2020.
- H. Zhu, W. Zheng, Z. Zheng, and R. Nevatia, “Sharc: Shape and appearance recognition for person identification in-the-wild,” arXiv preprint arXiv:2310.15946, 2023.
- H. Zhu, Z. Zheng, and R. Nevatia, “Gait recognition using 3-d human body shape inference,” in WACV, 2023, pp. 909–918.
- R. Liao, S. Yu, W. An, and Y. Huang, “A model-based gait recognition method with body pose and human prior knowledge,” PR, 2020.
- J. Wang, K. Sun, T. Cheng, B. Jiang, C. Deng, Y. Zhao, D. Liu, Y. Mu, M. Tan, X. Wang et al., “Deep high-resolution representation learning for visual recognition,” TPAMI, vol. 43, no. 10, pp. 3349–3364, 2020.
- L. Wang, R. Han, J. Chen, and W. Feng, “Combining the silhouette and skeleton data for gait recognition,” arXiv preprint arXiv:2202.10645, 2022.
- E. Pinyoanuntapong, A. Ali, P. Wang, M. Lee, and C. Chen, “Gaitmixer: skeleton-based gait representation learning via wide-spectrum multi-axial mixer,” in ICASSP, 2023, pp. 1–5.
- B. Xiao, H. Wu, and Y. Wei, “Simple baselines for human pose estimation and tracking,” in ECCV, 2018.
- Z. Cao, G. Hidalgo, T. Simon, S.-E. Wei, and Y. Sheikh, “Openpose: realtime multi-person 2d pose estimation using part affinity fields,” TPAMI, vol. 43, no. 1, pp. 172–186, 2019.
- K. Li, S. Wang, X. Zhang, Y. Xu, W. Xu, and Z. Tu, “Pose recognition with cascade transformers,” in CVPR, 2021, pp. 1944–1953.
- Y. Li, S. Zhang, Z. Wang, S. Yang, W. Yang, S.-T. Xia, and E. Zhou, “Tokenpose: Learning keypoint tokens for human pose estimation,” in ICCV, 2021.
- S. Yang, Z. Quan, M. Nie, and W. Yang, “Transpose: Keypoint localization via transformer,” in ICCV, 2021.
- Y. Xu, J. Zhang, Q. Zhang, and D. Tao, “Vitpose: Simple vision transformer baselines for human pose estimation,” arXiv preprint arXiv:2204.12484, 2022.
- Y. Yuan, R. Fu, L. Huang, W. Lin, C. Zhang, X. Chen, and J. Wang, “Hrformer: High-resolution transformer for dense prediction,” in NeurIPS, 2021.
- D. Rempe, T. Birdal, A. Hertzmann, J. Yang, S. Sridhar, and L. J. Guibas, “Humor: 3d human motion model for robust pose estimation,” in ICCV, 2021, pp. 11 488–11 499.
- H. Xu, Y. Gao, Z. Hui, J. Li, and X. Gao, “Language knowledge-assisted representation learning for skeleton-based action recognition,” arXiv preprint arXiv:2305.12398, 2023.
- Y. Fu, Y. Wei, Y. Zhou, H. Shi, G. Huang, X. Wang, Z. Yao, and T. Huang, “Horizontal pyramid matching for person re-identification,” in AAAI, vol. 33, 2019, pp. 8295–8302.
- H. Zhu, Y. Yuan, Y. Zhu, X. Yang, and R. Nevatia, “Open: Order-preserving pointcloud encoder decoder network for body shape refinement,” in ICPR, 2022.
- K. Sun, B. Xiao, D. Liu, and J. Wang, “Deep high-resolution representation learning for human pose estimation,” in CVPR, 2019, pp. 5693–5703.
- T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick, “Microsoft coco: Common objects in context,” in ECCV, 2014, pp. 740–755.
- X. Huang, D. Zhu, H. Wang, X. Wang, B. Yang, B. He, W. Liu, and B. Feng, “Context-sensitive temporal feature learning for gait recognition,” in ICCV, 2021, pp. 12 909–12 918.
- X. Li, Y. Makihara, C. Xu, and Y. Yagi, “End-to-end model-based gait recognition using synchronized multi-view pose constraint,” in ICCV, 2021, pp. 4106–4115.
- J. Liang, C. Fan, S. Hou, C. Shen, Y. Huang, and S. Yu, “Gaitedge: Beyond plain end-to-end gait recognition for better practicality,” arXiv preprint arXiv:2203.03972, 2022.
- Z. Liu, H. Zhang, Z. Chen, Z. Wang, and W. Ouyang, “Disentangling and unifying graph convolutions for skeleton-based action recognition,” in CVPR, 2020, pp. 143–152.
- D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- M. Ye, J. Shen, G. Lin, T. Xiang, L. Shao, and S. C. Hoi, “Deep learning for person re-identification: A survey and outlook,” TPAMI, vol. 44, no. 6, pp. 2872–2893, 2021.
- K. Shiraga, Y. Makihara, D. Muramatsu, T. Echigo, and Y. Yagi, “Geinet: View-invariant gait recognition using a convolutional neural network,” in ICB, 2016, pp. 1–8.
- Y. Sun, W. Liu, Q. Bao, Y. Fu, T. Mei, and M. J. Black, “Putting people in their place: Monocular regression of 3d people in depth,” in CVPR, 2022, pp. 13 243–13 252.
- C. Ionescu, D. Papava, V. Olaru, and C. Sminchisescu, “Human3. 6m: Large scale datasets and predictive methods for 3d human sensing in natural environments,” TPAMI, pp. 1325–1339, 2013.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.