PiSSA: Principal Singular Values and Singular Vectors Adaptation of Large Language Models
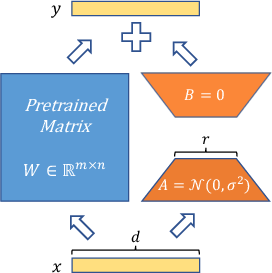
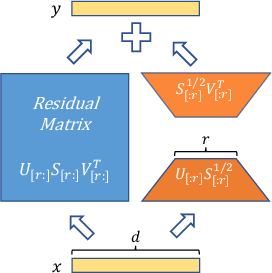
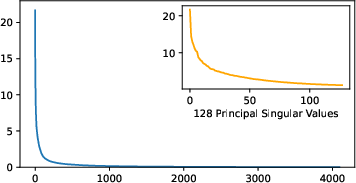
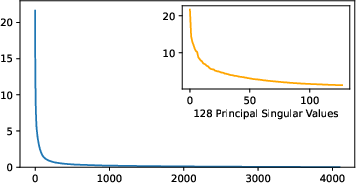
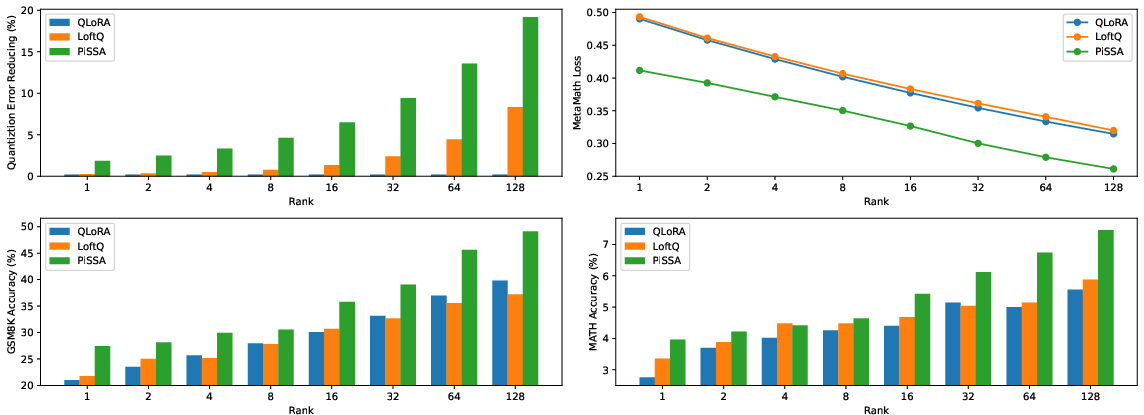
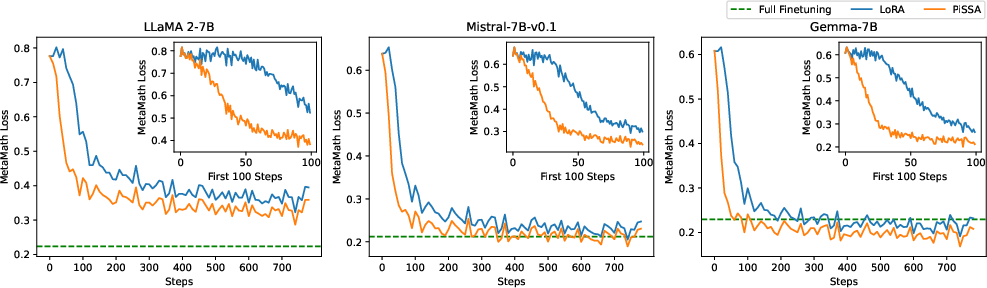
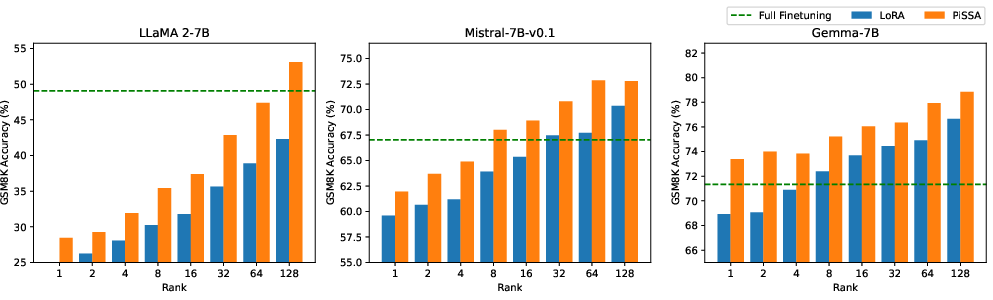
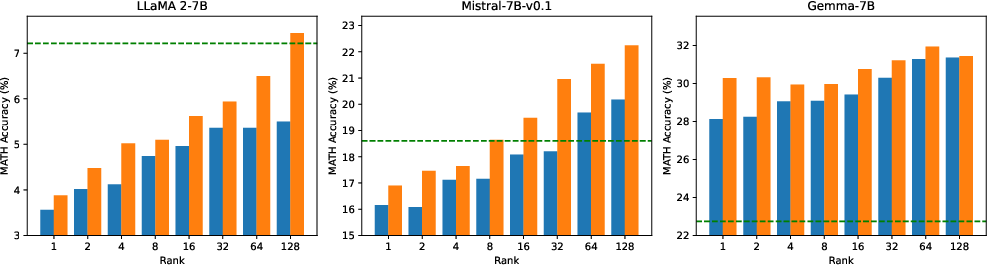
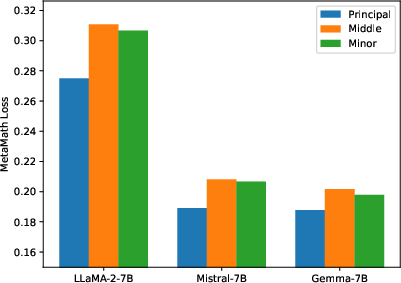
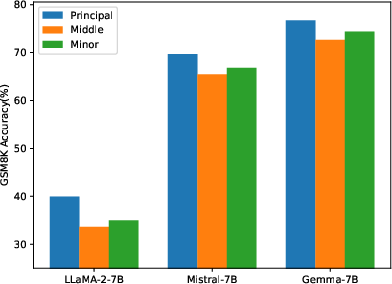
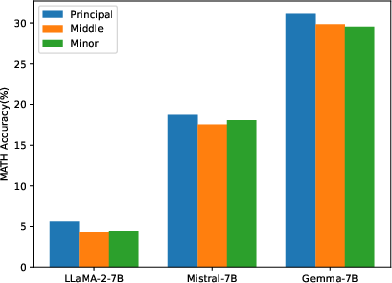
Abstract: To parameter-efficiently fine-tune (PEFT) LLMs, the low-rank adaptation (LoRA) method approximates the model changes $ΔW \in \mathbb{R}{m \times n}$ through the product of two matrices $A \in \mathbb{R}{m \times r}$ and $B \in \mathbb{R}{r \times n}$, where $r \ll \min(m, n)$, $A$ is initialized with Gaussian noise, and $B$ with zeros. LoRA freezes the original model $W$ and updates the "Noise & Zero" adapter, which may lead to slow convergence. To overcome this limitation, we introduce Principal Singular values and Singular vectors Adaptation (PiSSA). PiSSA shares the same architecture as LoRA, but initializes the adaptor matrices $A$ and $B$ with the principal components of the original matrix $W$, and put the remaining components into a residual matrix $W{res} \in \mathbb{R}{m \times n}$ which is frozen during fine-tuning. Compared to LoRA, PiSSA updates the principal components while freezing the "residual" parts, allowing faster convergence and enhanced performance. Comparative experiments of PiSSA and LoRA across 12 different models, ranging from 184M to 70B, encompassing 5 NLG and 8 NLU tasks, reveal that PiSSA consistently outperforms LoRA under identical experimental setups. On the GSM8K benchmark, Mistral-7B fine-tuned with PiSSA achieves an accuracy of 72.86%, surpassing LoRA's 67.7% by 5.16%. Due to the same architecture, PiSSA is also compatible with quantization to further reduce the memory requirement of fine-tuning. Compared to QLoRA, QPiSSA exhibits smaller quantization errors in the initial stages. Fine-tuning LLaMA-3-70B on GSM8K, QPiSSA attains an accuracy of 86.05%, exceeding the performances of QLoRA at 81.73%. Leveraging a fast SVD technique, PiSSA can be initialized in only a few seconds, presenting a negligible cost for transitioning from LoRA to PiSSA. Code is available at https://github.com/GraphPKU/PiSSA.
- Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct. arXiv preprint arXiv:2308.09583, 2023.
- Metamath: Bootstrap your own mathematical questions for large language models. arXiv preprint arXiv:2309.12284, 2023.
- Wizardcoder: Empowering code large language models with evol-instruct. arXiv preprint arXiv:2306.08568, 2023.
- Starcoder: may the source be with you! arXiv preprint arXiv:2305.06161, 2023.
- Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744, 2022.
- Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in Neural Information Processing Systems, 36, 2024.
- Wizardlm: Empowering large pre-trained language models to follow complex instructions. In The Twelfth International Conference on Learning Representations, 2023.
- Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862, 2022.
- Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems, 36, 2024.
- Qlora: Efficient finetuning of quantized llms. Advances in Neural Information Processing Systems, 36, 2024.
- Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
- Parameter-efficient fine-tuning methods for pretrained language models: A critical review and assessment. arXiv preprint arXiv:2312.12148, 2023.
- Parameter-efficient fine-tuning for large models: A comprehensive survey. arXiv preprint arXiv:2403.14608, 2024.
- Measuring the intrinsic dimension of objective landscapes. arXiv preprint arXiv:1804.08838, 2018.
- Intrinsic dimensionality explains the effectiveness of language model fine-tuning. arXiv preprint arXiv:2012.13255, 2020.
- Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models. arXiv preprint arXiv:2106.10199, 2021.
- Neural architecture search for parameter-efficient fine-tuning of large pre-trained language models. arXiv preprint arXiv:2305.16597, 2023.
- Masking as an efficient alternative to finetuning for pretrained language models. arXiv preprint arXiv:2004.12406, 2020.
- Training neural networks with fixed sparse masks. Advances in Neural Information Processing Systems, 34:24193–24205, 2021.
- Composable sparse fine-tuning for cross-lingual transfer. arXiv preprint arXiv:2110.07560, 2021.
- Raise a child in large language model: Towards effective and generalizable fine-tuning. arXiv preprint arXiv:2109.05687, 2021.
- Parameter-efficient transfer learning with diff pruning. arXiv preprint arXiv:2012.07463, 2020.
- On the effectiveness of parameter-efficient fine-tuning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 12799–12807, 2023.
- Warp: Word-level adversarial reprogramming. arXiv preprint arXiv:2101.00121, 2021.
- The power of scale for parameter-efficient prompt tuning. arXiv preprint arXiv:2104.08691, 2021.
- Prefix-tuning: Optimizing continuous prompts for generation. arXiv preprint arXiv:2101.00190, 2021.
- Gpt understands, too. AI Open, 2023.
- Spot: Better frozen model adaptation through soft prompt transfer. arXiv preprint arXiv:2110.07904, 2021.
- Attempt: Parameter-efficient multi-task tuning via attentional mixtures of soft prompts. arXiv preprint arXiv:2205.11961, 2022.
- Multitask prompt tuning enables parameter-efficient transfer learning. arXiv preprint arXiv:2303.02861, 2023.
- Parameter-efficient transfer learning for nlp. In International conference on machine learning, pages 2790–2799. PMLR, 2019.
- Exploring versatile generative language model via parameter-efficient transfer learning. arXiv preprint arXiv:2004.03829, 2020.
- Conditional adapters: Parameter-efficient transfer learning with fast inference. Advances in Neural Information Processing Systems, 36, 2024.
- Towards a unified view of parameter-efficient transfer learning. arXiv preprint arXiv:2110.04366, 2021.
- Adapterdrop: On the efficiency of adapters in transformers. arXiv preprint arXiv:2010.11918, 2020.
- Tiny-attention adapter: Contexts are more important than the number of parameters. arXiv preprint arXiv:2211.01979, 2022.
- Adapterfusion: Non-destructive task composition for transfer learning. arXiv preprint arXiv:2005.00247, 2020.
- Mera: Merging pretrained adapters for few-shot learning. arXiv preprint arXiv:2308.15982, 2023.
- Parameter-efficient multi-task fine-tuning for transformers via shared hypernetworks. arXiv preprint arXiv:2106.04489, 2021.
- Adaptersoup: Weight averaging to improve generalization of pretrained language models. arXiv preprint arXiv:2302.07027, 2023.
- Adaptive budget allocation for parameter-efficient fine-tuning. In The Eleventh International Conference on Learning Representations, 2022.
- Dylora: Parameter efficient tuning of pre-trained models using dynamic search-free low-rank adaptation. arXiv preprint arXiv:2210.07558, 2022.
- Increlora: Incremental parameter allocation method for parameter-efficient fine-tuning. arXiv preprint arXiv:2308.12043, 2023.
- Delta-lora: Fine-tuning high-rank parameters with the delta of low-rank matrices. arXiv preprint arXiv:2309.02411, 2023.
- Pruning meets low-rank parameter-efficient fine-tuning. arXiv preprint arXiv:2305.18403, 2023.
- Qa-lora: Quantization-aware low-rank adaptation of large language models. arXiv preprint arXiv:2309.14717, 2023.
- Loftq: Lora-fine-tuning-aware quantization for large language models. arXiv preprint arXiv:2310.08659, 2023.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- Mistral 7b. arXiv preprint arXiv:2310.06825, 2023.
- Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295, 2024.
- Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021.
- Opencodeinterpreter: Integrating code generation with execution and refinement. arXiv preprint arXiv:2402.14658, 2024.
- Evaluating large language models trained on code, 2021.
- Program synthesis with large language models. arXiv preprint arXiv:2108.07732, 2021.
- Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions. SIAM review, 53(2):217–288, 2011.
- Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca, 2023.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.