- The paper introduces a novel benchmark for real-time LLM safety analysis by evaluating eight distinct methods.
- It empirically demonstrates that early detection of unsafe outputs can optimize computational resources and enable timely interventions.
- Hybridization strategies are explored, suggesting adaptive safety techniques for both open and closed-source LLMs.
Online Safety Analysis for LLMs: A Comprehensive Evaluation
The paper, "Online Safety Analysis for LLMs: a Benchmark, an Assessment, and a Path Forward" (2404.08517), provides a thorough investigation into the challenges and methodologies associated with ensuring the safe operation of LLMs. Recognizing the growing deployment of LLMs in various sectors, the study emphasizes the necessity of safety analysis during the online, or real-time, execution phase. This work presents a novel benchmark for evaluating online safety methodologies, analyzes the effectiveness of different safety strategies, and explores the potential for hybrid solutions.
Introduction and Motivation
The proliferation of LLMs in fields ranging from healthcare to finance highlights their expansive capabilities but also underscores substantial safety concerns like hallucinations, toxicity, and bias. While recent efforts have focused on post-generation analysis through techniques such as detector-based methods and uncertainty estimations, there exists a gap in real-time, or online, safety analysis during the generation phase.
This study sets out to fill this gap by examining the feasibility of early-stage detection of unsafe outputs, establishing a benchmark for online safety analysis, and evaluating the effectiveness of existing methodologies across various LLMs and tasks. The ultimate goal is to identify promising directions for future safety assurance technologies.
Benchmark Construction
The paper introduces a diverse and comprehensive benchmark including:
- Online Safety Analysis Methods: Eight methods spanning black-box, white-box, and grey-box categories.
- LLMs: A thorough examination of both open-source models (e.g., LLaMA, Vicuna) and closed-source models (e.g., GPT-3, GPT-4).
- Tasks: Diverse applications such as question answering, text continuation, machine translation, and code generation.
- Metrics: Evaluations based on Safety Gain (SG), Residual Hazard (RH), Availability Cost (AC), and traditional metrics like AUC and time cost.
Pilot Study and Results
The pilot study aimed to verify the feasibility of identifying unsafe outputs during the early stages of LLM generation. Utilizing datasets such as TruthfulQA and RealToxicityPrompt, the study demonstrated that a significant portion of unsafe outputs could be detected early, thereby supporting the importance of integrating online safety analysis into LLMs.
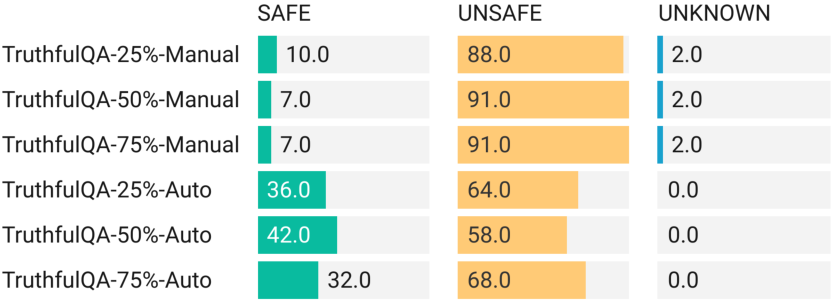
Figure 1: Pilot Study Result of TruthfulQA, result in %.
This early detection capability not only promises to optimize computational resources but also ensures timely intervention to mitigate potential harms.
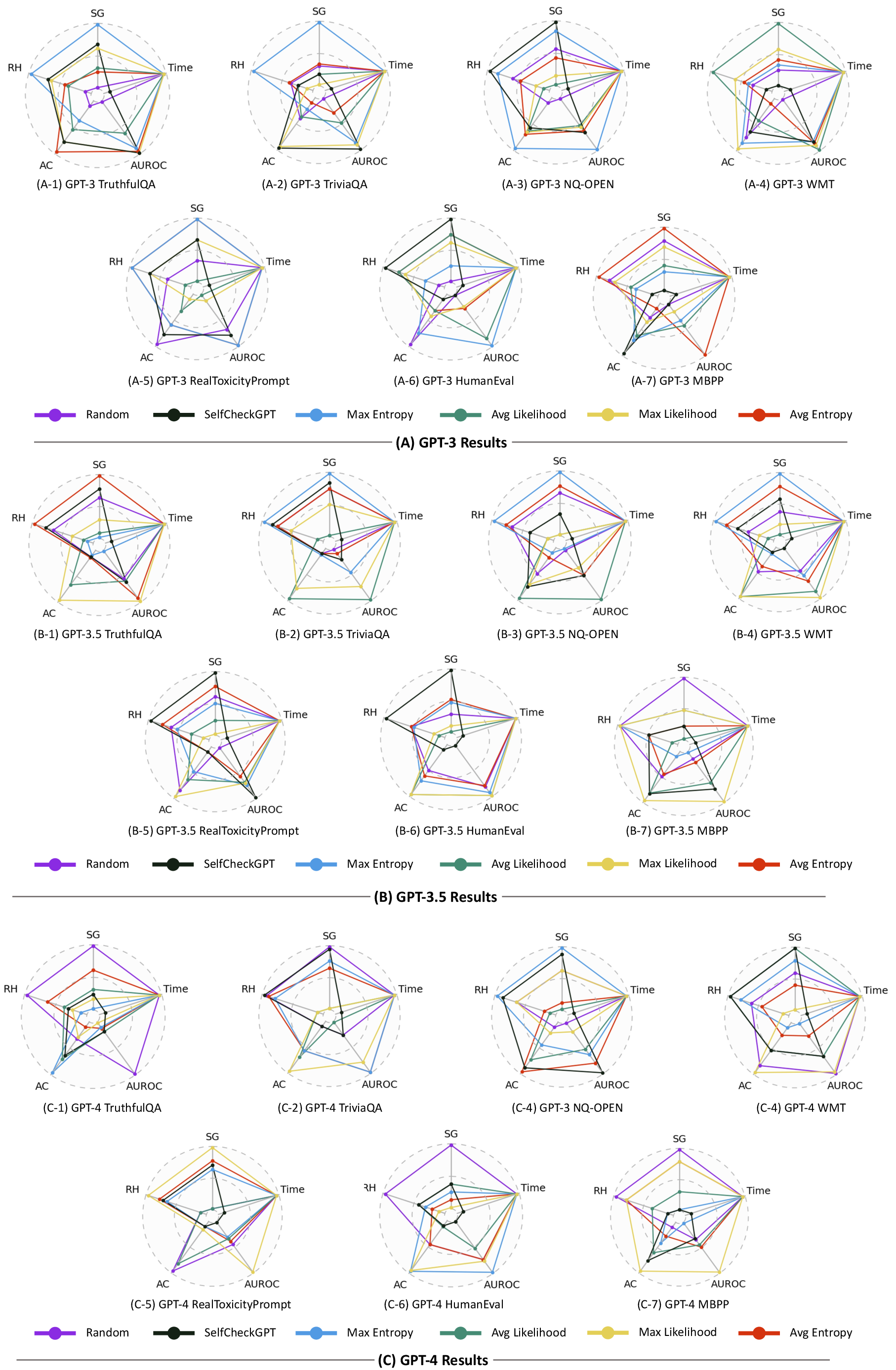
Empirical Evaluation of Online Safety Analysis Methods
The paper proceeds with an extensive empirical evaluation of the collected safety analysis methods across both open and closed-source LLMs.
Hybridization Approaches
The paper explores hybridization strategies to leverage the strengths of individual analysis methods. While hybrid methods showed potential in improving performance across multiple metrics, consistency remains a challenge. The research suggests future directions in developing sophisticated hybrid methodologies that can dynamically adapt based on task and model-specific characteristics.
Conclusion
The study presents a landmark examination of online safety analysis for LLMs, offering a robust benchmark and critical insights into the effectiveness of existing methods. This research not only highlights the importance of real-time safety assurance but also lays the foundation for developing innovative hybrid approaches. The findings advocate for ongoing exploration into LLM-specific safety strategies, emphasizing the adaptation and integration of safety measures into the deployment of LLMs across diverse domains.