- The paper introduces the EKRG framework, which leverages LLMs to generate document-question pairs and enhance QA performance with limited annotations.
- The retrieval module uses dense vector representations and instruction-tuned query generation to significantly outperform traditional methods like BM25.
- The generation module employs chain-of-thought fine-tuning to achieve higher EM, F1, BLEU, and ROUGE scores, ensuring factually accurate and contextually coherent responses.
Enhancing Question Answering for Enterprise Knowledge Bases using LLMs
This paper presents the EKRG framework, a novel method to enhance question-answering capabilities for enterprise knowledge bases using LLMs. The framework is designed to address challenges posed by limited annotated data in enterprise environments due to privacy constraints. It incorporates innovative retrieval and generation strategies that significantly improve document retrieval and response accuracy.
Introduction to EKRG Framework
The EKRG (Enterprise Knowledge Retrieval and Generation) framework leverages LLMs to efficiently generate document-question pairs and process user queries with minimal annotation costs. It combines instructional tuning, relevance-aware teacher-student learning, and chain-of-thought (CoT) fine-tuning to form a robust retrieval-generation system. The design goals emphasize generating factually comprehensive and contextually coherent answers from enterprise knowledge bases.
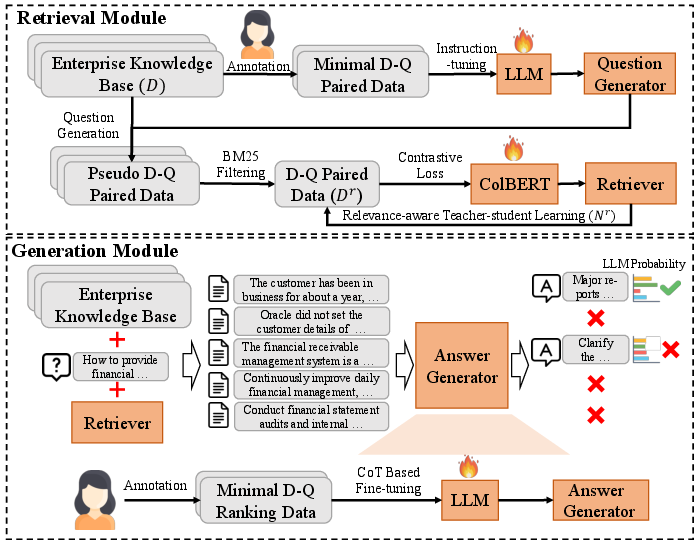
Figure 1: The illustration of EKRG framework.
Retrieval Module
The retrieval module, based on the ColBERT architecture, computes dense vector representations of queries and documents to enhance retrieval accuracy. A key innovation is using instruction-tuned LLMs to generate diverse document-question pairs, enabling efficient training of dense retrievers. The relevance-aware teacher-student strategy further boosts retrieval efficacy by dynamically selecting high-quality queries and minimizing training data requirements.
Generation Module
The generation module employs a CoT-based fine-tuning approach to refine the LLM's response generation capabilities. This methodology breaks down answer generation into intermediate steps, allowing the model to summarize documents, assess relevance, and formulate coherent answers based on retrieved content. This process effectively mitigates the issue of hallucinations common in LLMs when generating answers.
Experiment and Results Analysis
Extensive experiments conducted on real-world datasets demonstrate the effectiveness of the EKRG framework. Compared to traditional methods and recent LLM-based approaches, EKRG exhibits superior performance metrics in both retrieval and generation tasks, providing accurate and contextually relevant answers across different query categories.
EKRG outperforms traditional methods such as BM25 and novel data augmentation techniques like ICT and Inpars in terms of NDCG, MAP, and MRR across various datasets. The incorporation of LLM-generated queries through instructional tuning offers a substantial improvement in retrieval accuracy, especially for enterprise-specific data.
Generation Accuracy
In generation tasks, EKRG achieves higher Exact Match (EM) and F1 scores for factual questions while excelling in BLEU and ROUGE metrics for solution-oriented queries. The CoT-based fine-tuning allows for effective relevance assessment and answer synthesis, which enhances response accuracy and detail retention.
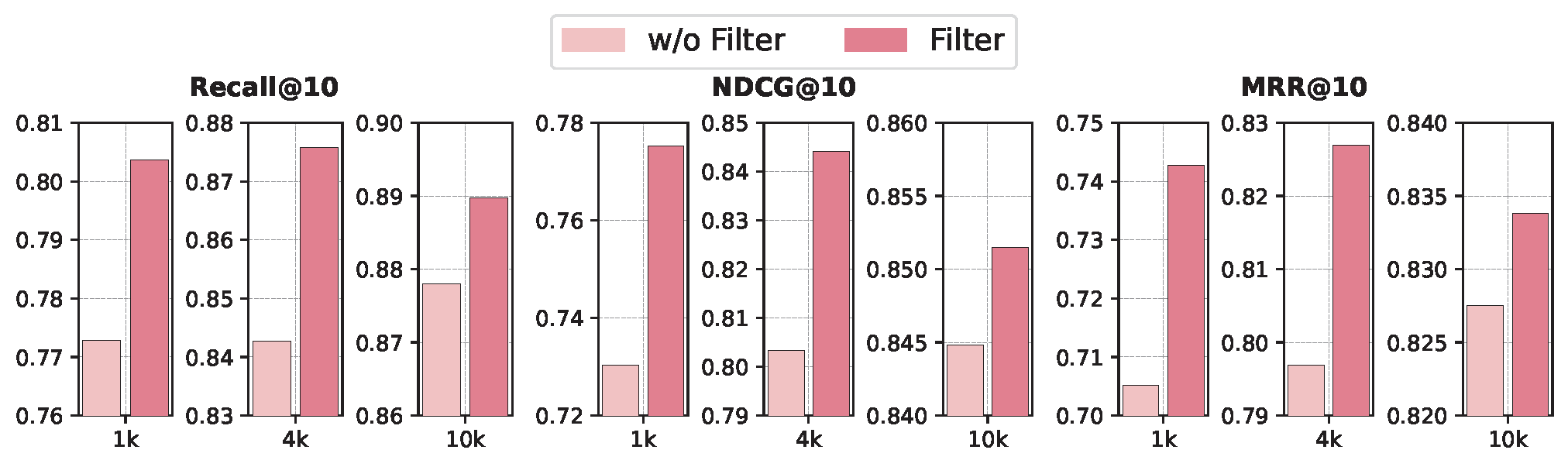
Figure 2: The results of ablation study on the high-quality query filtering.
Discussion: Implications and Future Directions
The EKRG framework presents impactful implications for knowledge management within enterprises, offering a scalable, privacy-compliant solution to enhance QA systems using minimal supervision. The combination of LLM-based learning strategies provides a foundation for future explorations into adaptive learning models for dynamic knowledge environments. Further research may explore refining CoT approaches and expanding EKRG's adaptability across diverse datasets and languages.
Conclusion
The EKRG framework represents a significant advancement in enhancing enterprise knowledge base question answering through LLMs. Its innovative retrieval and generation methodologies align closely with real-world constraints, offering meaningful improvements in QA system performance. The framework's ability to operate effectively with limited annotated data sets a benchmark for future research in the domain of enterprise knowledge management.