- The paper introduces a compositional world model that efficiently decomposes joint actions for accurate multi-agent simulation.
- It employs a dual-stage video diffusion model along with vision-language techniques for action proposal, intent tracking, and outcome evaluation.
- Experimental results demonstrate improved task success and interaction efficiency over traditional approaches in simulated environments.
COMBO: Compositional World Models for Embodied Multi-Agent Cooperation
Introduction
"COMBO: Compositional World Models for Embodied Multi-Agent Cooperation" introduces an innovative framework for tackling the challenges of multi-agent planning where agents must cooperate using partial observability. The paper proposes a compositional world model that factors joint actions into individual components, facilitating effective simulation of multi-agent world dynamics. This approach leverages vision-LLMs (VLMs) for action proposal, intention tracking, and outcome evaluation, enabling efficient online cooperative planning through a tree search procedure.
Compositional World Model
The compositional world model is the cornerstone of this research, providing a sophisticated generative mechanism to simulate multi-agent interactions based on joint actions. By decomposing joint actions into constituent parts and using video diffusion models for simulation, this model can accurately reflect the implications of each agent's actions on the world state.
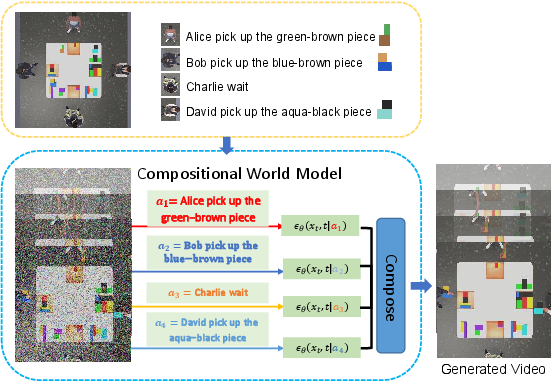
Figure 1: Compositional World Model. Factorization into agent-specific components that generate scores, later composed to produce the final video output.
Video diffusion models are trained to handle both single-agent and multi-agent conditions, using a dual-stage approach. The first stage focuses on learning individual agent actions, while the second stage emphasizes compositional generation. This dual-phase training ensures the model's versatility across varying agent configurations.
COMBO: Planning Framework
COMBO leverages the compositional world model alongside VLMs to address the problem of decentralized partially observable Markov decision processes. It employs VLMs for generating potential actions (Action Proposer), inferring competitor intents (Intent Tracker), and evaluating plan outcomes (Outcome Evaluator). The framework integrates these components through tree search to explore action sequences and select optimal plans.

Figure 2: COMBO's planning begins with reconstructing a top-down orthographic world state from partial observations.
World State Estimation
COMBO reconstructs the overall world state using partial egocentric views, combining them into a cohesive top-down orthographic representation. Diffusion models are used to clean and complete these representations, addressing observational noise and incompleteness.
Tree Search Procedure
The planning is conducted via a limited tree search approach, keeping a fixed number of plan beams and rollout depths to ensure computational efficiency. This process involves constant replanning to account for dynamic world changes and agent interactions.
Experimental Results
The framework is tested on tasks requiring extensive cooperation, such as TDW-Game and TDW-Cook, using the ThreeDWorld simulator. Results indicate that COMBO outperforms traditional approaches like MAPPO and Recurrent World Models in both task success and interaction efficiency.
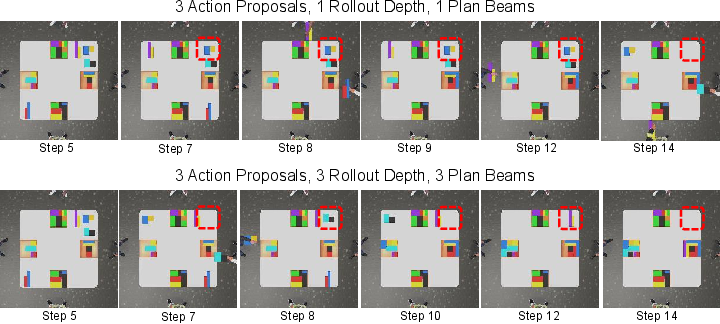
Figure 3: More Computation budgets result in better plans, as evidenced by task performance improvements with increased computational resources.
The compositional world model achieves high accuracy in simulating multi-agent dynamics, significantly outperforming other models like AVDC. The integration of agent-dependent loss scaling improves video synthesis accuracy, reinforcing the validity of the compositional approach.
Conclusion
COMBO's development of a compositional world model marks a significant stride in multi-agent planning by providing a scalable, adaptable framework for cooperation with arbitrary numbers of agents. While the reliance on computationally intensive generative models limits application in time-sensitive contexts, future improvements in model efficiency could expand its practicality. The strong numerical results in cooperative tasks demonstrate its potential for broader AI applications in complex, interactive environments.