- The paper introduces a retrieval-augmented generation framework that integrates knowledge graphs to enhance customer service question answering.
- It employs detailed intra- and inter-ticket parsing using pre-trained models like BERT and E5, achieving a 77.6% improvement in MRR.
- The system’s deployment at LinkedIn reduced median issue resolution time by 28.6%, underscoring its practical impact.
Retrieval-Augmented Generation with Knowledge Graphs for Customer Service Question Answering
Introduction
The paper introduces a technique leveraging retrieval-augmented generation (RAG) combined with knowledge graphs (KGs) to enhance customer service question-answering systems. Traditional RAG systems often reduce issue documents to plain text and ignore structural nuances present in issue tracking systems such as Jira. This approach integrates the structural and relational information within and between issue tickets by constructing a KG, thus ameliorating retrieval accuracy and enhancing the quality of generated answers.
Methodology
The proposed system involves the construction of a comprehensive knowledge graph from historical customer service tickets. This graph integrates intra-issue structures and inter-issue relations, maintaining critical links and hierarchical information. The system is designed to parse user queries, identify relevant entities and intents, and efficiently retrieve relevant subgraphs for generating answers.
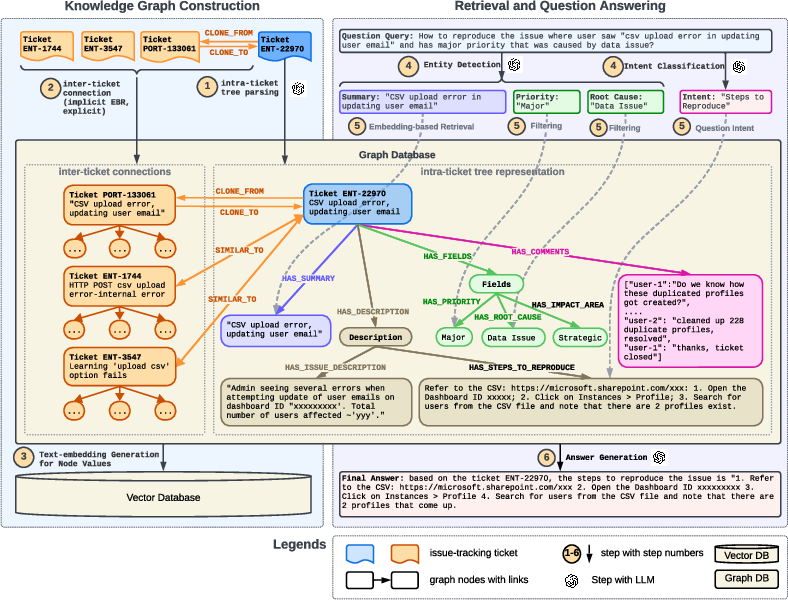
Figure 1: An overview of our proposed retrieval-augmented generation with knowledge graph framework. The left side of this diagram illustrates the knowledge graph construction; the right side shows the retrieval and question answering process.
Knowledge Graph Construction
The KG construction involves two primary phases: intra-ticket parsing and inter-ticket connection. During intra-ticket parsing, each support ticket is transformed into a tree structure, which preserves relational hierarchies within the ticket. Subsequently, these trees are interconnected using both explicit and semantic similarity-based implicit connections to form a global graph. Pre-trained models like BERT and E5 are employed to generate embeddings for textual content in graph nodes, supporting efficient semantic retrieval.
Query Processing and Retrieval
The system detects named entities and intents from user queries using LLMs, then retrieves pertinent subgraphs leveraging embedding-based retrieval methods. This dual-step retrieval process enhances the system’s capability to handle diverse and multi-faceted queries by identifying and correlating relevant historical issues stored in the KG.
Experimental Results
The system was evaluated using standardized measures such as MRR, Recall@K, NDCG@K for retrieval, and BLEU, ROUGE, METEOR for text generation. The proposed method showed remarkable improvements over baseline models, with a significant 77.6% increase in MRR and a 0.32 rise in BLEU scores. The system demonstrated substantial effectiveness, especially in scenarios requiring nuanced understanding and synthesis of information across multiple connected issues.
Production Deployment and Impact
Implementing this system in LinkedIn’s customer service operations led to a notable reduction in median issue resolution time by 28.6%. These improvements underscore the practical impact and efficiency gains achievable in real-world customer service contexts through advanced integration of KGs and RAG systems.
Conclusion
By incorporating a knowledge graph with retrieval-augmented generation, this study advances automated systems in customer support environments, delivering significant performance improvements in both retrieval accuracy and answer generation quality. Future research will explore automated KG template extraction, real-time KG updates, and broader applicability in varied organizational contexts. These advances remain promising steps towards developing adaptive, efficient, and contextually aware automated question-answering systems.