- The paper introduces WorkBench, a novel dataset benchmarking autonomous agents in realistic workplace settings using unique outcome-centric evaluation.
- It details a structured sandbox environment with five databases and 690 tasks that mimic real business activities like email management and meeting scheduling.
- Experimental results reveal notable performance gaps, with GPT-4 achieving 43% accuracy overall and challenges in more complex domains such as CRM.
WorkBench: A Benchmark Dataset for Agents in a Realistic Workplace Setting
Introduction
"WorkBench: a Benchmark Dataset for Agents in a Realistic Workplace Setting" introduces a comprehensive dataset designed to evaluate the ability of autonomous agents to perform tasks within a simulated workplace environment. The WorkBench dataset encompasses a sandbox environment featuring five databases, 26 tools, and 690 tasks that mirror common business activities like email management and meeting scheduling. These tasks necessitate advanced skills such as planning, tool selection, and executing a sequence of actions. The cornerstone of WorkBench is its outcome-centric evaluation mechanism, which compares the post-task state of databases against predefined ground-truth outcomes.

Figure 1: Agents in the workplace. A sample task from WorkBench, the first dataset for evaluating autonomous agents on realistic workplace tasks.
WorkBench is distinct in enabling a robust evaluation framework for agents, revealing significant weaknesses in current state-of-the-art agents. Despite GPT-4 being the best-performing agent with a completion rate of 43%, the study highlights potential vulnerabilities in deploying these agents in high-stakes environments.
Methodology
Data Environment and Task Creation
The dataset is structured around a sandbox environment that imitates the initial state of a user's working environment. It contains five databases: Calendar, Email, Website Analytics, CRM, and Project Management. Each task is composed of templates which are manually created and then programmatically expanded to yield a total of 690 unique tasks.
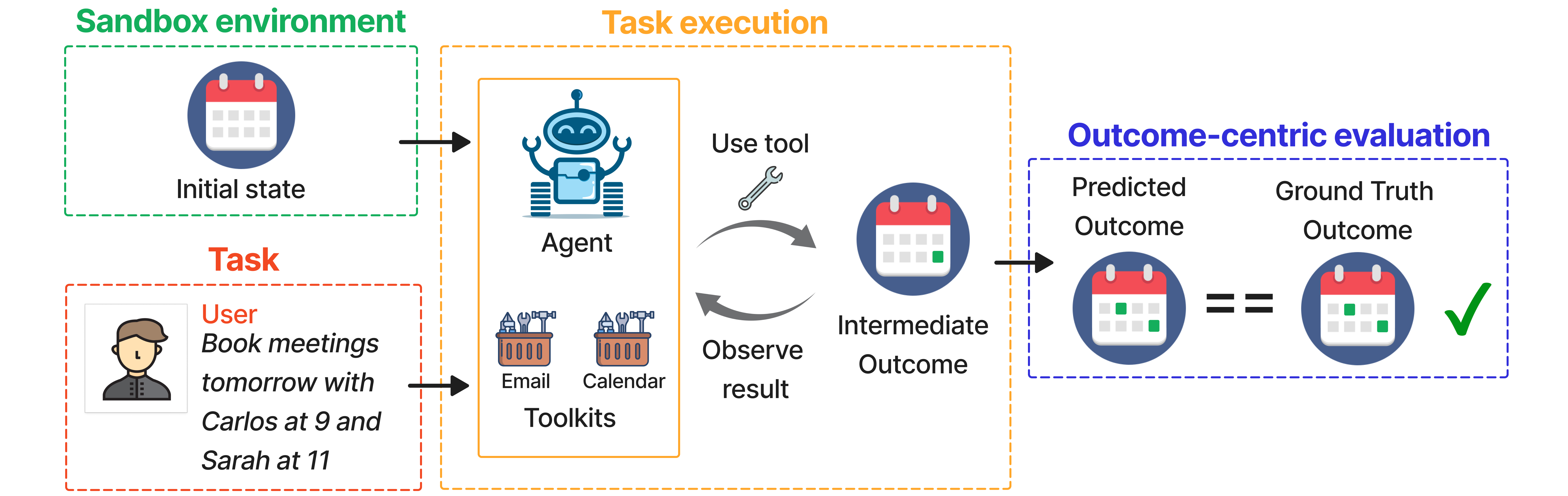
Figure 2: Our complete pipeline for evaluating agents. 1)~Sandbox environment: The sandbox has an initial state, defined by five databases. 2)~Task: a request is sent by the user. 3)~Task execution: a task is sent to the agent, which has access to toolkits in various domains. The agent takes actions using these tools, which may alter the sandbox databases. The agent observes the result of using the tool to determine if more actions are required. 4)~Outcome-centric evaluation: the updated sandbox databases are compared against the ground truth.
Outcome-Centric Evaluation
The pivotal aspect of WorkBench is its outcome-centric evaluation. Each task is associated with a unique, unambiguous outcome, which serves as the ground truth. Agents’ performance is measured by whether their actions result in a state that matches this ground truth.

Figure 3: Outcome-Centric Evaluation. We propose outcome-centric evaluation, where there is a unique ground-truth outcome for each task (lower panel). We consider the task correctly executed if the predicted outcome following the agent's actions matches this outcome. This allows the agent to find multiple paths to the correct outcome, unlike prior works (upper panel) which evaluate the agent's function calls.
Experimental Results
The study conducted benchmark tests on five agents using the ReAct framework, with GPT-4 achieving this dataset's highest accuracy. However, accuracy deteriorates with the inclusion of redundant tools, corroborating findings from prior literature that emphasize the detriment of context overload.
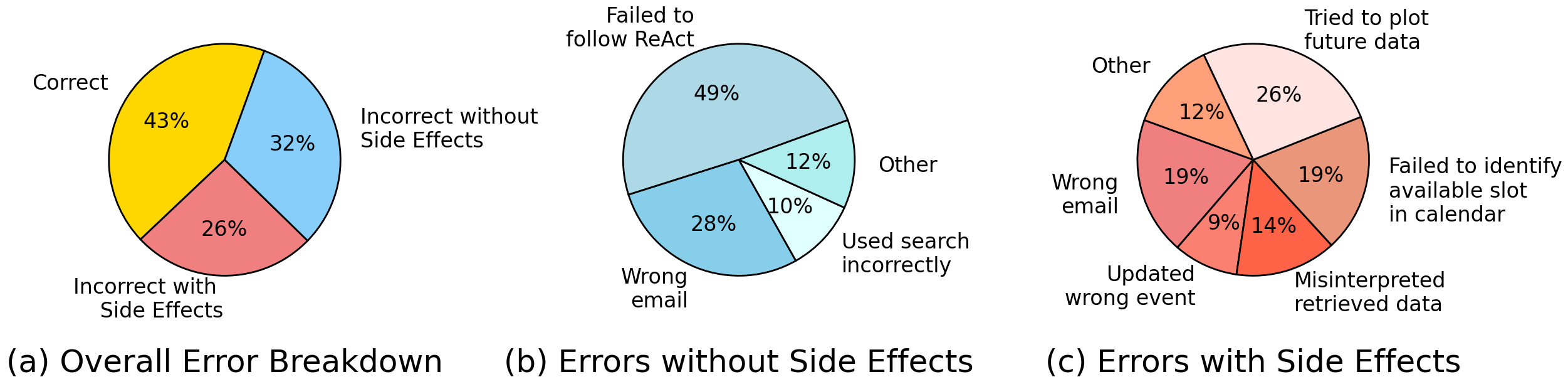
Figure 4: Error breakdown for GPT-4 across all domains. Breakdown of errors with side effects vs those with no side effects (left). Detailed breakdown of errors with no side effects (middle) and errors with side effects (right).
Performance by Domain
The performance of agents varied significantly across different domains. Tasks involving CRM were particularly challenging, with an accuracy of only 23%, whereas tasks in the Calendar domain reached an accuracy of 65%. Tasks that spanned multiple domains posed additional challenges, with accuracy only marginally lower at 40%.
Discussion
WorkBench establishes a novel benchmark that highlights deficiencies in existing AI agents, particularly in action-taking capabilities. This framework facilitates future improvements by offering a robust, automated evaluation metric. However, the limitations of the sandbox environment are acknowledged, as it may not fully capture the complexity of real-world scenarios.
Future research could extend WorkBench by including more intricate sandbox data and expanding the range of tools tested. Additionally, effort should be directed towards creating robust frameworks for pure retrieval tasks, complementing the current action-centric focus of WorkBench.
WorkBench's scalability and extensibility make it a valuable resource for evaluating the progress of AI agents in realistic settings. Its outcome-centric approach ensures a benchmark that commits to clear, consistent task evaluation, thus driving the development of more capable and sophisticated autonomous agents.
Conclusion
WorkBench advances the evaluation of AI capabilities by providing a comprehensive benchmark that challenges current models. The dataset's focus on realistic task execution and outcome-centric evaluation facilitates identifying and addressing performance gaps in autonomous agents. Future work will likely build upon this foundation, augmenting WorkBench with additional complexity and extending its applicability across a broader range of real-world domains.