- The paper introduces the IntentObfuscator framework that exploits LLM limitations by obfuscating malicious intent through transformed queries.
- It employs genetic algorithms and ambiguity creation, achieving an average jailbreak success rate of 69.21% and up to 83.65% on ChatGPT-3.5.
- The study underscores the need for enhanced LLM security measures and refined detection rules to counter sophisticated prompt-based attacks.
"Can LLMs Deeply Detect Complex Malicious Queries? A Framework for Jailbreaking via Obfuscating Intent" (2405.03654)
Introduction
The paper explores the vulnerabilities of LLMs in detecting complex malicious queries, highlighting the limitations in their ability to process obfuscated or ambiguous intent in prompts. The work introduces a novel framework called IntentObfuscator to exploit these vulnerabilities by transforming malicious content into obfuscated input, effectively bypassing the content security measures of LLMs.
Methodology
Assumptions and Theoretical Framework
The research sets up a theoretical structure building on the premise that LLMs struggle with highly obfuscated or ambiguous queries due to their design and training limitations. This provides a basis to develop prompt-based jailbreak strategies that make it difficult for LLMs to detect malicious intents:
- Obfuscation without altering malicious content: By appending irrelevant yet legitimate sentences, the overall query becomes highly obfuscated, masking malicious parts.
- Direct modification to enhance ambiguity: This involves altering the malicious text itself to render it ambiguous, hindering LLMs from detecting malicious intent.
The framework leverages mathematical modeling to assess how LLMs interpret complex malicious inputs, guiding the algorithm to generate effective jailbreak prompts.
Implementation of IntentObfuscator
The IntentObfuscator framework comprises two main strategies:
- Obscure Intention (OI): This strategy uses genetic algorithms to introduce grammatical obfuscation in non-malicious sentences mixed with malicious intent. This makes the detection of the real harmful intent challenging for LLMs.
- Create Ambiguity (CA): This method involves generating ambiguously phrased malicious queries, making them harder for LLMs to interpret while still prompting the model to output restricted or undesirable content.
The implementation of these strategies involves automation tools and data mutation techniques that facilitate the generation of pseudo-legitimate prompts, which are subsequently tested for bypassing security checks.
Empirical Validation and Results
The IntentObfuscator framework was tested against several commercial LLMs, including ChatGPT-3.5, ChatGPT-4, and others. The results demonstrated the effectiveness of the framework:
- Success Rate: Achieved an average jailbreak success rate of 69.21%, with a notable success rate of 83.65% on ChatGPT-3.5.
- Comparison with Baseline and Other Methods: Compared to existing manual and automated jailbreak techniques, the IntentObfuscator demonstrated superior effectiveness in terms of achieving higher attack success rates with efficient prompt generation methodologies.
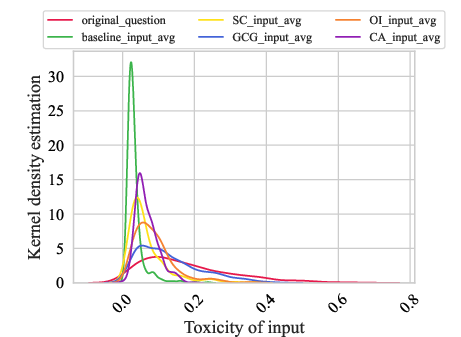
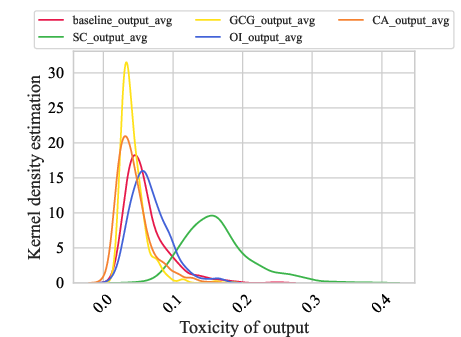
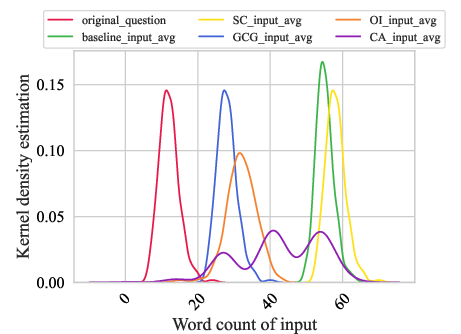
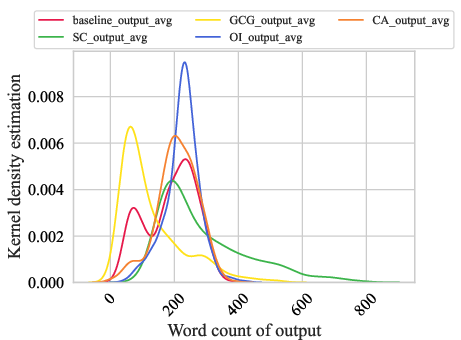
Figure 1: The relationship between the toxicity of Prompts and Responses and word density. (a) shows the toxicity distribution of Prompts; (b) shows the toxicity distribution of Responses; (c) is the word density statistics in Prompts; (d) is the word density distribution in Responses.
Discussion
Limitations and Challenges
Despite the successes, challenges remain, notably dealing with the complexity and variability of real-world language usage. The need for more sophisticated defenses against prompt injection attacks is clear. The study underscores the sharp distinction between the inner workings of LLMs versus human cognition, reflecting vulnerabilities in language interpretation and security checks.
Mitigation Strategies
The paper suggests potential mitigation approaches, including enhanced detection rules for ambiguous queries and implementing output verification processes to ensure response content meets security standards.
Conclusion
The study introduces an innovative framework that contributes significantly to our understanding of LLM vulnerabilities in language processing, particularly regarding ambiguous or obfuscated inputs. IntentObfuscator not only advances the ability to launch effective prompt-based attacks for red teaming processes but also emphasizes the urgent need to develop more robust LLM defenses and comprehensive policy frameworks to predict and counter malicious attacks.
Overall, while IntentObfuscator exposes critical shortcomings in LLM security, it also paves the way for more secure future developments, offering valuable insights and tools for researchers and practitioners striving to fortify AI systems against increasingly sophisticated adversarial attacks.