- The paper proposes a scalable method extending LIMs from 2D to 3D visual reasoning using the LV3D pretraining dataset.
- It employs chain-of-thought prompting and visual prompts to boost 3D grounding, outperforming benchmarks by notable margins.
- The research offers promising implications for autonomous driving and robotics, paving the way for advanced 3D perception.
Language-Image Models with 3D Understanding
The paper "Language-Image Models with 3D Understanding" (2405.03685) presents significant advancements in the domain of Multi-modal LLMs (MLLMs) potentially revolutionizing 3D visual reasoning. This work focuses on extending MLLMs' capabilities to process and understand visual information within a 3-dimensional space, showcasing improvements over traditional 2D limitations.
Introduction to 3D Grounded Reasoning
Language-Image Models (LIMs) have primarily dealt with 2D vision tasks, effectively bridging low-level perception with high-level reasoning akin to human cognition. However, human perception inherently operates within a 3-dimensional space, a context LIMs initially did not support. This research seeks to enhance LIMs beyond 2D capabilities by integrating 3D spatial comprehension.
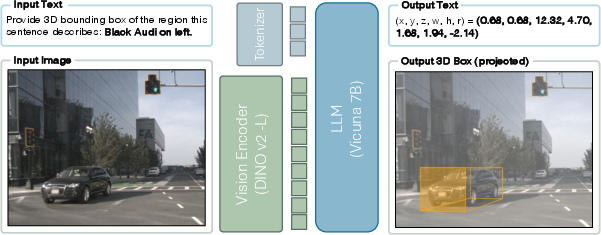
Figure 1: The overview of for 3D-grounded reasoning. The task requires a model to take an image, understand the input text prompt (e.g., ``Black Audi on left.'') and ground it in 3-dimensional space.
Development of LV3D Pretraining Dataset
The initiative introduces a large-scale pretraining dataset, LV3D, amalgamating various 2D and 3D recognition datasets under a unified framework through multi-turn question-answering formats. The approach leverages pure data scaling, eschewing specialized architectural alterations, hence displaying promising 3D perception capabilities.
Model and Approach
The newly developed MLLM exhibits capabilities similar to existing LLMs, including:
- Chain-of-Thought Prompting: The model applies sequential reasoning, beginning from 2D spatial context moving to 3D understanding.

Figure 2: Inference with prompting. Left: Visual Chain-of-Thought Prompting to reason in 3D step-by-step. Right: Incorporating specialist models to further improve localization.
- Versatile Format Adaptation: Capable of processing diverse instructions, the MLLM adapts to various input/output formats, a beneficial attribute for navigation and problem-solving tasks.
- Visual Prompts Integration: Utilization of pre-trained specialist models to enhance localization and 3D grounding.
Experiments and Benchmark Results
Experiments underscore the model's efficacy across multiple outdoor benchmarks. Notably, it outstrips traditional LIM baselines in the Talk2Car dataset by 21.3 points in APBEV for grounded reasoning performance and 17.7 on DriveLM in complex driving scenario reasoning.

Figure 3: Qualitative results of 3D grounding in 3 aspects: open-vocabulary understanding (top), complex reasoning (middle), and 3D spatial understanding (bottom).
Additional evaluations were conducted on standard benchmarks like refCOCO for 2D grounding and diverse visual question-answering datasets such as VQAv2, demonstrating competitive performance.
Implications and Future Directions
This research sets the stage for significant advancements in the practical utility of LIMs, paving the way for enhanced applications in autonomous driving and robotics, where understanding 3D spatial layouts is crucial. Future work could explore extending capabilities using high-resolution inputs and incorporating temporal data for dynamic environments.
Conclusion
The paper effectively pioneers 3D scene understanding within LIMs using scalable data-driven methods. While limitations remain—such as needing adjustments for single-frame inputs—the foundational work provides vital insights into the future versatility and applicability of MLLMs in 3D reasoning tasks.