- The paper proposes Cross-Layer Attention (CLA), which shares key-value activations across layers to achieve a 2× reduction in memory usage.
- It demonstrates through experiments on 1B and 3B scale models that CLA integrated with MQA maintains accuracy while considerably reducing the KV cache size.
- The findings offer practical implications for deploying memory-efficient transformers in resource-constrained environments.
Introduction
The study presented in the paper "Reducing Transformer Key-Value Cache Size with Cross-Layer Attention" addresses a significant challenge in the application of autoregressive LLMs: managing the memory footprint of the key-value (KV) cache during decoding. This component is crucial for efficient model performance, especially at long sequence lengths and large batch sizes, where memory demands can become prohibitive. Traditional approaches like Multi-Query Attention (MQA) and Grouped-Query Attention (GQA) have laid the groundwork for reducing memory use by sharing key/value heads across query heads within an attention layer. This paper proposes an advancement by introducing Cross-Layer Attention (CLA), which extends this concept of sharing across adjacent layers, thus aiming to achieve further reductions in memory usage while maintaining accuracy.
Cross-Layer Attention Overview
Cross-Layer Attention (CLA) innovatively modifies the transformer architecture by allowing KV activations to be shared among layers rather than just within layers, as was the case with MQA. This sharing manifests in reduced unique KV heads per token, providing significant memory savings. The CLA mechanism is particularly compatible with traditional transformers and can be integrated with existing MQA or GQA architectures.
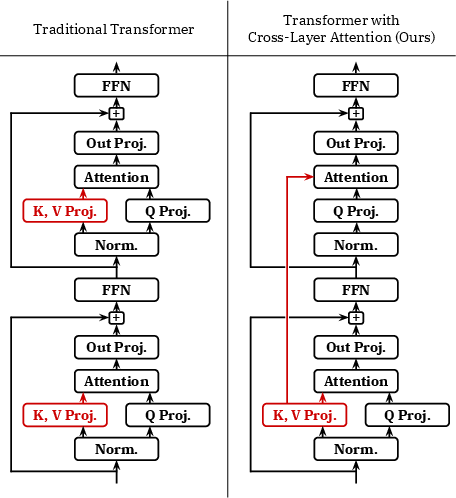
Figure 1: Schematic of two consecutive layers in a transformer using a traditional attention design and Cross-Layer Attention.
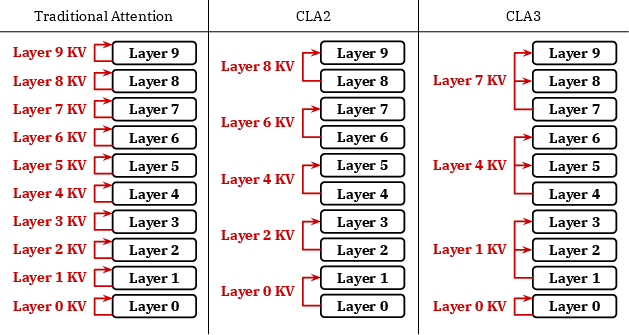
Figure 2: Schematic of KV cache structures under different attention configurations in a 10-layer transformer.
Experimental Results
Extensive experimentation at 1B and 3B parameter scales demonstrates that CLA achieves notable improvements in the memory/accuracy Pareto frontier, reducing the KV cache size considerably. Specifically, the integration of CLA with MQA facilitates a 2× reduction in storage compared to MQA alone, without significant accuracy loss. This advantage becomes particularly concrete when applied at varying scales and learning rates.
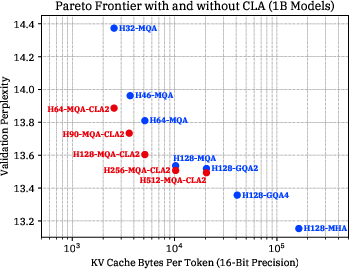
Figure 3: The accuracy/memory Pareto frontier for models with CLA (red) and without CLA (blue). Lower is better on both axes.
Theoretical and Practical Implications
The introduction of CLA holds practical implications for deploying memory-efficient LLMs capable of handling larger batch sizes and longer sequence lengths. It suggests a viable path for optimizing transformer models in resource-constrained environments, especially where memory bandwidth and latency are critical concerns. Theoretically, CLA broadens the scope for future research into attention mechanisms that balance computational efficiency with model performance.
Conclusion
Cross-Layer Attention represents a crucial step forward in the evolution of efficient transformer architectures, providing significant memory savings with minimal impact on model accuracy. By advancing the memory/accuracy tradeoffs of transformer models, CLA offers a promising direction for optimizing large-scale LLMs, potentially enabling more capable and efficient AI systems in the future.
This study presents a detailed analysis and experimentation demonstrating CLA's potential for enhancing transformer models' efficiency, marking its relevance for both theoretical advancements and practical applications in AI deployments.