- The paper introduces a novel mixture of noise levels that enables task-agnostic training for robust, multimodal audiovisual synthesis.
- It leverages vectorized noise scheduling within a transformer backbone to efficiently capture temporal dependencies and cross-modal interactions.
- Experiments demonstrate significant improvements in audiovisual coherence and synthesis quality across diverse datasets and generative tasks.
Introduction
This paper presents a general-purpose framework for audiovisual sequence generation based on diffusion models, entitled the Audiovisual Diffusion Transformer (AVDiT) with Mixture of Noise Levels (MoNL) (2405.13762). The approach introduces a novel, modality- and temporally-variant noise scheduling technique for training a single model across a diverse set of conditional distributions in the joint audio-video latent space. Unlike prior methods that require task-specific models or rely on inference-time tricks for conditional sampling, the MoNL paradigm enables task-agnostic training and efficient inference for arbitrary conditional and joint generation modes, including cross-modal audio-to-video (A2V), video-to-audio (V2A), multimodal interpolation, and joint unconditional sampling.
Model Architecture and Training Paradigm
The core innovation is to parameterize diffusion timesteps as a vector rather than a scalar, enabling noise to be injected at different intensities for each time-segment and each modality within the input sequence. This mixture of noise levels facilitates the learning of arbitrary conditionals, as different substructures of the input (across time or between modalities) can remain clean or be noised per training instance. During training, different "timestep assignment strategies" (vanilla, per-modality, per-time, per-modality-per-time) are randomly sampled, thus exposing the model to all possible partial conditioning regimes.
To address the generative and computational complexity of high-dimensional audiovisual signals, AVDiT operates in a compressed latent space. Video data is encoded by MAGVIT-v2 and audio by SoundStream, producing temporally aligned, low-dimensional continuous representations. The network backbone is a transformer that jointly predicts noise over this multimodal latent sequence. Transformer-based parameterizations are adopted due to their ability to capture both short- and long-range dependencies and complex cross-modal interactions.
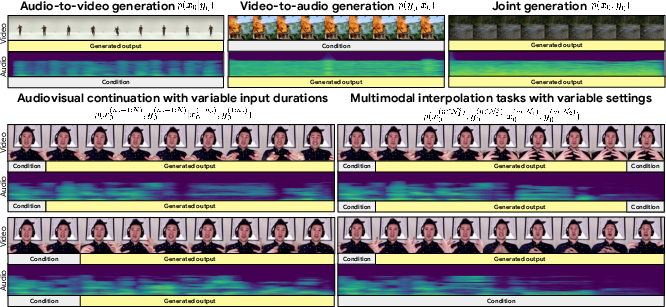
Figure 1: The AV-Diffusion Transformer, with Mixture of Noise Levels, enables a single model to handle a wide array of cross-modal and multimodal generation tasks.
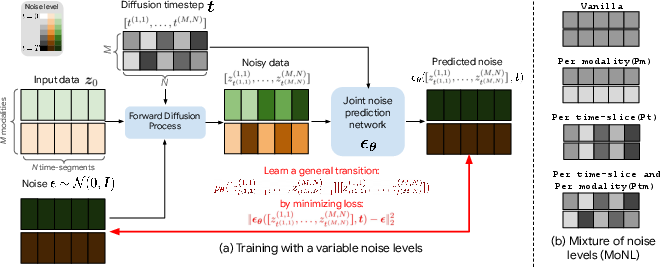
Figure 2: Training schematic illustrating how variable noise levels are applied per time-segment and per modality, creating diverse mixtures of noise across audiovisual inputs.
Conditional Sampling and Task Flexibility
The vectorized noise schedule enables natural support for conditional or joint inference without the need for bespoke sampling adjustments. At inference time, different conditioning configurations are realized by injecting noise into the desired modalities/time-segments and keeping others at zero noise (i.e., observed/clean). For example, in A2V generation, video segments are noised with a normal diffusion process while audio segments are kept fixed. This approach is extendable to multimodal interpolation or partial conditioning, enabling highly granular generation scenarios spanning both modalities and temporal partitions.

Figure 3: Comparison of conditional AV-continuation for MM-Diffusion (left) and AVDiT (right); AVDiT exhibits superior temporal consistency and cross-modal coherence.
Experimental Results
Comprehensive experiments spanning large-scale (Monologues: 19.1M AV samples), human-centric (AIST++), and landscape (natural scene) datasets demonstrate the versatility and efficacy of MoNL-trained AVDiT. Across tasks—joint, A2V, V2A, inpainting, and AV continuation—the proposed method exhibits:
- Statistically significant improvements in Fréchet Video Distance (FVD) and Fréchet Audio Distance (FAD) against vanilla joint diffusion, per-modality models, task-specific conditional models, and the prior state-of-the-art MM-Diffusion baseline based on a coupled UNet.
- For AV-continuation and inpainting (multimodal interpolation), only the MoNL-based approach achieves consistently low FAD/FVD, with models trained using fixed-noise (vanilla) or per-modality schedules showing high temporal or perceptual degradation.
- Human studies reveal strong subjective preferences for MoNL samples in terms of audiovisual alignment and subject consistency, especially for tasks requiring long-range temporal dependency (e.g., video continuation, maintaining speaker identity during speech/video synthesis).
- Notably, on certain cross-modal tasks the per-modality scheme performs well, yet cannot capture complex temporal dependencies required for inpainting or unconstrained continuation.
Theoretical and Practical Implications
By moving beyond fixed and homogeneous noise scheduling in multimodal diffusion frameworks, AVDiT's MoNL provides a scalable mechanism for unified training and inference across an extensive set of AV generative tasks. The approach avoids the combinatorial explosion associated with training a conditional model per input/output modality configuration and obviates the need for task-specific inference heuristics or auxiliary classifier paths. The training paradigm is robust and easily extensible to other modalities (e.g., text, sensor data) due to the vectorized, compositional nature of the noise schedule.
From a practical perspective, the resulting system is highly modular. The ability to use off-the-shelf autoencoders in tandem with a transformer diffusion model greatly reduces computational requirements (e.g., compared to pixel-space or frame-wise approaches) and increases flexibility in deployment for content creation, video synthesis, and generative AV editing tasks. The model produces temporally coherent video, avoids major perceptual glitches in cross-modal and interpolation scenarios, and robustly maintains subject/appearance consistency—major challenges in previous architectures.
Future Directions in AI and Multimodal Generation
The implications of the MoNL paradigm are wide-ranging for multimodal generative modeling. Notably:
- The compositional flexibility afforded by vectorized noise could facilitate conditional modelling in higher-order multi-modality domains (e.g., language–visual–audio triads).
- The transformer backbone, demonstrated in this context for video+audio latency, is likely extensible to even longer-term sequence modeling and scaling to higher resolutions using hierarchical or multi-stage transformers.
- The training paradigm could serve as a blueprint for universal multi-task generative modeling where model capacity is shared across diverse generative and inpainting/imputation functions.
- Classifier-free guidance is supported naturally by the MoNL construction, suggesting broader implications for controllable content generation.
There remain open questions regarding optimizing the mixing strategies for even more specialized tasks, incorporating text or symbolic control, and aligning model behavior with human perceptual expectations in complex multimodal settings. Integrating this explicit noise control with language-driven conditionality or third-party alignment/verification modules offers a promising trajectory for next-generation controllable multimedia generation systems.
Conclusion
The AVDiT with MoNL establishes a principled, versatile architecture for audiovisual generative modeling, supporting a comprehensive spectrum of conditional and unconditional generation tasks within a single transformer-based diffusion framework. By harnessing mixture-of-noise scheduling at the training stage, the approach bypasses the inflexibility and inefficiency of prior multi-conditional schemes, achieving strong empirical and subjective performance for temporally consistent, perceptually faithful audio-video synthesis tasks. This methodology sets the stage for further exploration of unified, scalable diffusion strategies across the multimodal generative modeling landscape.