Real-Time and Accurate: Zero-shot High-Fidelity Singing Voice Conversion with Multi-Condition Flow Synthesis
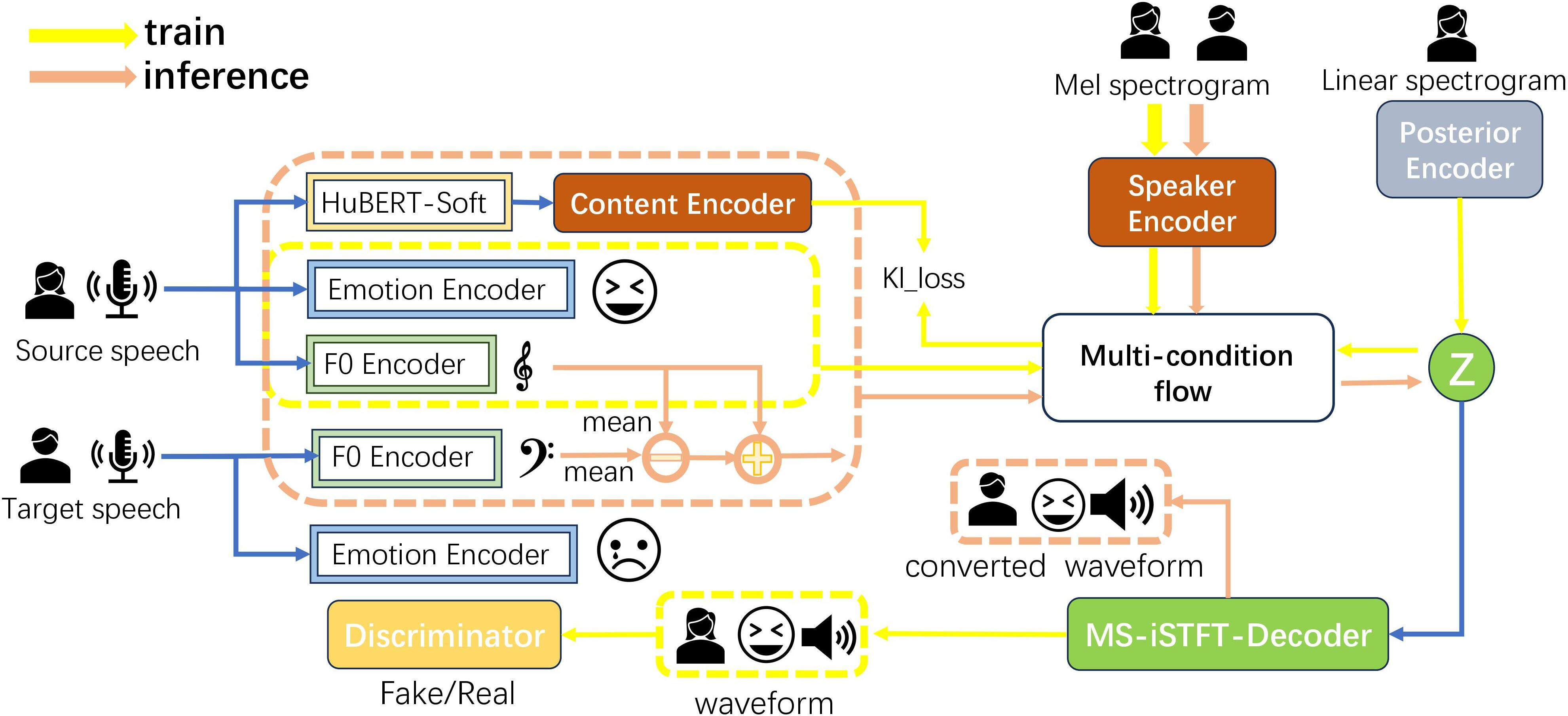
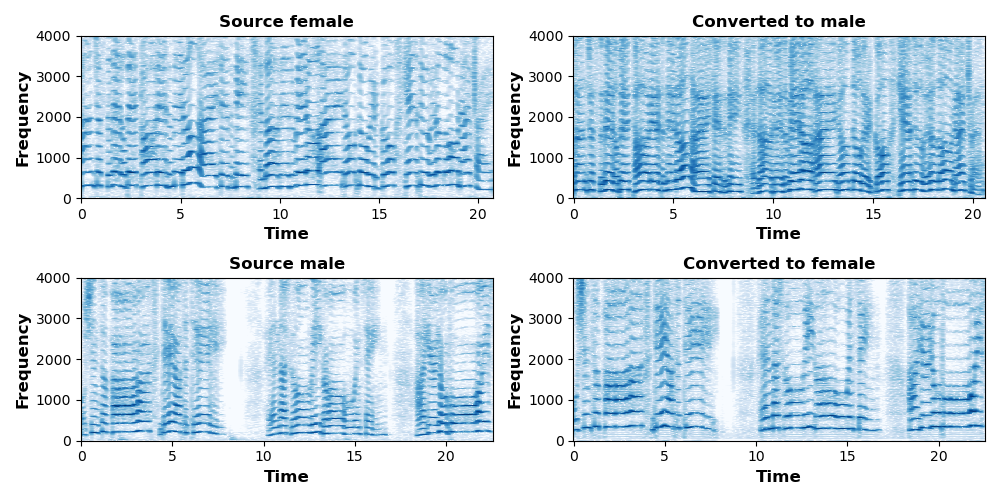
Abstract: Singing voice conversion is to convert the source singing voice into the target singing voice except for the content. Currently, flow-based models can complete the task of voice conversion, but they struggle to effectively extract latent variables in the more rhythmically rich and emotionally expressive task of singing voice conversion, while also facing issues with low efficiency in speech processing. In this paper, we propose a high-fidelity flow-based model based on multi-decoupling feature constraints called RASVC, which enhances the capture of vocal details by integrating multiple latent attribute encoders. We also use Multi-stream inverse short-time Fourier transform(MS-iSTFT) to enhance the speed of speech processing by skipping some complicated decoder processing steps. We compare the synthesized singing voice with other models from multiple dimensions, and our proposed model is highly consistent with the current state-of-the-art, with the demo which is available at \url{https://lazycat1119.github.io/RASVC-demo/}.
- W.-C. Huang, L. P. Violeta, S. Liu, J. A. Polyak, L. Wolf, Y. Adi, and Y. Taigman, “Unsupervised Cross-Domain Singing Voice Conversion,” unpublished.
- H. Guo, H. Lu, N. Hu, C. Zhang, S. Yang, L. Xie, D. Su, and D. Yu, “Phonetic Posteriorgrams based Many-to-Many Singing Voice Conversion via Adversarial Training,” unpublished.
- K.-W. Kim, S.-W. Park, J. Lee, and M.-C. Joe, “ASSEM-VC: Realistic Voice Conversion by Assembling Modern Speech Synthesis Techniques,” in Proc. ICASSP, pp. 6997–7001, 2022. doi: 10.1109/ICASSP43922.2022.9746139.
- B. Sha, X. Li, Z. Wu, Y. Shan, and H. Meng, “Neural Concatenative Singing Voice Conversion: Rethinking Concatenation-Based Approach for One-Shot Singing Voice Conversion,” in Proc. ICASSP, Seoul, Korea – Republic of,pp. 12577–12581, 2024.doi: 10.1109/ICASSP48485.2024.10446066.
- A.Tjandra,S.Sakti,andS.Nakamura,”Transformer VQ-VAE for Unsupervised Unit Discovery and Speech Synthesis: ZeroSpeech 2020 Challenge ,”unpublished.
- R.Kumaretal., ”High-Fidelity Audio Compression with Improved RVQGAN,”unpublished.
- T. Toda and K. Tokuda, “A speech parameter generation algorithm considering global variance for HMM-based speech synthesis,”unpublished.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.