- The paper introduces TAGA, a novel self-supervised framework that integrates graph and text views for TAG representation learning.
- It employs a structure-preserving random walk and dual view alignment to efficiently capture both semantic and structural information in large graphs.
- Experimental results across eight datasets demonstrate robust zero-shot and few-shot performance, highlighting superior transfer learning capabilities.
TAGA: Text-Attributed Graph Self-Supervised Learning
Introduction
The paper proposes a novel framework, TAGA, which addresses the challenges of unsupervised representation learning in Text-Attributed Graphs (TAGs). TAGs combine graph structures with textual data, allowing for a nuanced representation of data and their relationships. Most previous approaches to TAG representation learning rely on supervised methods, which require extensive labeled datasets and are often limited to specific tasks and domains. TAGA overcomes these limitations by applying self-supervised learning to integrate both structural and semantic dimensions of TAGs.
Methodology
The core of TAGA involves two complementary views: Graph-of-Text and Text-of-Graph.
- Graph-of-Text View: This constructs graph-structured data from the individual text corpora (Figure 1, left). This view facilitates the representation of textual nodes and their semantic connections as a graph.
- Text-of-Graph View: This organizes the text nodes with their connection descriptions in a hierarchical document layout (Figure 1, right). It provides a structured way to represent nodes and their relationships textually, enabling LLMs to process it effectively.
These two views are mutually transformable, which allows them to guide and align each other's representations (Figure 1).
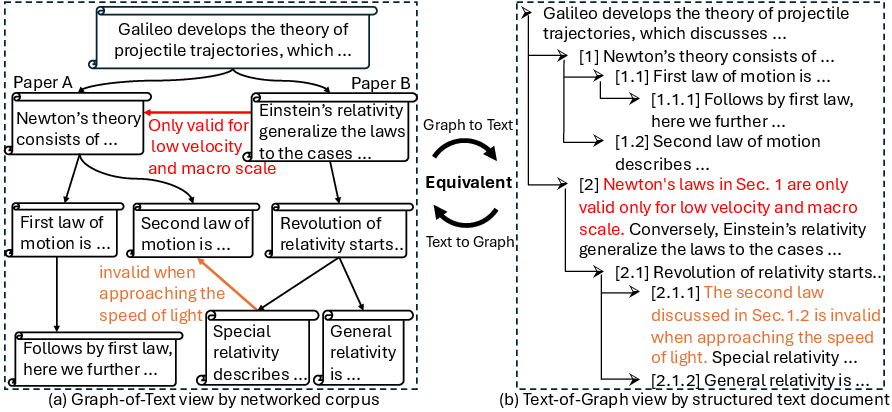
Figure 1: Illustration of the two distinct views of TAGs: (left) Graph-of-Text and (right) Text-of-Graph. Graph-of-Text view constructs a graph-structured data over the individual text corpora, while Text-of-Graph view organizes the text node and their connection description in a hierarchical layout document.
TAGA employs a novel structure-preserving random walk algorithm that optimizes the training process by efficiently capturing and preserving neighborhood structure in large-sized TAGs (Figure 2).
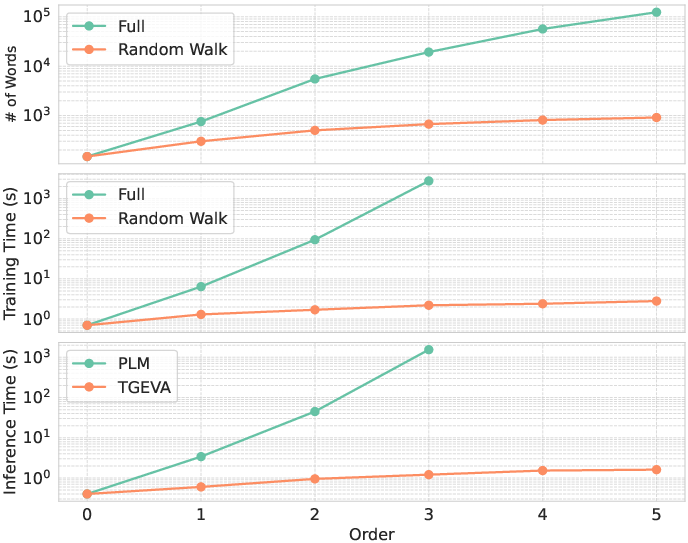
Figure 2: (top) Comparison of the full method and the random walk algorithm in terms of the number of words, and (middle) training time, and (bottom) inference time comparison between PLM and TAGA in terms of the number of hops.
Experimental Results
The efficacy of TAGA is demonstrated across eight real-world datasets, showing robust performance in zero-shot and few-shot scenarios. The paper presents extensive experimental results to validate the effectiveness of TAGA and its scalability. When deep models trained under TAGA were tested against traditional methods, they showed significant improvements, especially in domains where labeled data is scarce.
The design of the self-supervised learning framework allows the use of large pre-trained LLMs (PLMs) for Graph-to-Text transformation, preserving both semantic and structural information within the TAGs, while ensuring computational efficiency.
Technical and Practical Implications
- Performance: TAGA aligns representations from the two views to capture joint textual and structural information, leading to superior performance in various tasks.
- Scalability: The integration of structure-preserving random walk and hierarchical document layout ensures efficient and scalable representation learning on large graphs.
- Transfer Learning: TAGA's joint view alignment facilitates strong transfer learning capabilities, enabling models to generalize well across different tasks and domains.
Conclusions
TAGA introduces a transformative approach to TAG representation learning by leveraging self-supervised techniques and synergizing graph and text transformations. The results show that TAGA can significantly improve the representation of TAGs, maintaining efficiency and effectiveness across diverse applications and datasets. Future research may focus on further enhancing its domain adaptability and exploring broader applications of TAGs in complex real-world systems.