- The paper introduces CSL, a novel method that re-weights token logits using attention values to generate more reliable confidence scores.
- It demonstrates significant improvements in AUROC and AUARC metrics across datasets like CoQA, TriviaQA, and Natural Questions.
- The method enhances NLG reliability and paves the way for advanced applications in question answering and automated fact-checking.
Overview of Contextualized Sequence Likelihood
The paper "Contextualized Sequence Likelihood: Enhanced Confidence Scores for Natural Language Generation" (2406.01806) explores an improvement in measuring the reliability of LLMs in natural language generation (NLG) tasks. It proposes Contextualized Sequence Likelihood (CSL) as a refined method for evaluating the confidence in generated sequences, addressing the shortcomings of conventional sequence likelihood scores by integrating attention weights into the computation process.
Introduction and Motivation
Recent advancements in LLMs have significantly improved the capabilities of NLG systems. Yet, understanding the reliability and confidence in these generative processes remains a challenge. Traditional methods often rely on sequence likelihood, a measure conflating semantic and syntactic components, which can lead to unreliable confidence scores. The paper argues that each token's significance should vary based on the context, underscoring the need for a method that prioritizes semantically critical tokens over syntactic ones.
Methodology: Contextualized Sequence Likelihood
Sequence Likelihood
Sequence likelihood traditionally acts as a proxy for model confidence, leveraging the predicted probability of the generated sequence. It is computed as the sum of the logits for each token, normalized by sequence length to account for the typical biases against longer sequences.
Incorporating Attention Weights
CSL introduces a novel approach by re-weighting token logits using attention values extracted from the LLMs during generation. The attention mechanism helps identify which parts of the generated sequence should be emphasized, offering a more context-sensitive assessment of correctness. To implement CSL, a prompt is designed to elicit the model's focus on relevant aspects of a response, optimizing the weights applied to each token. The identification of particularly relevant attention heads, those that most effectively correlate with accurate predictions, is crucial in this process.
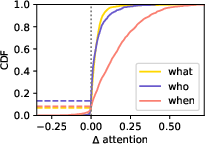
Figure 1: Depending on the question, the attention-eliciting prompt introduced in \cref{fig:prompt_short} induces different attentional focuses.
Results and Evaluation
The paper evaluates CSL across multiple datasets, including CoQA, TriviaQA, and Natural Questions, demonstrating that CSL outperforms traditional likelihood-based scores and other baseline uncertainty measures. The CSL method shows robust improvements in both AUROC and AUARC metrics when predicting the accuracy of generated responses, highlighting its efficacy in improving the reliability of NLG processes.
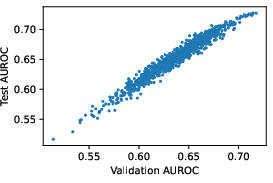
Figure 2: Scatter plot of test vs validation AUROC for confidence measures computed via \cref{eq:main}.
Additionally, CSL's attention mechanism shows high correlation across different methods of attention extraction, suggesting its reliability and effectiveness in focusing on semantically critical tokens irrespective of variances in prompt designs.
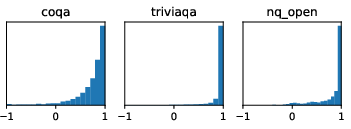
Figure 3: Histogram of the correlation between attentions from CSL and CSL-Next (top 10 heads' average).
Implications and Future Directions
The introduction of CSL has significant implications for enhancing the reliability of LLMs in various applications. By providing a more contextualized understanding of generated sequences, CSL has the potential to improve tasks such as selective question answering, risk assessment, and automated fact-checking. Future research could explore alternative mechanisms to refine the interpretability of attention weights or extend the approach to other LLM applications beyond NLG.
Furthermore, while CSL incorporates contextual weighting effectively, there remains room for further integration of external models for fact-checking or calibration, which could provide additional layers of validation to NLG outputs. This suggests a promising avenue for deriving multi-model or ensemble approaches to uncertainty quantification in machine learning.
Conclusion
The paper contributes a robust methodology for enhancing confidence scoring in natural language generation, addressing the inherent limitations of sequence likelihood measures. The CSL framework demonstrates higher predictive accuracy and reliability through leveraging contextual attention, underscoring its utility in evaluating and improving LLM performance across diverse NLG challenges. As the field of NLG continues to evolve, incorporating attention-focused methodologies like CSL may become foundational in developing more accurate and trustworthy artificial intelligence systems.