- The paper introduces Vision-LSTM by adapting xLSTM for vision tasks with alternating mLSTM blocks to effectively capture spatial relationships in image patches.
- ViL employs a novel bidirectional mLSTM approach that processes image patches in opposing directions, enhancing contextual understanding and feature transfer.
- Experiments on ImageNet-1K, ADE20K, and VTAB-1K demonstrate that ViL achieves competitive performance and robust downstream task generalization.
Vision-LSTM: xLSTM as Generic Vision Backbone
This paper introduces Vision-LSTM (ViL), a novel adaptation of the xLSTM architecture for computer vision tasks (2406.04303). ViL leverages the strengths of xLSTM, initially designed for language modeling, and extends them to process image data efficiently. The core innovation lies in employing a stack of alternating mLSTM blocks that process image patches in opposing directions, enabling the model to handle non-sequential image data effectively.
ViL Architecture and Implementation
ViL's architecture is built upon the xLSTM block, incorporating modifications to suit the characteristics of image data. The input image is divided into non-overlapping patches, similar to the Vision Transformer (ViT) approach [dosovitskiy2021vit]. These patches are then linearly projected into a sequence of patch tokens, and learnable positional embeddings are added to each token to retain spatial information.
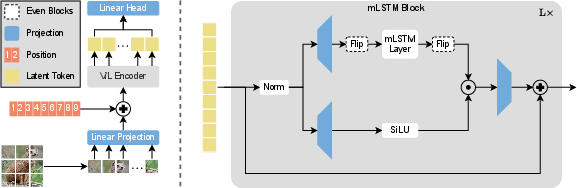
Figure 1: Schematic overview of Vision-LSTM (ViL) detailing the patch splitting, linear projection, positional encoding, and alternating mLSTM block processing.
The key component of ViL is the alternating mLSTM blocks. Odd-numbered blocks process the sequence of patch tokens row-wise from top left to bottom right, while even-numbered blocks process the sequence in the reverse direction. This bidirectional processing allows ViL to capture contextual relationships between different image regions effectively. The authors explore different traversal paths in their block design study (Figure 2). This design choice enables ViL to efficiently process non-sequential inputs like images without introducing additional computational overhead.
Experimental Results and Analysis
The paper presents comprehensive experimental results demonstrating ViL's performance on several benchmark datasets. ViL models were pre-trained on ImageNet-1K and subsequently evaluated on downstream tasks, including semantic segmentation on ADE20K and transfer classification on VTAB-1K.
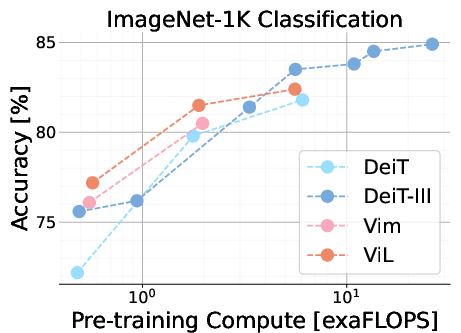
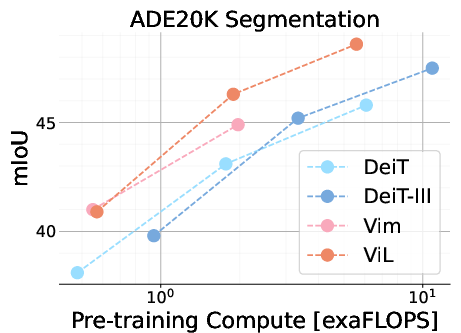
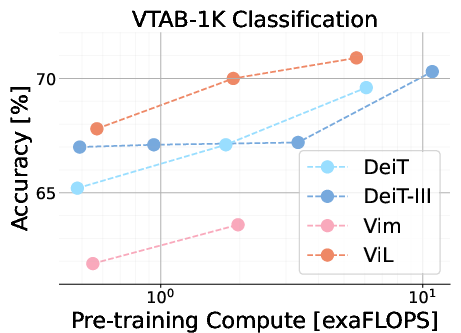
Figure 3: Performance overview of ImageNet-1K pre-trained models in relation to pre-training compute, highlighting ViL's strong performance across classification and semantic segmentation tasks.
The results indicate that ViL achieves competitive performance compared to established vision architectures like DeiT and Vision Mamba, particularly on the tiny and small scales. While ViL's performance on ImageNet-1K classification at the base scale does not surpass all other models, its downstream task performance suggests that ViL learns robust and transferable features. Specifically, ViL demonstrates strong performance on the VTAB-1K benchmark, outperforming other models in the structured datasets category. In semantic segmentation tasks using ADE20K, ViL exhibits strong performance, even outperforming DeiT-III-B despite having lower ImageNet-1K accuracy.
Ablation studies were conducted to evaluate different design choices within ViL, such as block traversal direction and classification pooling methods. The experiments revealed that bidirectional traversal of patch tokens yields better performance than unidirectional processing. The study also found ViL to be relatively robust to the choice of classification design, with different pooling methods achieving comparable results.
Implications and Future Directions
The introduction of ViL as a generic vision backbone has significant implications for computer vision research. The architecture's linear computational and memory complexity with respect to sequence length makes it particularly suitable for tasks involving high-resolution images, such as medical imaging and semantic segmentation. This advantage stems from ViL's ability to employ a chunked form of the mLSTM layer, allowing for a trade-off between parallel and recurrent computation modes.
Future research directions include exploring self-supervised learning methods to improve pre-training, optimizing hyperparameters for larger models, and investigating hierarchical architectures to further enhance ViL's capabilities. The paper also suggests that custom hardware optimizations, similar to those used in FlashAttention, could significantly improve ViL's performance.
Conclusion
ViL presents a compelling alternative to Transformers and State Space Models as a generic vision backbone. By adapting the xLSTM architecture and introducing alternating mLSTM blocks, ViL efficiently processes image data and achieves competitive performance on various computer vision tasks. The architecture's potential for handling high-resolution images and the possibility of further performance gains through optimization and architectural exploration make ViL a promising avenue for future research in the field.