Towards a Personal Health Large Language Model
Abstract: In health, most LLM research has focused on clinical tasks. However, mobile and wearable devices, which are rarely integrated into such tasks, provide rich, longitudinal data for personal health monitoring. Here we present Personal Health LLM (PH-LLM), fine-tuned from Gemini for understanding and reasoning over numerical time-series personal health data. We created and curated three datasets that test 1) production of personalized insights and recommendations from sleep patterns, physical activity, and physiological responses, 2) expert domain knowledge, and 3) prediction of self-reported sleep outcomes. For the first task we designed 857 case studies in collaboration with domain experts to assess real-world scenarios in sleep and fitness. Through comprehensive evaluation of domain-specific rubrics, we observed that Gemini Ultra 1.0 and PH-LLM are not statistically different from expert performance in fitness and, while experts remain superior for sleep, fine-tuning PH-LLM provided significant improvements in using relevant domain knowledge and personalizing information for sleep insights. We evaluated PH-LLM domain knowledge using multiple choice sleep medicine and fitness examinations. PH-LLM achieved 79% on sleep and 88% on fitness, exceeding average scores from a sample of human experts. Finally, we trained PH-LLM to predict self-reported sleep quality outcomes from textual and multimodal encoding representations of wearable data, and demonstrate that multimodal encoding is required to match performance of specialized discriminative models. Although further development and evaluation are necessary in the safety-critical personal health domain, these results demonstrate both the broad knowledge and capabilities of Gemini models and the benefit of contextualizing physiological data for personal health applications as done with PH-LLM.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a smart AI helper called the Personal Health LLM (PH-LLM). It’s a version of Google’s Gemini that was trained to understand and make sense of personal health data from devices like smartwatches. The goal is to help with everyday health topics—especially sleep and fitness—by turning streams of numbers (like heart rate, steps, and sleep stages) into clear, personalized insights and recommendations.
What questions were they trying to answer?
The researchers focused on three simple questions:
- Can an AI read wearable data and give helpful, personalized advice about sleep and fitness, like a knowledgeable coach would?
- Does the AI know enough about sleep medicine and fitness to pass expert-style tests?
- Can the AI look at recent smartwatch data and predict how someone feels about their sleep (for example, if they felt their sleep was disrupted)?
How did they study it?
To test PH-LLM fairly, the team built three kinds of challenges. Here’s how they set it up, in everyday terms:
- Building the model
- They started with a strong AI model (Gemini Ultra 1.0) and “fine-tuned” it. Fine-tuning means teaching the model new skills with specific examples—like training a good student to become a specialist.
- They trained it to read both text and numbers over time (called “time series”), such as daily sleep patterns over a month.
- Creating realistic tests
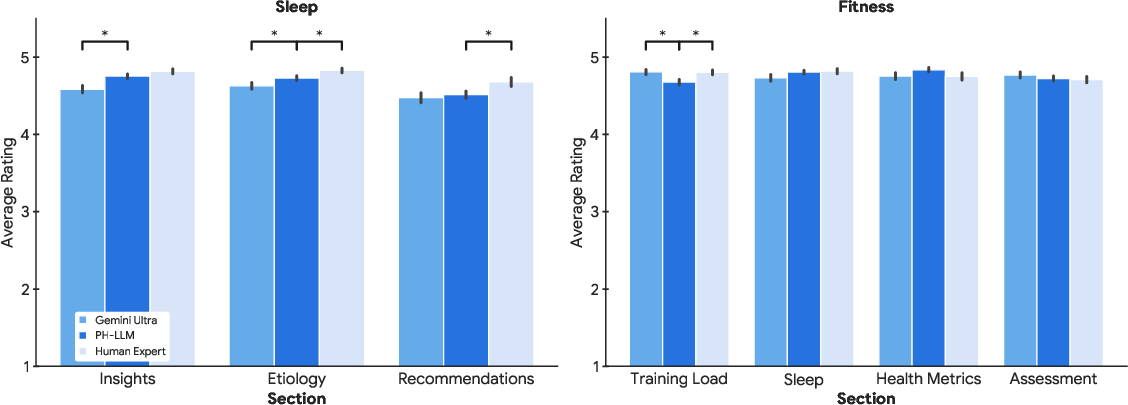
- Case studies: Experts created 857 real-world scenarios (507 for sleep and 350 for fitness) using anonymized wearable data from up to 30 days. Each case had charts/tables and expert-written insights and recommendations. The AI had to do the same task.
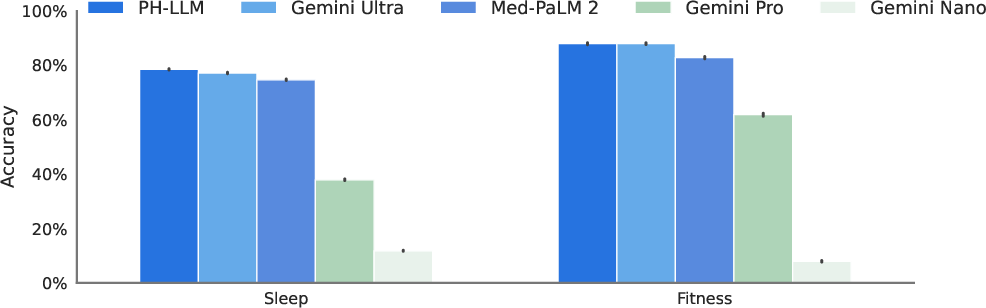
- Expert exams: They gathered 629 multiple-choice questions from sleep medicine board prep and 99 from a fitness certification prep. The AI had to answer them like a human test-taker.
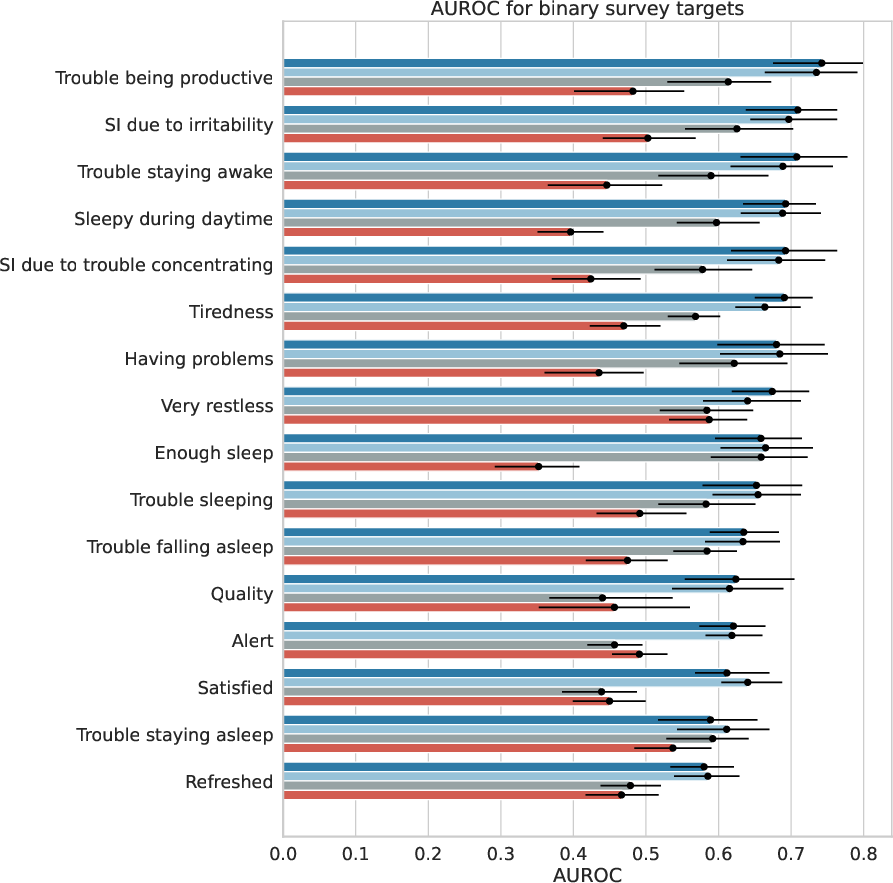
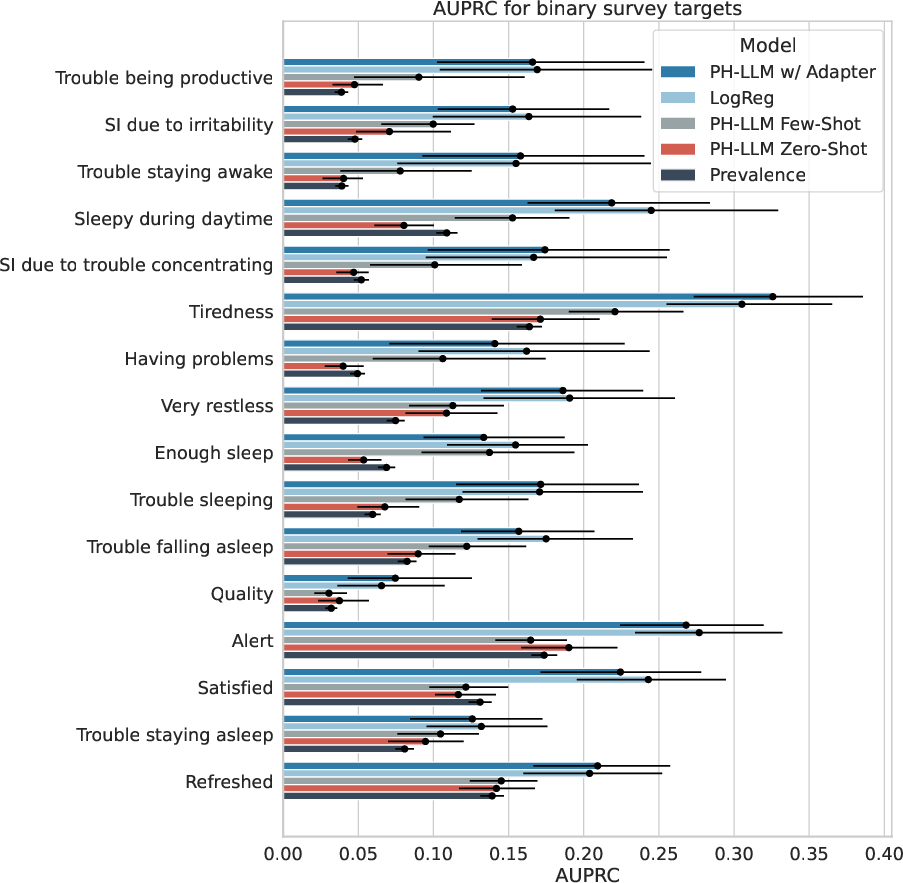
- Predicting how people felt: In a separate study with thousands of participants, people wore devices and also filled out short surveys about their sleep (for example, “Was your sleep disrupted?”). The AI learned to predict these self-reported answers from 15 days of wearable data.
- How the AI “reads” numbers
- Think of the smartwatch data like a diary of numbers (sleep times, duration, heart rate, etc.). The team used a small “adapter” to convert these numbers into a form the AI can “understand,” similar to translating a graph into words the AI can read.
- Judging the answers
- Human experts graded AI and human-written responses using clear rubrics (checklists) for quality, correctness, personalization, and safety.
- They also built an “AutoEval” system—another AI that learned to rate responses like a fast teaching assistant—so they could test more quickly during development.
What did they find?
Here are the main results and why they matter:
- On long, personalized coaching tasks:
- Fitness: PH-LLM’s advice was rated about as good as human experts. This suggests AI can already be a helpful fitness coach when it understands your recent activity, sleep, and health signals.
- Sleep: Human experts still did better overall, but fine-tuning PH-LLM clearly improved its sleep advice. The model got better at using the right data and relevant sleep knowledge to personalize insights.
- On expert-style tests:
- Sleep medicine: PH-LLM scored about 79% across 629 questions, higher than the average human experts they sampled and above the level needed for continuing education credit.
- Fitness: PH-LLM scored about 88% across 99 questions, also exceeding typical benchmarks. This shows the model knows a lot of domain facts and guidelines.
- On predicting how people felt about their sleep:
- The AI could predict survey answers (like sleep disruption or impairment) from wearable data about as well as a set of strong traditional models.
- Combining text with a smart encoding of the sensor data (the “multimodal” approach) was key. In simple terms: the model did best when it understood both the story and the numbers.
- On scaling evaluations:
- The AutoEval system (an AI rater) lined up well with human grades and made it much faster to test and improve the model.
Why does this matter?
- Personal, everyday health: Lots of health issues—like poor sleep patterns or unbalanced training—happen outside the doctor’s office. Wearables collect that story. An AI that can read those patterns and turn them into clear, safe advice could help people build better habits.
- Expert-level knowledge: Passing tough exams shows the AI isn’t just guessing; it understands core concepts in sleep medicine and fitness.
- From numbers to meaning: Wearables create tons of data. This work shows how to translate raw numbers into helpful, personalized guidance—and even predict how people feel—without requiring the user to be a data expert.
Final thoughts and impact
This research is an early step “towards” a personal health AI that can act like a thoughtful coach—especially for sleep and fitness—by understanding your wearable data and giving guidance you can use. It’s promising that PH-LLM approached expert quality in fitness advice, noticeably improved in sleep advice after fine-tuning, and outperformed typical benchmarks on expert-style exams.
That said, personal health is safety-critical. The authors note that more development, careful testing, and safeguards are needed before tools like this are used widely. If done responsibly—with strong privacy, fairness, and safety protections—PH-LLM-style systems could help people make healthier choices, catch problems earlier, and get more value from the devices they already use.
Collections
Sign up for free to add this paper to one or more collections.