- The paper systematically categorizes text summarization into four paradigms evolving from statistical methods to advanced LLMs.
- It details methodological advancements across extractive, abstractive, and hybrid approaches using metrics like ROUGE and BERTScore.
- It highlights challenges such as hallucinations and factuality, proposing multimodal and interactive summarization as future directions.
Systematic Survey of Text Summarization: From Statistical Methods to LLMs
The paper "A Systematic Survey of Text Summarization: From Statistical Methods to LLMs" provides an extensive review of the evolution in text summarization techniques. This survey charts the progression from traditional statistical methods to the current use of LLMs, divided into four key paradigms.
Major Paradigms in Summarization
The paper categorizes the evolution of text summarization into four distinct paradigms: statistical methods, deep learning-based methods, pre-trained LLM (PLM) fine-tuning, and recent advances in LLMs.

Figure 1: The Evolution of the Four Major Paradigms in Text Summarization Research.
- Statistical Methods: Initial efforts focused largely on extractive summarization using heuristic, optimization, and graph-based methods. Techniques such as TextRank and LexRank developed graph-based models to rank sentences, demonstrating the utility of graph centrality for extractive summarization.
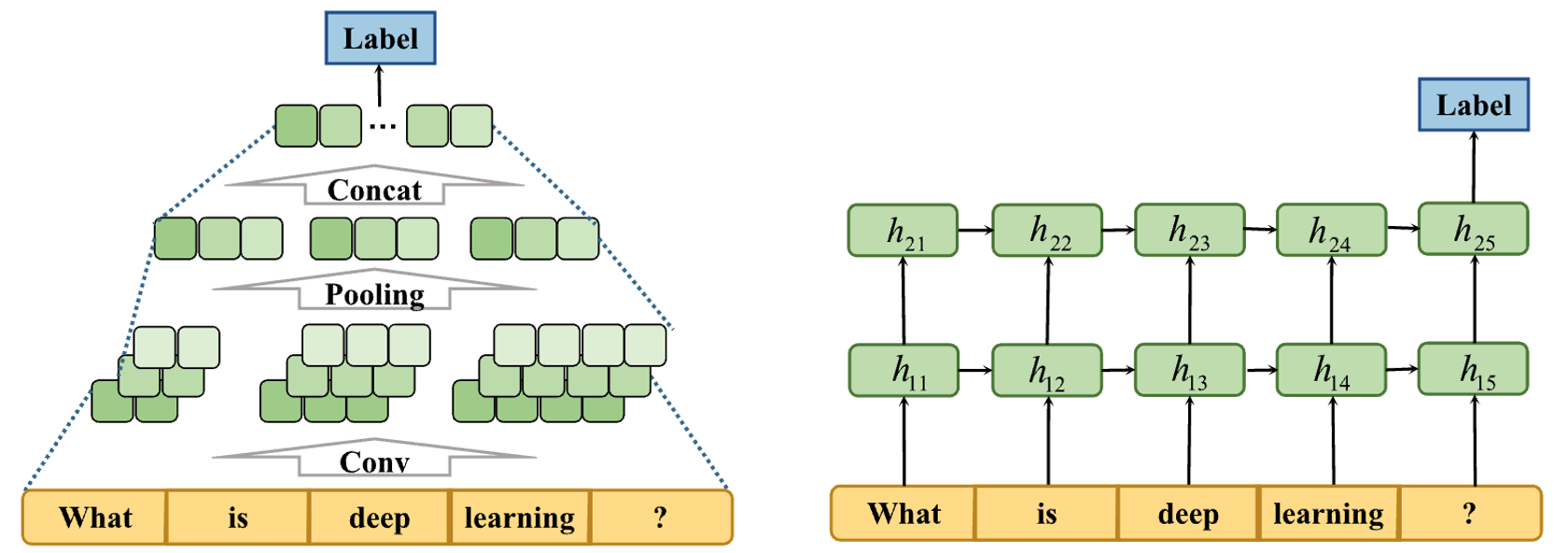
- Deep Learning Era: This era marked a shift towards utilizing neural networks, especially recurrent and convolutional neural networks, to enhance contextual understanding and sequence modeling. Reinforcement learning techniques further improved extractive and abstractive summarization by addressing exposure bias.
- PLM Fine-Tuning: Models like BERT and BART brought significant performance improvements through the "pre-train, then fine-tune" paradigm, using vast textual data for language representation.
- LLMs: The current paradigm explores the capabilities of models like GPT and their advanced generative capabilities. LLMs offer robust performance in zero-shot and few-shot scenarios, although challenges such as hallucinations persist.
Approaches and Architectures
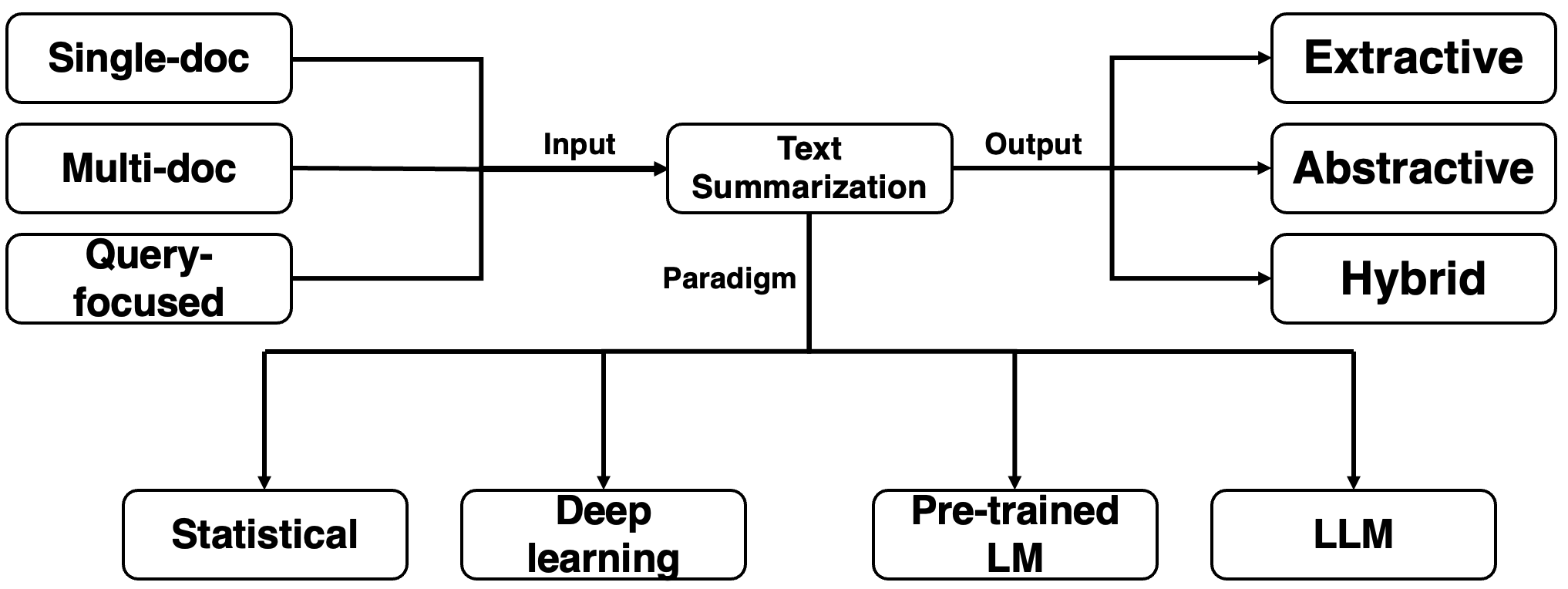
Figure 2: Categorization of Summarization Approaches based on input formats and output styles.
Text summarization methods are categorized based on input (single-document, multi-document, and query-focused) and output (extractive, abstractive, and hybrid) styles. These categories define the structure and focus of summarization tasks.
Evaluation Metrics
The paper underscores the importance of using both human and automatic evaluation metrics such as ROUGE, BERTScore, and more nuanced QA-based metrics to assess summarization quality. The limitations of ROUGE in capturing semantic similarity are addressed, leading to the exploration of model-driven evaluation methods like BartScore.
Challenges and Future Directions
Despite the progress, challenges such as ensuring the faithfulness and factuality of summaries remain. Furthermore, hallucination in LLM outputs is a significant concern. Addressing these issues involves exploring more rigorous data annotation and better training paradigms, which are critical for practical real-world applications.
The survey also speculates on the transformative potential of LLMs in automating complex summarization tasks across diverse domains. The integration of multimodal and interactive summarization systems could redefine information consumption and decision-making processes.
Conclusion
This survey comprehensively captures the trajectory of text summarization research, highlighting how methodological advances have progressively elevated system performance. It serves as a pivotal reference for ongoing and future work in leveraging cutting-edge LLMs to tackle the multifaceted challenges of summarizing vast, diverse content efficiently and accurately. The field remains vibrant, with the potential for significant breakthroughs as computational models become more sophisticated and aligned with human cognitive processes.