- The paper's main contribution is introducing WATT, which employs text prompt augmentation and weight averaging to enable full test-time adaptation of CLIP.
- It demonstrates a significant improvement, with over 14% accuracy gains on benchmarks like CIFAR-10-C, validating its robustness against domain shifts.
- The methodology leverages diverse text templates and both parallel and sequential weight averaging strategies to consolidate model updates efficiently.
Introduction
The paper "WATT: Weight Average Test-Time Adaptation of CLIP" proposes an innovative method to enhance the adaptability of Vision-LLMs (VLMs) such as CLIP in the context of domain shifts. The core contribution lies in the development of Weight Average Test-Time Adaptation (WATT), a technique designed to facilitate full test-time adaptation of CLIP. WATT employs a diverse array of text templates to enhance text prompt augmentation, utilizing predictions as pseudo-labels for model updates, followed by weight averaging to consolidate information globally. Through rigorous experimentation across a range of datasets including CIFAR-10-C and VisDA-C, the paper demonstrates the efficacy of WATT in improving performance under domain shifts without the need for additional model transformations.
Methodology
The WATT method is structured around three main components: text prompt augmentation, weight averaging, and text ensemble strategy. This involves utilizing multiple text templates to adapt the model efficiently during testing. The process leverages the complementary strengths of individual templates by averaging the adapted weights, resulting in enhanced performance across diverse domain shifts.
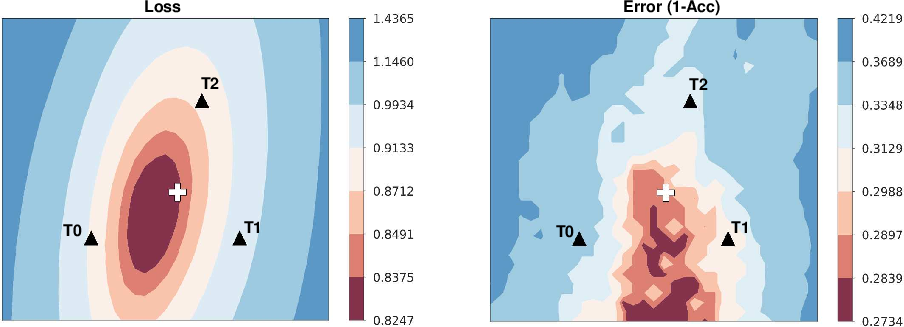
Figure 1: Loss and Error surfaces on model parameters for the Gaussian noise corruption of the CIFAR-10C dataset. Points T0, T1, and T2 represent models adapted with different text templates.
The adaptation process is further extended by employing multi-template weight averaging, which involves two approaches: Parallel and Sequential MTWA. The Parallel approach optimizes the Test-Time Adaptation (TTA) loss separately for each template, aggregating the weights thereafter. Conversely, the Sequential approach iterates through templates without resetting the model weights, allowing for cumulative adjustments.
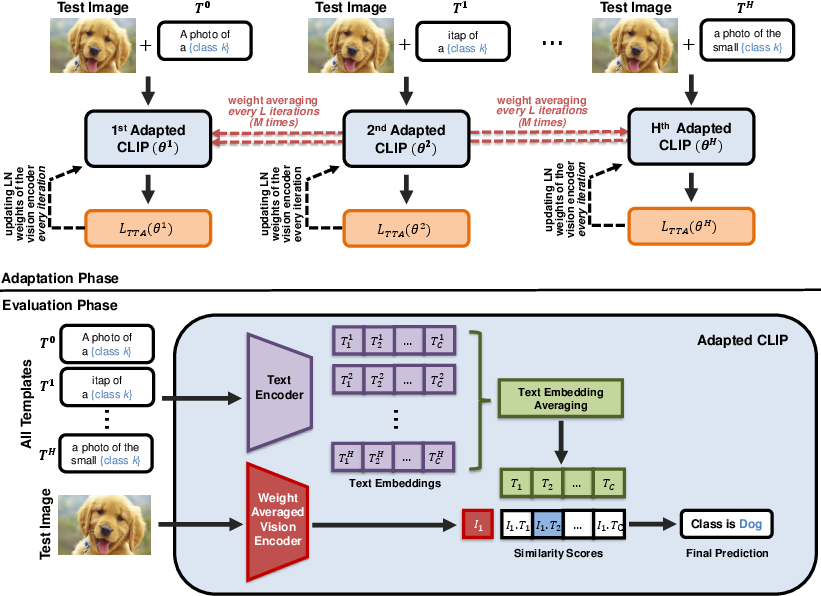
Figure 2: Overview of the proposed WATT method. In the Adaptation Phase, the model is adapted using different text templates (T0, T1, ..., TH), with weight averaging performed periodically.
Experimental Evaluation
The experimental setup comprehensively evaluates WATT's performance across various datasets experiencing different types and degrees of domain shifts. A particular focus is placed on common corruptions and distribution shifts. Comparisons are drawn against state-of-the-art methods such as TENT and CLIPArTT to substantiate WATT's superiority.
The results showcase WATT's robustness, indicating substantial improvements in classification accuracy across challenging scenarios without reliance on large batches or image augmentations. For instance, on CIFAR-10-C, WATT demonstrates an enhancement of over 14% accuracy compared to the baseline, emphasizing the effectiveness of template-based adaptation and weight averaging.
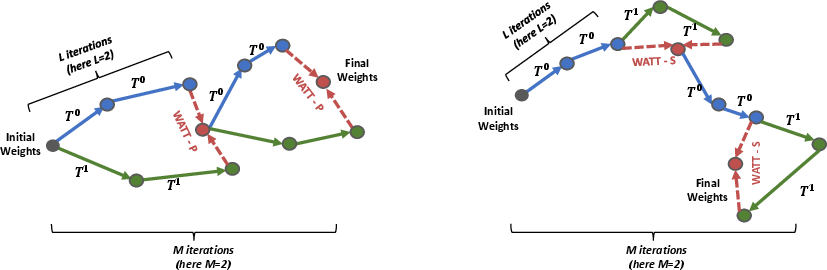
Figure 3: Visual comparison of the Parallel (left) and Sequential (right) approaches for multi-template weight averaging during adaptation.
Implications and Future Directions
The proposed WATT method signifies a substantial step forward in the real-time adaptability of VLMs to unforeseen domain shifts. It opens potential avenues for further research, particularly in exploring the applicability of multi-template approaches beyond classification tasks, such as in segmentation or object detection. Additionally, incorporating alternative class descriptors through template manipulation offers a pathway for deeper insights into model adaptability.
Conclusion
The paper proposes a novel Test-Time Adaptation method, WATT, that effectively extends the zero-shot capabilities of CLIP through innovative use of text prompt augmentation and weight averaging. Through exhaustive evaluations, WATT's potential to significantly enhance VLM performance under domain shifts without additional trainable modules or computational overhead is clearly established. The findings underscore the potential for WATT to contribute to the broader field of adaptive machine learning models, paving the way for future exploration of template and weight averaging strategies.