- The paper demonstrates that exemplar selection significantly outperforms instruction optimization across a range of tasks.
- The paper reveals that combining IO and ES yields multiplicative performance gains even under strict computational budgets.
- The paper shows that optimized exemplars generalize better than instructions, urging a reevaluation of current prompt engineering strategies.
Teach Better or Show Smarter? On Instructions and Exemplars in Automatic Prompt Optimization
This paper explores the critical aspects of Automatic Prompt Optimization (APO) as applied to LLMs, focusing on instruction optimization (IO) and exemplar selection (ES). In particular, it offers a comprehensive evaluation and comparison of these two strategies, either in isolation or combined, across a range of challenging tasks.
Introduction to Automatic Prompt Optimization
Automatic Prompt Optimization (APO) is essential to harness the full potential of LLMs, which heavily rely on well-crafted prompts to deliver optimal performance. APO encompasses two main approaches: Instruction Optimization (IO), which refines task-specific textual instructions, and Exemplar Selection (ES), targeting the selection of relevant examples to improve model responses. Despite their shared objective, the research communities have traditionally tackled IO and ES separately, with a recent shift favoring IO due to the improved instruction-following abilities of modern LLMs.
Key Findings and Results
Exemplar Selection Outweighs Instruction Optimization
The study’s experimental results demonstrate that ES often has a more pronounced effect on performance improvement than IO. The researchers illustrate that simple random searches in ES, which involve the model-generated input-output pairs, can exceed the performance gains realized by complex IO methods. This observation is consistently reflected across multiple tasks and models.
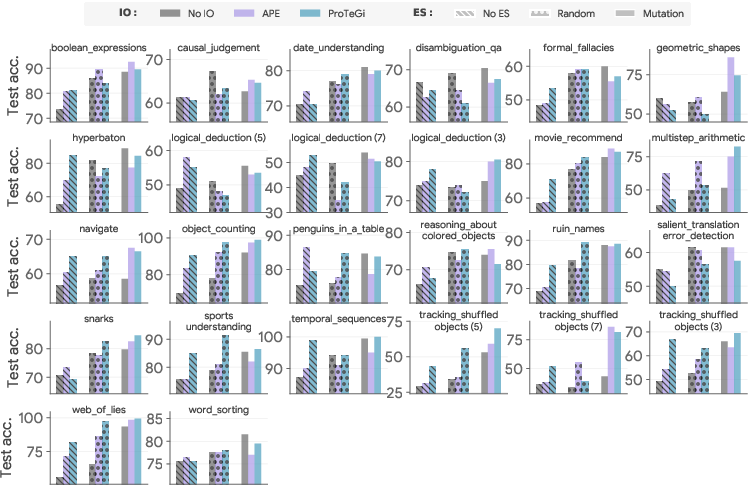
Figure 1: Task-specific BBH performance of representative IO-ES combinations with PaLM 2. Note the almost uniform improvement with proper ES.
Synergy Between IO and ES
The paper further investigates the interplay between IO and ES, revealing that their combination results in higher performance than using each strategy in isolation. This synergy suggests that optimizing both instructions and exemplars together is not merely the sum of their individual effects but a multiplication that leads to significantly enhanced outcomes even under computational budget constraints.
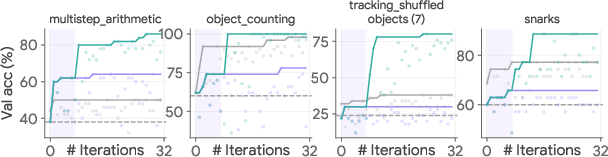
Figure 2: Mixing-and-matching ES and IO outperform either alone under a similar budget.
Generalization and Model Behavior
A crucial insight derived from the study is that optimized exemplars tend to generalize better than optimized instructions. This was evidenced by smaller generalization gaps observed when using optimized examples, suggesting that ES might address broader task scenarios more effectively than IO. Moreover, the study discovered that highly effective prompts often contain "quasi-exemplars," which are instructional in nature but embedded with examples that subtly drive performance improvements.
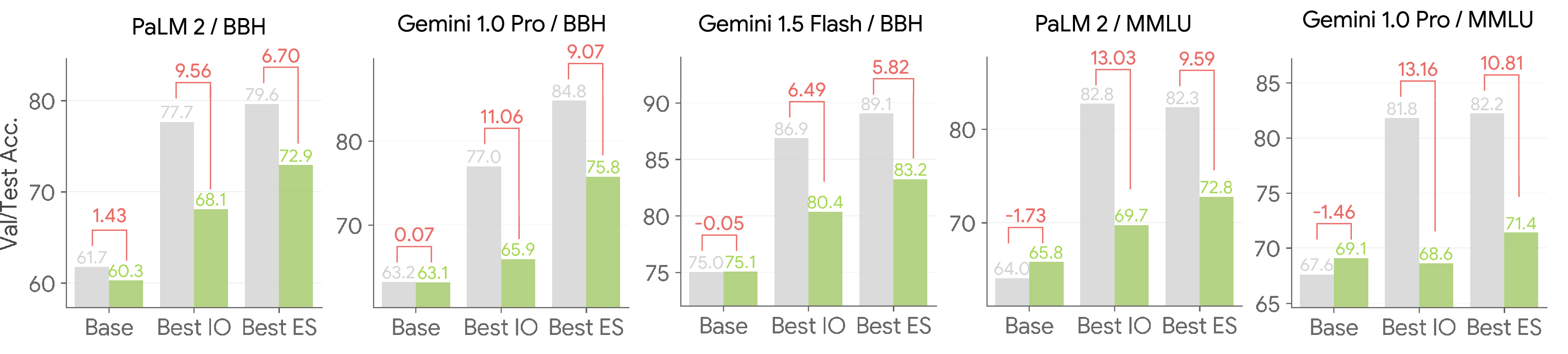
Figure 3: Optimized exemplars generalize better than optimized instructions.
Implications for Future Research
The study's findings call for a reevaluation of current research trends emphasizing IO at the expense of ES. While the generation of refined instructions remains important, ES's role may be undervalued or underutilized, representing a substantial opportunity for future work in effective prompt engineering. Advanced methods for exemplar optimization, as well as the integration of new search strategies, are anticipated to yield even higher gains by capitalizing on LLMs' ability to learn from contextual examples effectively.
Conclusion
In conclusion, this paper sheds light on the underappreciated importance of exemplar selection in APO for LLMs. While instruction optimization remains valuable, ES offers a striking potential for performance enhancements that warrant more attention in future studies. The complementarities between IO and ES indicate a rich area for exploration, where collaborative optimization could redefine what is possible with APO under constrained budgets. The insights from this research challenge the status quo and posit exemplar optimization as a pivotal tool alongside instruction refinement in the next chapter of LLM optimization strategies.