- The paper demonstrates that incorporating Mixture of Experts in deep reinforcement learning, particularly in continual settings, enhances performance by preserving network plasticity.
- The study shows that architecture design and routing strategies, especially using the Big module with hardcoded routing, critically influence learning dynamics in non-stationary environments.
- The research outlines practical benefits of expert specialization and suggests future exploration of curriculum strategies and multi-agent setups to further optimize DRL.
Mixture of Experts in a Mixture of RL Settings
Introduction
The paper investigates the integration of Mixture of Experts (MoEs) within Deep Reinforcement Learning (DRL) frameworks, particularly in multi-task scenarios. The research extends previous findings that MoEs enhance DRL performance by mitigating plasticity loss and reducing dormant neurons while exploring these benefits under amplified non-stationary conditions. The paper focuses on two primary settings: Multi-Task Reinforcement Learning (MTRL) and Continual Reinforcement Learning (CRL).
Experimental Setup and Methodology
The methodology employs various MoE architectures embedded within MTRL and CRL environments to assess the impact on learning dynamics. The architectures examined are termed Baseline, Middle, Final, All, and Big, with the Big architecture featuring a singular MoE module encompassing an entire network. Experiments were conducted using the PureJaxRL codebase, high-performance and parallelizable, implementing Proximal Policy Optimization (PPO) as the agent's learning strategy. The environments selected include SpaceInvaders, Breakout, and Asterix, chosen for their varying input and action spaces to analyze MoE's ability to share representations across similar and distinct tasks.
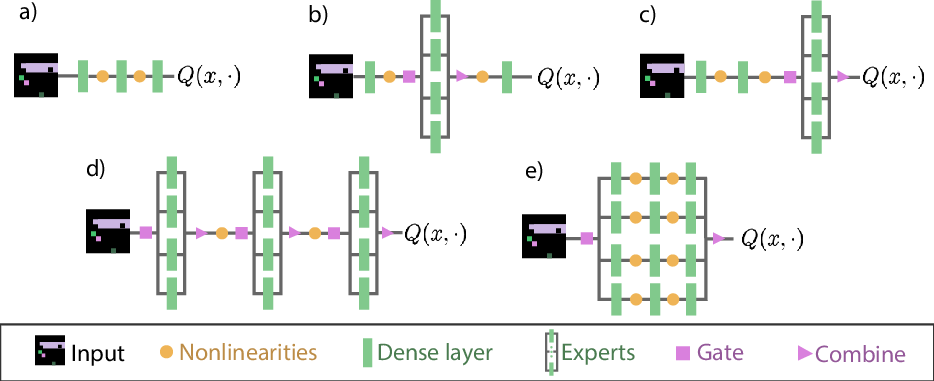
Figure 1: Architectures considered: (a) Baseline architecture; (b) Middle, used by preceding researchers; (c) Final, where an MoE module replaces the final layer; (d) All, where all layers are replaced with an MoE module; (e) Big, with a single MoE module where an expert comprises the full original network.
Results and Analysis
Impact of MoE Architectures:
The performance of different architectures was most notable in the CRL setting, where architectures generally outperformed the baseline except in the MTRL scenario, where only Big surpassed baseline results. This indicates that network architecture plays a critical role in the efficacy of MoEs under varied training conditions.
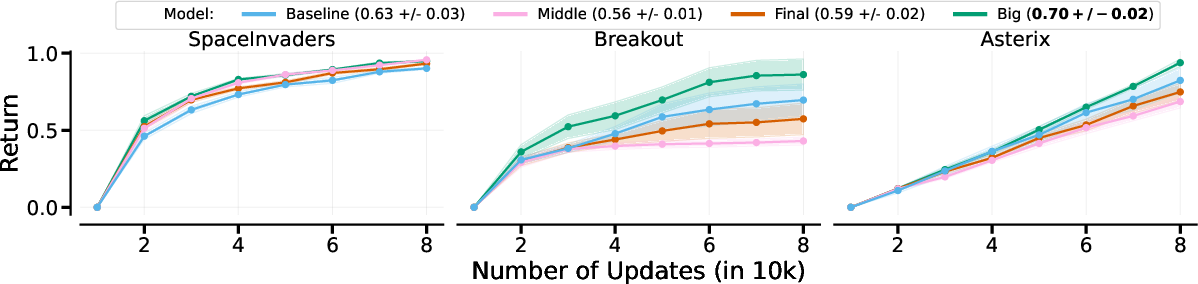
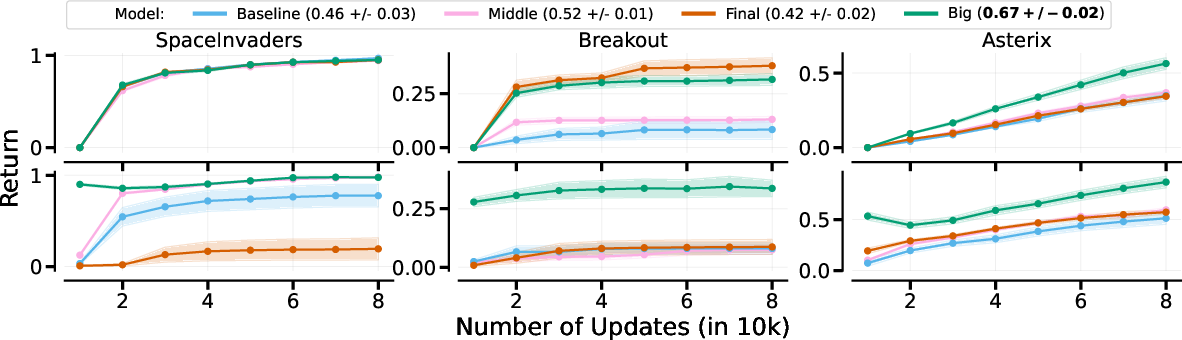
Figure 2: Measuring the impact of MoE architectures with hardcoded routing in MTRL (top) and CRL (bottom). Big outperforms all other methods.
Impact of Learned Routers:
The examination of routing strategies within the Big architecture revealed that SoftMoE performs comparably to hardcoded routers in MTRL due to effective gating mechanisms. However, in CRL settings, the hardcoded router provided the best results, given its ability to retain prior learned policies through task switching.
Network Plasticity and Expert Specialization:
By quantifying dormant neurons, the study demonstrated that MoEs effectively preserve network plasticity. Expert specialization is evident within the architectures, suggesting routes to enhanced learning outcomes, particularly when MoEs are coupled with load-balancing and entropy regularization.
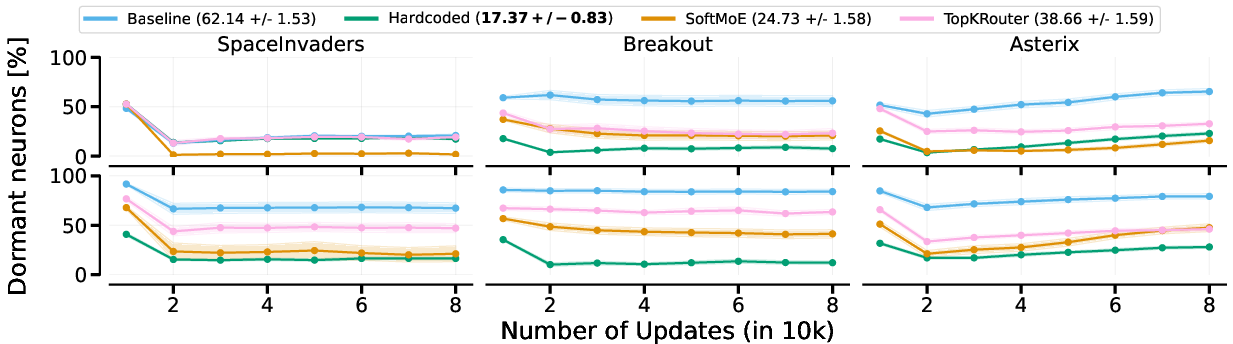
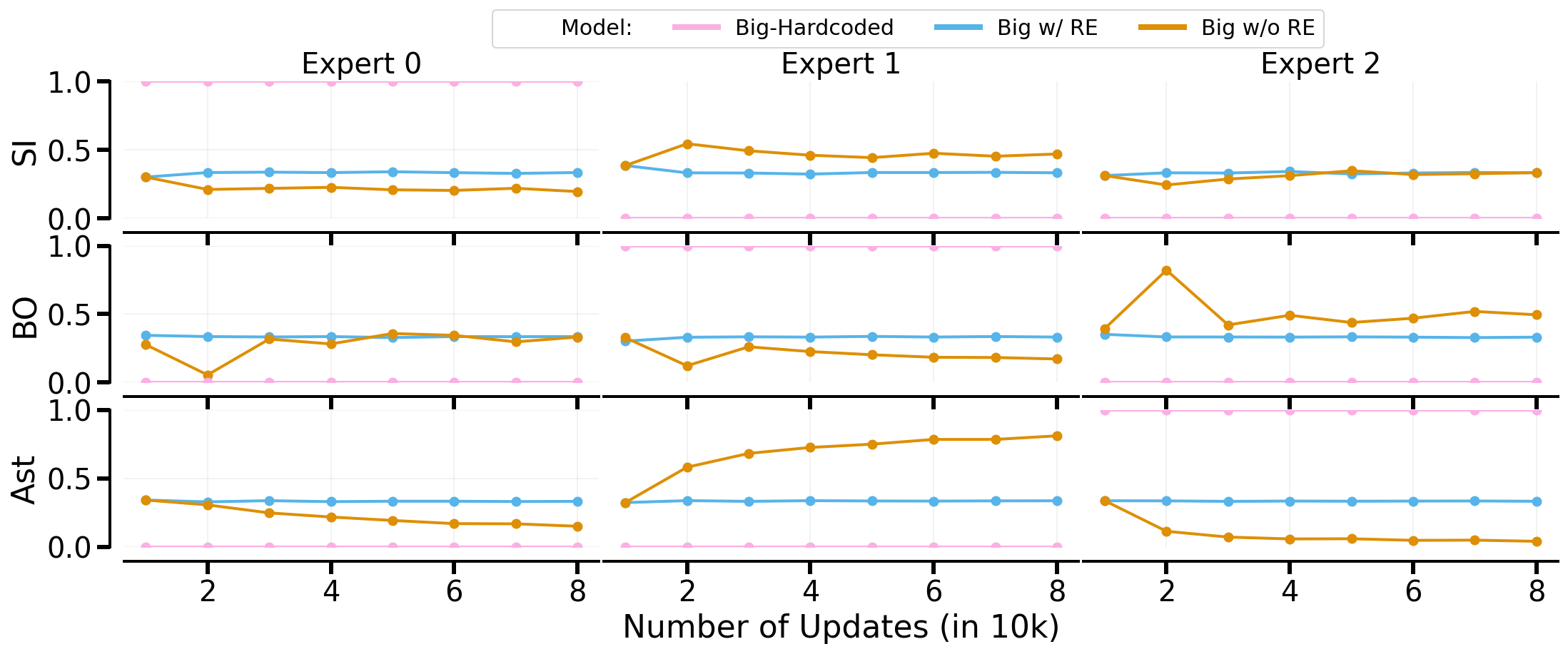
Figure 3: presents the ratio of dormant neurons for CRL under different routing approaches using Big. MoE variants have lower dormant neurons than the baseline.
Implications and Future Directions
The findings underscore the potential of MoEs in facilitating improved learning within DRL, particularly when facing extreme non-stationarity as found in MTRL and CRL settings. Future work might involve exploring curriculum strategies for task ordering to maximize policy retention and generalization. There is also potential for investigating MoEs in multi-agent environments, wherein experts might serve as distinct cooperative or competitive agents.
Conclusion
The research articulates the pragmatic advantages of deploying MoEs within DRL setups, revealing their capacity to handle non-stationary challenges effectively. The singular contributions of routing strategies and task order highlight avenues for enhancing DRL methodologies further. Despite varying results with MoE configurations, the paper suggests broad applicability across diverse learning environments, with implications for both theoretical advances and applied reinforcement learning solutions.