- The paper demonstrates that integrating graph-based knowledge via adapters significantly enhances multilingual LLM performance for low-resource languages.
- The approach employs language-specific adapters fine-tuned on ConceptNet and Wikipedia data to inject linguistic relationships efficiently.
- Experimental results reveal notable gains in sentiment analysis, while improvements in NER vary, highlighting the need for task-specific tuning.
Adapting Multilingual LLMs to Low-Resource Languages with Knowledge Graphs via Adapters
Introduction
The paper explores a sophisticated method to enhance multilingual LLMs by integrating linguistic knowledge graphs using adapters. This approach particularly targets low-resource languages (LRLs), which traditionally suffer from limited data availability. By leveraging knowledge from ConceptNet, the research aims to improve performance in sentiment analysis (SA) and named entity recognition (NER) for languages like Maltese, Bulgarian, Indonesian, and others.
The integration involves training language-specific adapters on multilingual graph data with various fine-tuning objectives, including standard Masked Language Modeling (MLM) and other novel approaches. The key innovation lies in the use of adapters, which are lightweight modules added to LLMs for knowledge injection without a full model retraining.
Methodology
The research builds upon existing parameter-efficient techniques like K-ADAPTER and MAD-X, detailing an architecture where adapters incorporate external graph knowledge into multilingual LLMs.
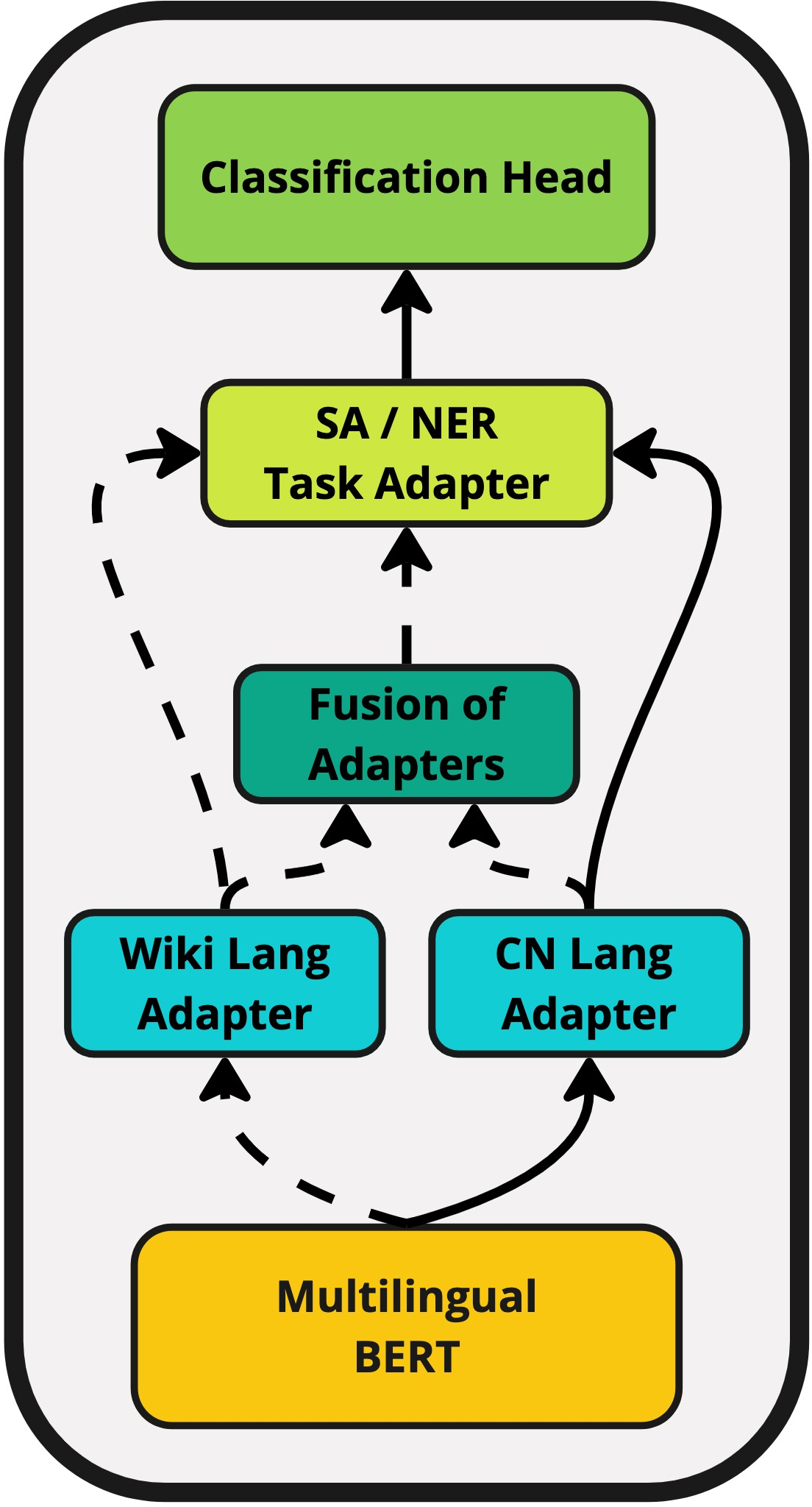
Figure 1: Proposed method. One of the Wiki or ConceptNet language adapters is used during inference. The outputs then go to a task adapter, which is followed by a classification head. If fusion is specified, the fusion mechanism is activated.
Adapters are trained on ConceptNet data transformed into natural language sentences, which connect semantic relationships effectively. For instance, the triple (kiel, RelatedTo, eat) is converted into "kiel is related to eat," where "kiel" is the Maltese word for "eat."
Two types of adapters are utilized:
- ConceptNet-based Language Adapters: Trained on graph data to capture linguistic relationships.
- Wikipedia-based Language Adapters: Trained on textual data from language-specific sections of Wikipedia.
The architecture allows for dynamic combination of knowledge via Adapter Fusion, which integrates information from different sources through contextual activation.
Experimental Results
Experiments demonstrate that using adapters generally enhances performance on LRLs in both SA and NER tasks:
- Sentiment Analysis (SA): Adapters trained on ConceptNet and Wikipedia provide significant gains, particularly for languages with minimal coverage in mBERT's pre-training data.
- Named Entity Recognition (NER): Results are more varied, with some languages showing limited improvements. This discrepancy underscores the tasks' inherent differences in leveraging graph-based knowledge.
The results emphasize the potential of adapters in effectively translating external knowledge into meaningful LLM enhancements, although the specific impact varies across languages and tasks.
Implications and Future Work
The paper highlights the adaptability of multilingual LLMs to diverse linguistic contexts through efficient knowledge integration, particularly for LRLs. It opens avenues for further exploration into optimizing objective functions for training language adapters and expanding to additional languages and tasks that better exploit graph-based knowledge.
Future research could focus on refining Adapter Fusion techniques and exploring cross-task impacts, potentially enhancing LLMs' robustness and versatility in processing multilingual datasets.