- The paper introduces novel methods like CKA to evaluate embedding similarity beyond traditional benchmarks.
- It employs both representational and retrieval-based measures, including Jaccard and rank similarity, to assess model performance.
- The study reveals intra- and inter-family clusters, offering actionable insights for selecting cost-effective, high-performing models.
Beyond Benchmarks: Evaluating Embedding Model Similarity for Retrieval Augmented Generation Systems
Introduction
The paper entitled "Beyond Benchmarks: Evaluating Embedding Model Similarity for Retrieval Augmented Generation Systems" (2407.08275) aims to enhance the model selection process for Retrieval Augmented Generation (RAG) systems by identifying similarities among embedding models beyond traditional benchmark performance scores. RAG systems, which utilize external knowledge bases to improve the factual accuracy and currency of LLMs, rely heavily on the retrieval of relevant text documents. This requires effective embeddings which are produced by various LLMs, many of which display similar benchmark performance but may differ in actual retrieval outputs.
Methodologies
Pair-wise Embedding Similarity
To assess model similarity beyond benchmark scores, the authors employ Centered Kernel Alignment (CKA), a representational similarity measure, which allows for direct comparison between different embedding models without requiring identical representation spaces.
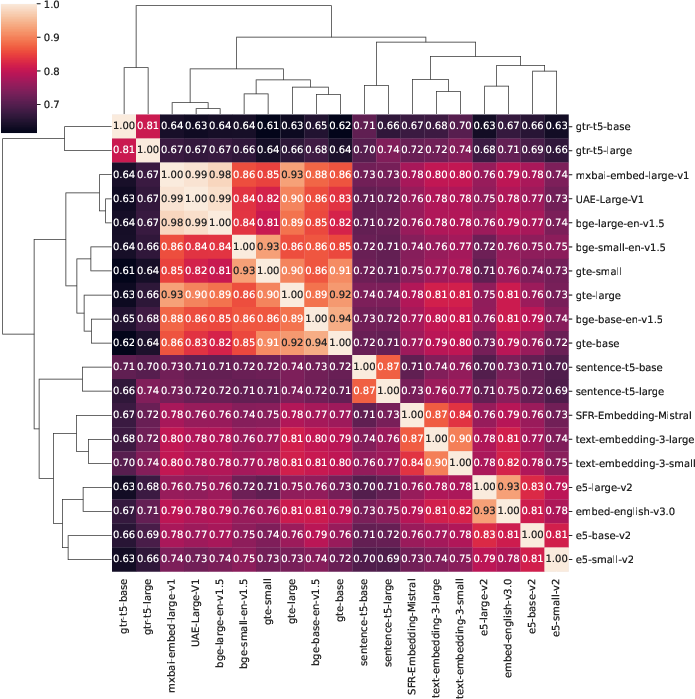
Figure 1: Mean CKA similarity across all five datasets. Models tend to be most similar to models belonging to their own family, though some interesting inter-family patterns are visible as well.
CKA calculates similarity based on embedding pair-wise comparability, offering a normalized score from zero (no similarity) to one (complete similarity).
Retrieval Similarity
Besides representational similarity, the paper assesses the functional similarity relevant to RAG applications by evaluating the overlap in retrieved text chunks. Two measures are utilized:
- Jaccard Similarity: This indicates the percentage overlap between retrieved text chunks, providing insight into the practical extent of similarity between models.
- Rank Similarity: Evaluates the rank order of overlapping retrievals, offering a deeper understanding of retrieval alignment beyond mere overlap.
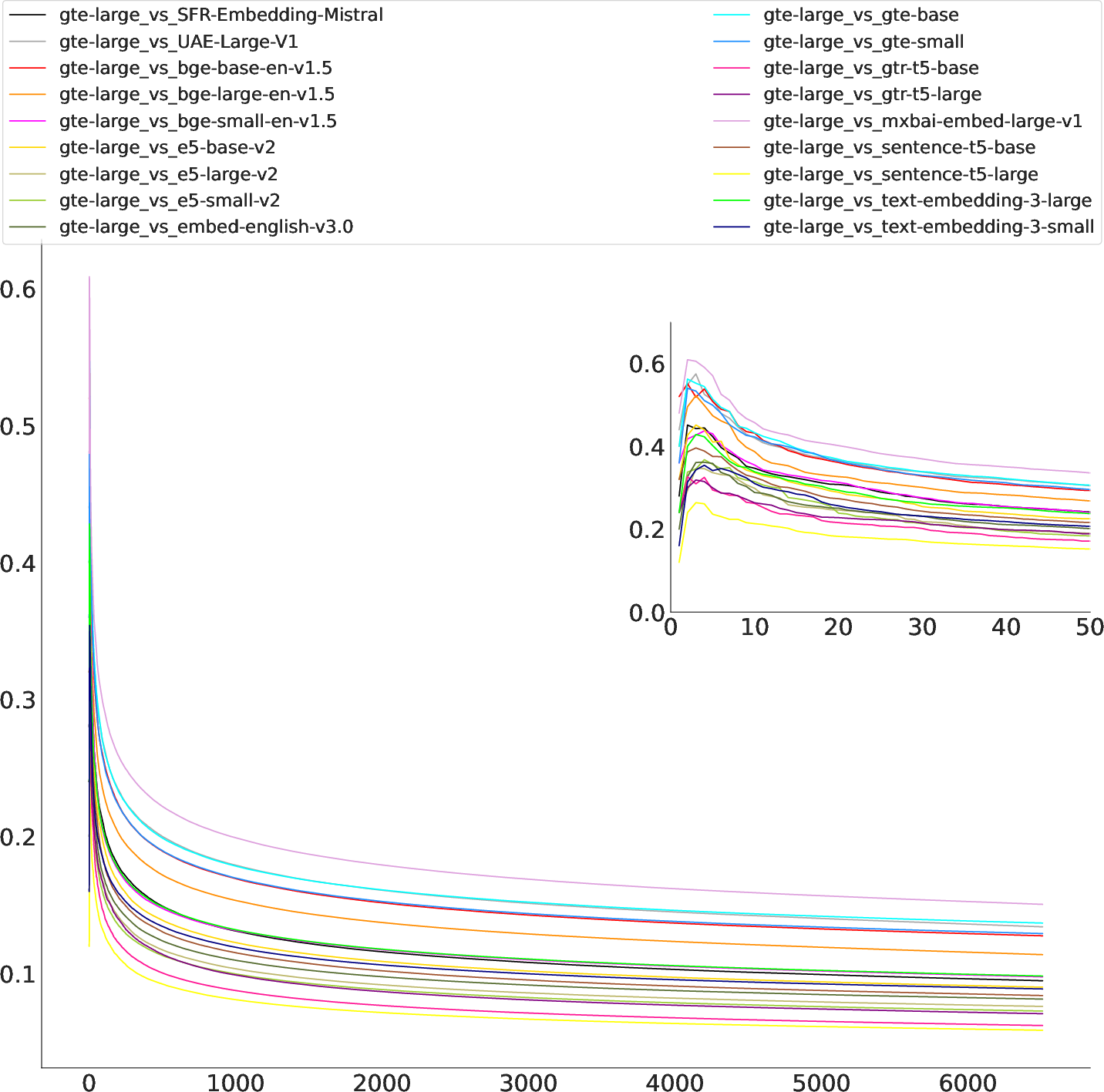
Figure 2: Rank similarity over all k on NFCorpus, comparing gte-large to all other models. Scores are highest and vary most for small k, but then drop quickly before stabilizing for larger k.
Experimental Setup
The authors examine embeddings across five datasets, chosen based on size and representational properties, to ensure broad applicability of findings. Models evaluated include both open-source and proprietary options, covering diverse families like e5, t5, bge, gte, OpenAI, and Cohere.
Results
Intra- and Inter-Family Clusters
The analysis reveals that models within the same family show high intra-family similarity, particularly evident in CKA scores. Models from the bge and gte families display noteworthy inter-family similarity, suggesting functional likeness in practical applications. Specific clusters exhibit almost perfect similarity, which could streamline the model selection process.
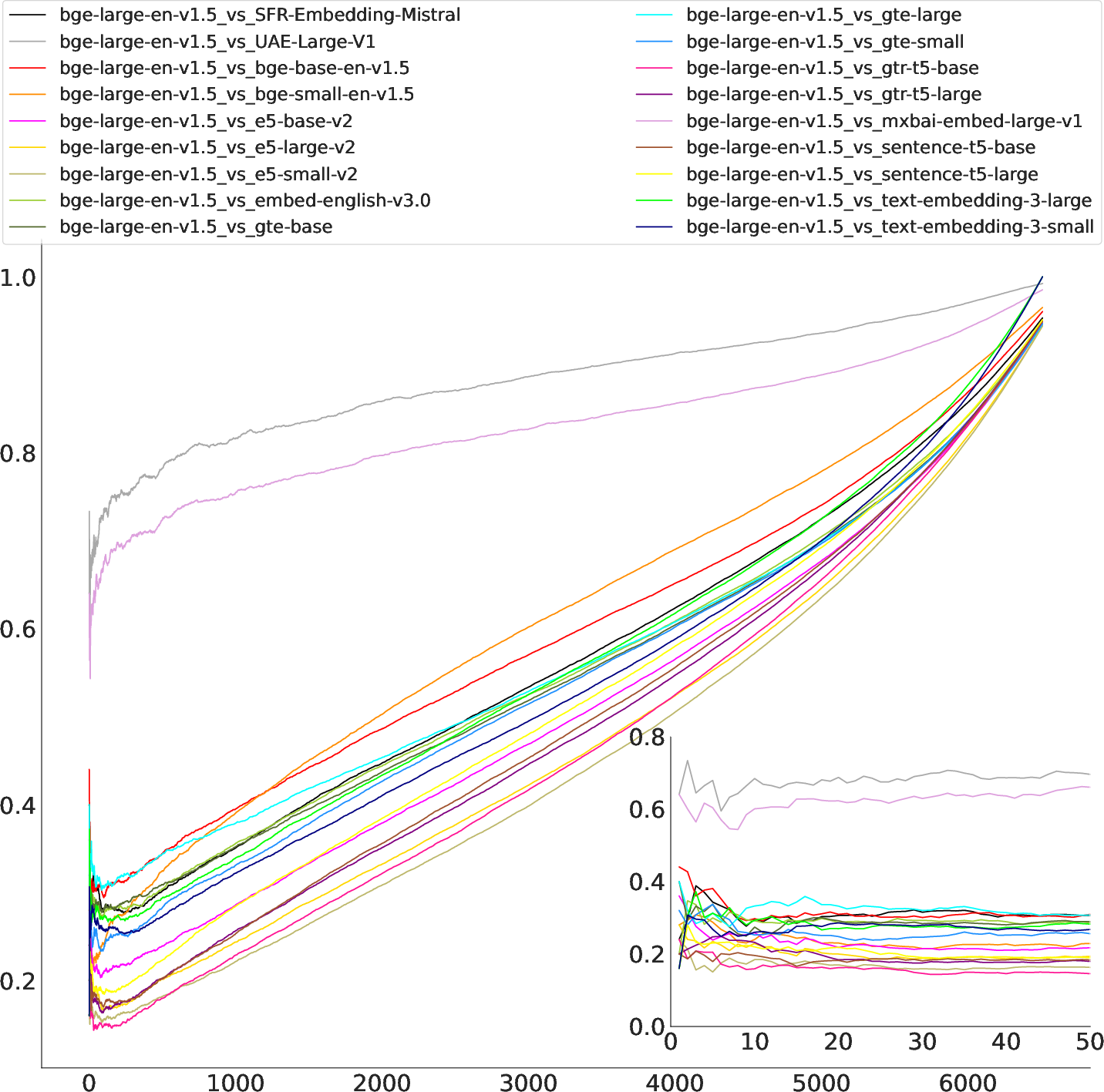
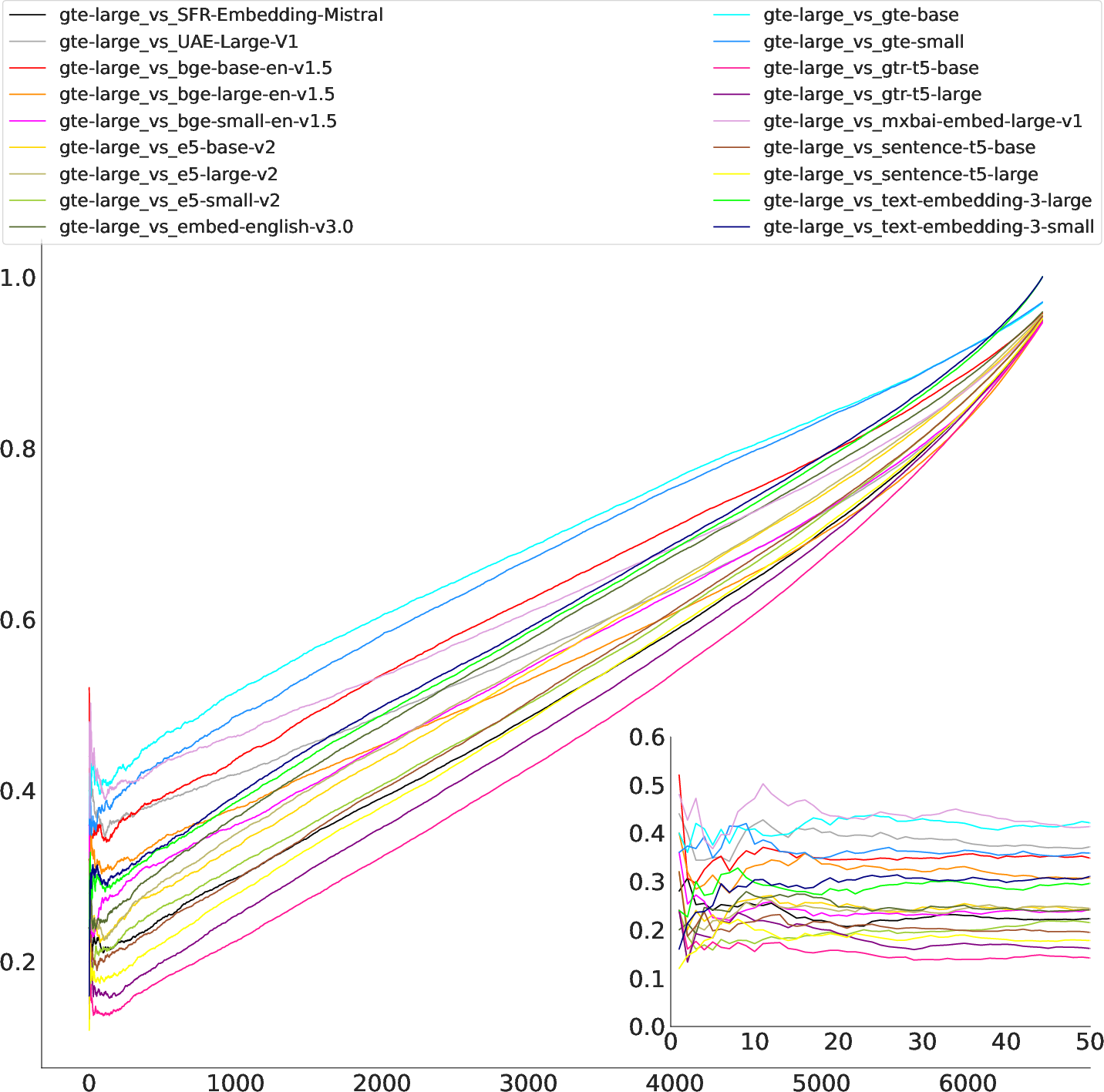
Figure 3: Jaccard similarity over all k on NFCorpus, comparing bge-large (a) and gte-large (b) to all other models. While bge-large shows high similarity to UAE-Large-v1 and mxbai-embed-large-v1, scores for gte-large are clustered much closer. Jaccard similarity seems to be most unstable for small k, which would commonly be chosen for retrieval tasks.
Discussion
The findings suggest significant practical implications for selecting embedding models in RAG systems. While pair-wise similarity offers insights into model representations, retrieval-based evaluation provides critical understanding relevant to real-world applications, particularly for small k values. The paper highlights the strategic importance of considering both representational and retrieval similarity when choosing models, as this could greatly influence retrieval quality and system performance.
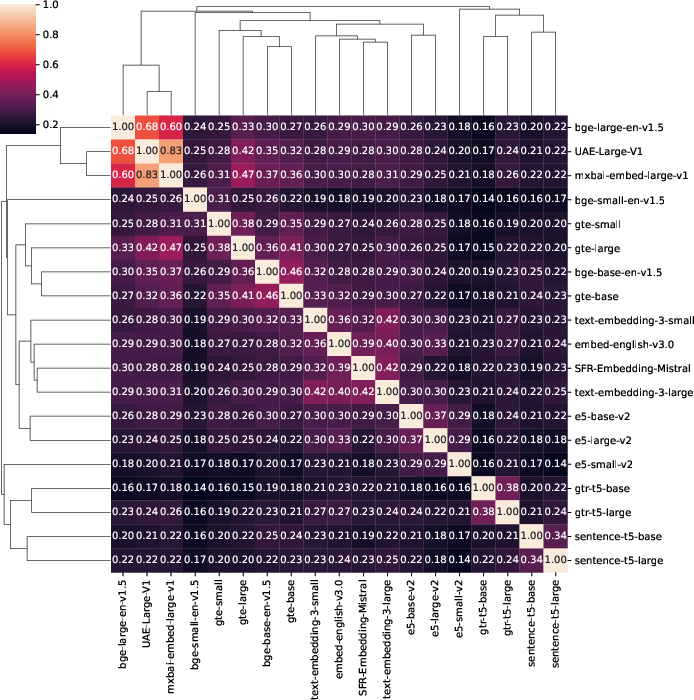
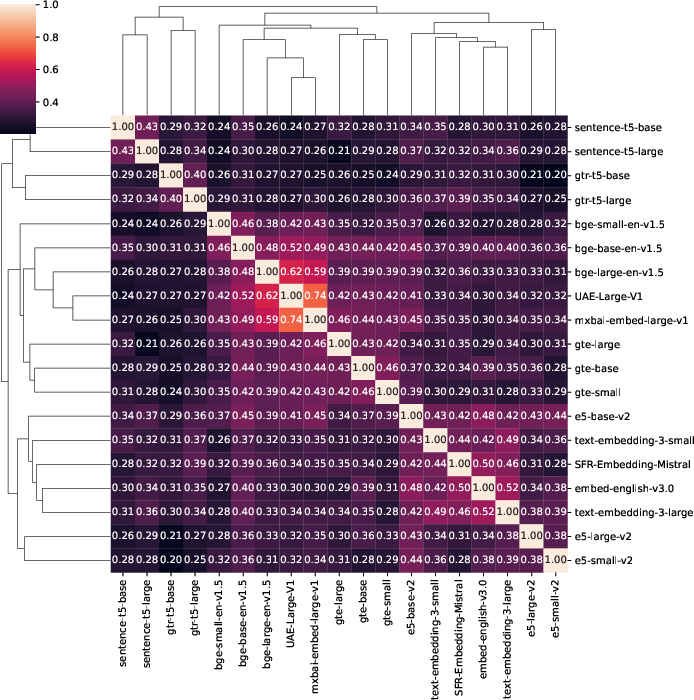
Figure 4: Jaccard (a) and rank similarity (b) for the top-10 retrieved text chunks averaged over 25 queries on NFCorpus. The clusters vary slightly depending on the measure, as do the scores. Models tend to be most similar to models from their own family. However, some inter-family clusters are visible as well.
Another crucial aspect of the study is identifying open-source alternatives to proprietary models, which could provide cost-effective solutions with similar functionality. It was observed that Mistral exhibits high similarity to OpenAI embedding models, suggesting its potential as a substitute.
Conclusion
By examining model similarity through both representational and retrieval-based perspectives, the paper sheds light on critical aspects of embedding model selection for RAG systems. The implications of this research extend to enhancing the efficiency and cost-effectiveness of RAG deployments. Furthermore, the findings advocate for a nuanced approach to model selection that transcends performance benchmarks and considers practical retrieval outcomes.
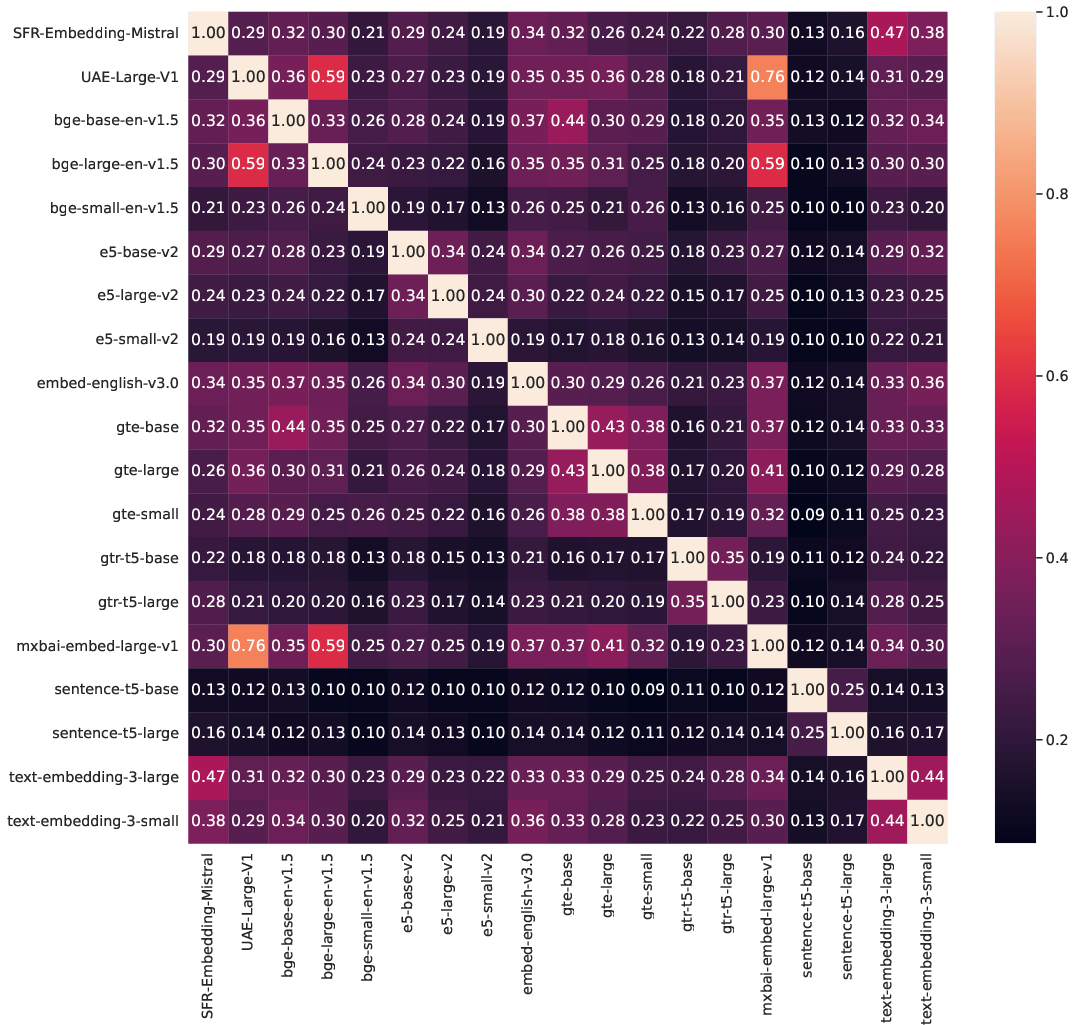
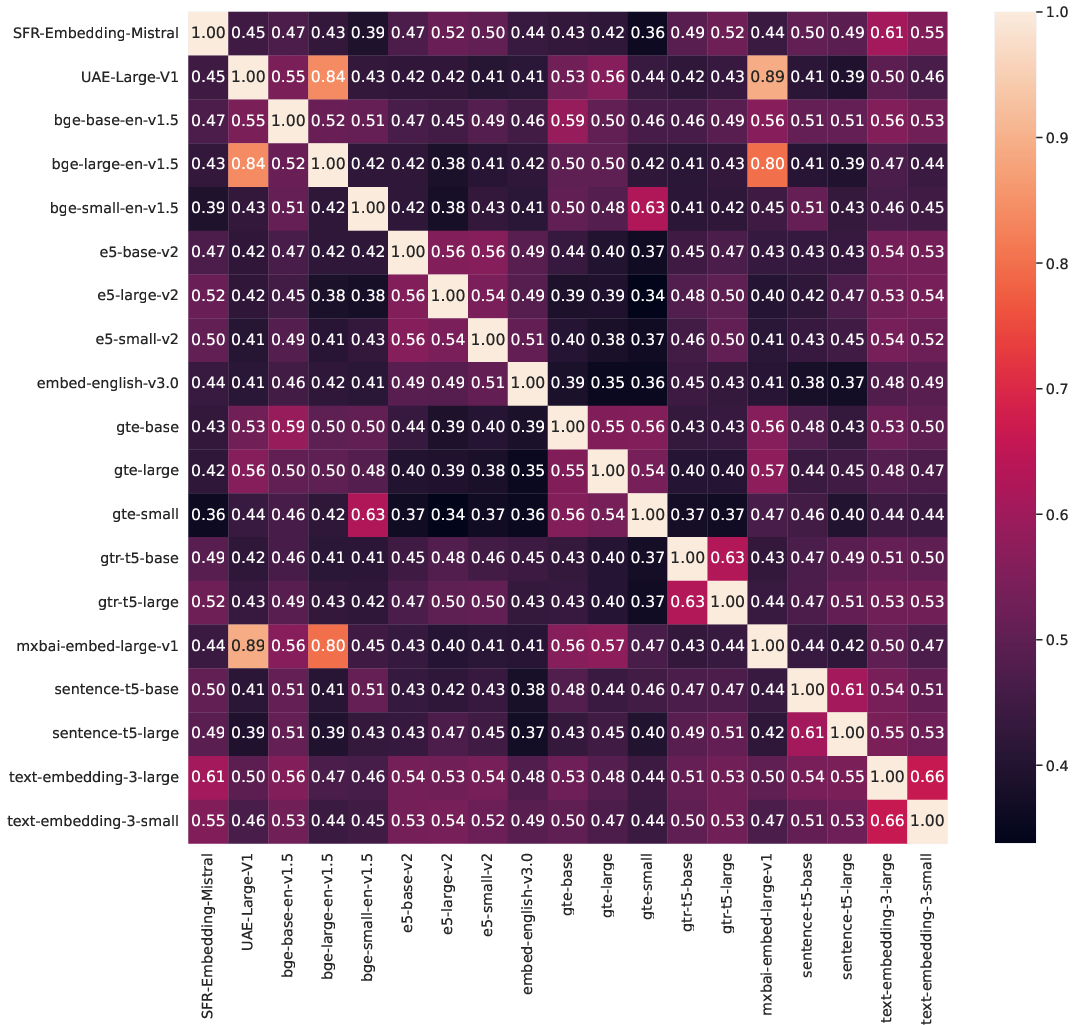
Figure 5: Jaccard similarity for the top-10 retrieved text chunks averaged over 25 queries on SciFact (a) and ArguAna (b). The UAE and mxbai models show high levels of similarity along with bge-large. The remaining models tend to show the highest similarity within their own family with the exception of the bge/gte inter-family cluster.