- The paper demonstrates a universal truthfulness hyperplane that distinguishes factually correct outputs from hallucinations in LLMs.
- It employs logistic regression and mass mean probes on over 40 diverse tasks to extract linear representations of truthfulness.
- Experimental results show approximately 70% cross-task accuracy, highlighting the hyperplane's potential to enhance LLM reliability.
Universal Truthfulness Hyperplane Inside LLMs
The paper "On the Universal Truthfulness Hyperplane Inside LLMs" explores the potential existence of a universal hyperplane within LLMs that can distinguish between factually correct and incorrect outputs. This study is motivated by the persistent hallucination challenges within LLMs and aims to identify patterns within their hidden states that may correlate with truthfulness across diverse datasets.
Introduction and Motivation
LLMs have achieved remarkable success across numerous applications but are plagued by hallucinations, impacting reliability and user trust. A critical question is whether these models internally encode a universal representation that can differentiate factual responses from hallucinations. Prior research often indicates that probing specific datasets can overfit models to spurious patterns, questioning the general applicability of the identified features. This study aims to determine if a universal truthfulness hyperplane exists, capable of generalizing beyond specific datasets.
Methodology
The investigation involves constructing a diverse collection of datasets encompassing over 40 distinct tasks (Figure 1). The methodology focuses on probing the inner representations of LLMs using logistic regression (LR) and mass mean (MM) probes to identify such a hyperplane within model hidden states. The experimental design involves measuring generalization performance across cross-task, cross-domain, and in-domain settings.
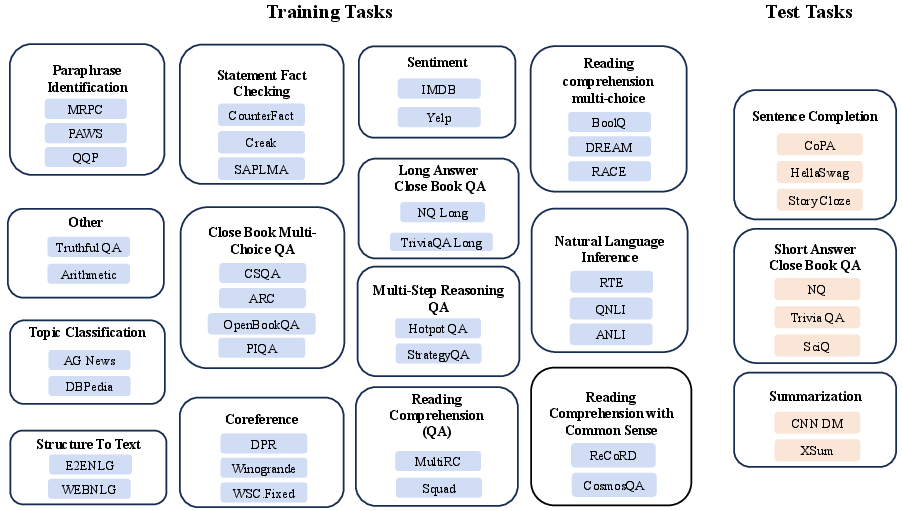
Figure 1: Our curated datasets and tasks. Left (Blue) part represents the training tasks, while the right (Orange) represents the test tasks.
Probing Strategy
Probing leverages the last token's representations in a sequence for each dataset. The logistic regression and mass mean techniques extract features to evaluate truthfulness, hypothesizing that truthfulness-related information is encoded linearly within the neural network's hidden states. The data curation strategy is designed to challenge the models with both correct and incorrect samples from wide-ranging knowledge domains.
Experimental Findings
Experiments reveal that probes trained on diverse datasets outperform those trained on single datasets when generalizing to out-of-distribution (OOD) data. Probes achieve approximately 70% accuracy in cross-task validation, emphasizing a significant improvement over baseline methods like self-evaluation and probability-based assessments. These results suggest that such a truthfulness hyperplane is not merely dataset-specific but potentially universal across model architectures.
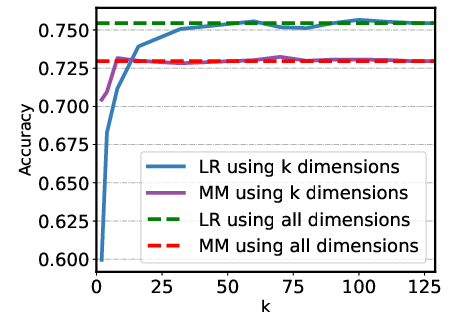
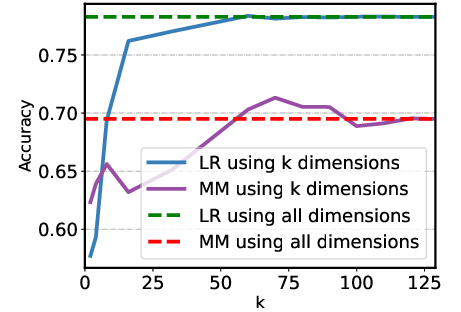
Figure 2: Examples of sparsity test on different datasets using the logistic regression (LR) and the mass mean (MM) probe.
Ablation Studies
The study considers sparsity within hidden states, illustrating that reducing dimensional representation does not significantly degrade performance (Figure 2). Analysis of attention heads versus layer residual activations shows the former provide a better representation basis. Additionally, increasing training dataset diversity positively impacts probe performance, suggesting that broader dataset inclusion enhances hyperplane reliability and generalization capacity.
Implications and Future Work
The evidence for a universal truthfulness hyperplane offers new opportunities for improving LLM reliability, particularly in mitigating hallucinations across unseen tasks. Future exploration may consider interventions within the LLMs to enhance model truthfulness or to design alternative probing techniques that further illuminate the truthfulness landscape in deeper and broader model architectures.
Conclusion
This study presents compelling evidence for a universal truthfulness hyperplane within LLMs, marked by improved cross-task generalization and the potential for more robust, factually consistent LLM output. These findings promise advancements in LLM deployment strategies, enhancing model integrity and trust through a better understanding and manipulation of their internal representations.
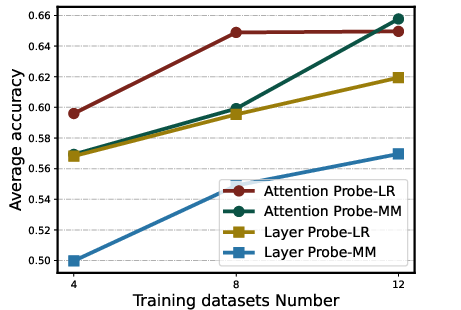
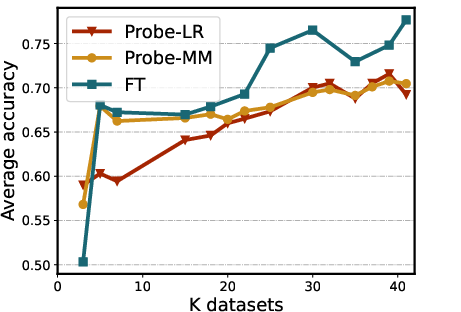
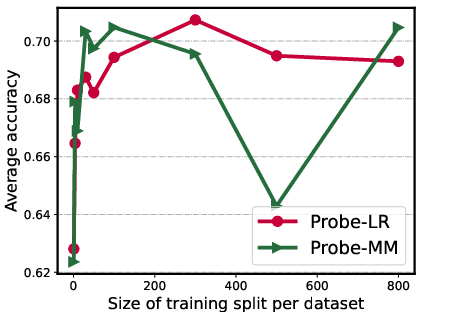
Figure 3: The analysis experiment results of training on attention head and layer activations, scaling number of training tasks, and varying training split size per task.