- The paper demonstrates that middle transformer layers share similar representation spaces, allowing for layer skipping with minimal performance loss.
- It reveals that reordering layers affects tasks differently, with sequential reasoning tasks most sensitive to alterations.
- Experiments with parallel execution and iterative processing suggest viable strategies to reduce computational load while maintaining accuracy.
Introduction
The paper "Transformer Layers as Painters" investigates the internal mechanisms of transformer-based models, specifically examining the necessity and ordering of layers within pretrained transformers. It aims to enhance understanding of the transformers' architecture and explore alternatives for improving efficiency without significantly sacrificing performance. By drawing analogies to an assembly line of painters, the paper explores whether transformer layers share representation spaces and can operate in varying configurations, including skipping, reordering, or parallel execution.
Models and Benchmarks
The study used the Llama2 and BERT models to conduct its experiments. Llama2-7B, with 32 layers, provided the primary testbed, supplemented by scaling tests on Llama2-13B and Llama2-70B. BERT-Large, with 24 layers, served as the encoder-only counterpart. Evaluations included standard benchmarks such as ARC, HellaSwag, GSM8K, WinoGrande, and LAMBADA for Llama2, and the GLUE benchmark for BERT. These models were frozen to eliminate parameter modification during testing, except where GLUE's protocol mandated fine-tuning for BERT.
Representation and Layer Necessity
The paper hypothesizes the existence of shared representation spaces among transformative layers, particularly in the middle segments. This hypothesis arises partly due to the observed robustness of models to layer skipping and switching, except in the initial and final few layers. Activation similarities, measured through average cosine similarity, indicate a consistent representation pattern among middle layers but distinct from the outer layers (Figure 1).
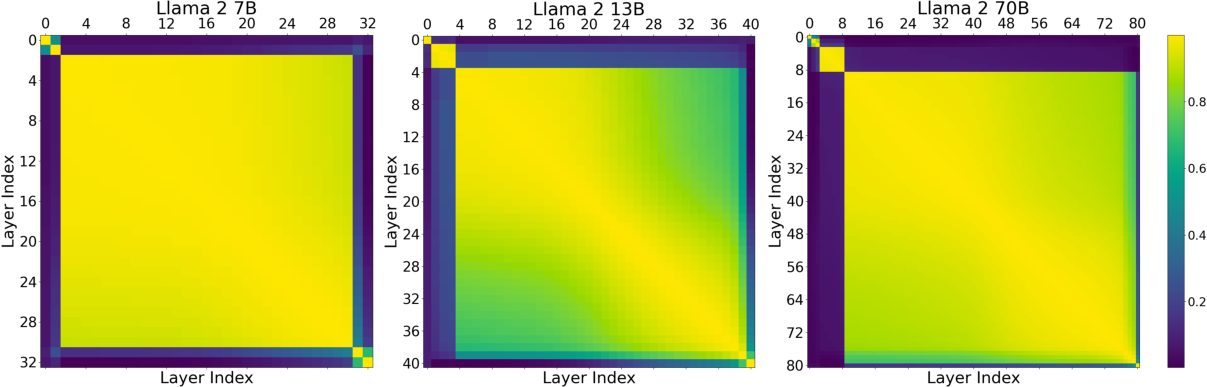
Figure 1: Average cosine similarity between the hidden states of all 32 layers of Llama2-7B (Left) and all 40 layers of Llama2-13B.
Skipping certain layers suggests that not all are critical for maintaining performance. As shown in the experiments, many benchmarks display minimal degradation when intermediate layers are skipped, indicating some redundancy in their specific computations.
Order and Functionality of Layers
The exploration of layer functionality revealed that middle layers, although sharing representation spaces, perform distinctly when their weights are uniform across multiple layers. Replacing middle layers with copies of a central layer resulted in severe performance degradation, highlighting the non-redundancy of their operations (Figure 2).
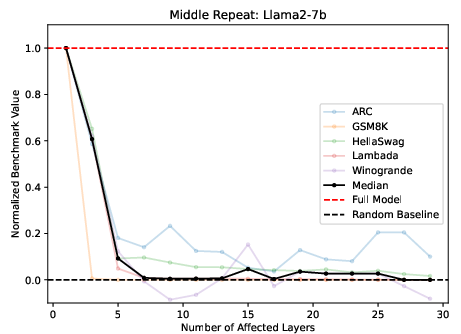
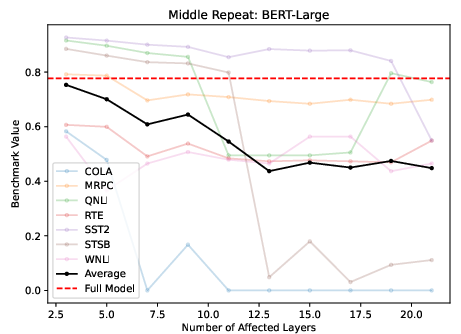
Figure 2: Replacing M middle layers with the center layer (16 for Llama, 12 for BERT) for Llama2-7B (left, normalized benchmarks), and BERT (unnormalized average).
The order of execution showed limited impact on performance, with some tasks being more order-sensitive than others, notably mathematical and reasoning tasks, rather than semantic ones. Herein, tasks reliant on sequential logic revealed greater performance drops under randomized or reversed layer conditions (Figure 3).
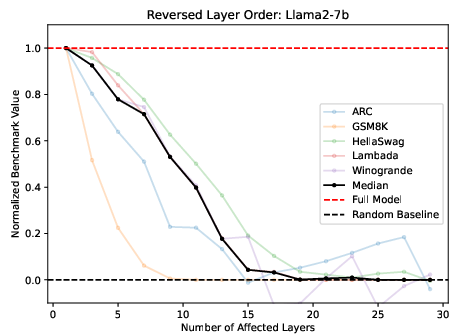
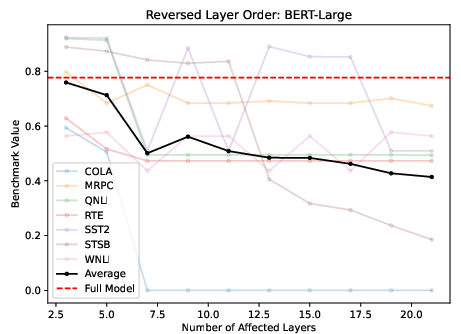
Figure 3: Left: Reversing M middle layers for Llama2-7B, normalized across different Benchmarks. Right: Reversing layers for BERT-Large, unnormalized average.
Parallel Execution and Iteration
Considering layers as independent entities, the parallel execution of layers was viable, albeit with challenges in math-intensive benchmarks. Looping parallelized layers several times ameliorated these effects, suggesting iterative processing harnesses missed contributions in single-pass execution (Figure 4).
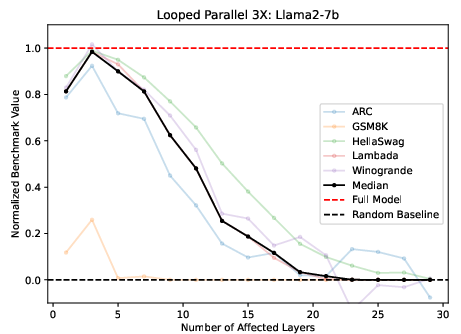
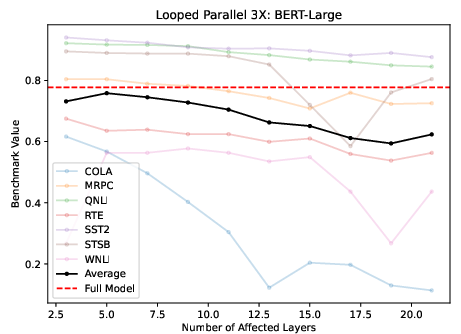
Figure 4: Running M layers in parallel, looping 3 times for Llama2 (left) and BERT (right).
The investigation highlighted that parallelized execution with iteration approximates the base performance best among examined variations, especially when task complexity is lower.
Conclusion
"Transformer Layers as Painters" suggests practical implications for optimizing LLM performance by acknowledging the relative uniformity and interchangeability of middle transformer layers. This work lays the groundwork for formalizing methods to reduce computational loads without detrimental impacts on performance, focusing particularly on the potential for dynamic layer execution strategies. Future research can explore adaptive fine-tuning and incremental adjustments to improve model adaptability and efficiency, providing deeper insights into the emergent properties of transformer architectures.