- The paper introduces enhanced PD-NJ-ODE techniques that integrate output feedback and input skipping to boost long-term prediction accuracy in chaotic and stochastic environments.
- The methodology uses a probabilistic adaptive training approach, reducing dependence on continuous observation data to improve convergence towards L2-optimal predictors.
- Experimental evaluations on double pendulum and geometric Brownian motion datasets demonstrate significant accuracy improvements over standard prediction methods.
Learning Chaotic Systems and Long-Term Predictions with Neural Jump ODEs
The paper "Learning Chaotic Systems and Long-Term Predictions with Neural Jump ODEs" explores the use of Path-dependent Neural Jump ODEs (PD-NJ-ODE) for modeling and predicting the dynamics of chaotic systems and stochastic processes. The authors propose enhancements to the PD-NJ-ODE framework enabling more accurate long-term predictions in both deterministic and stochastic environments.
PD-NJ-ODE Model Overview
The PD-NJ-ODE model is designed to predict the evolution of stochastic processes that may exhibit non-Markovian behaviors and irregular observation patterns. The model aims to converge to the L2-optimal predictor, which is the conditional expectation given available data, based on realizations of the stochastic process without needing to know its law. This feature makes the PD-NJ-ODE a powerful tool for learning dynamics solely from observed data.
One of the key applications is in predicting the dynamics of chaotic systems, such as a double pendulum, where it was observed that predictions tend to diverge over time without appropriate training enhancements.
Enhancements to PD-NJ-ODE Training
The paper introduces two primary innovations to improve long-term predictive performance:
- Output Feedback and Input Skipping: The model is modified to incorporate output feedback, where predictions are used as subsequent inputs. This approach is combined with input skipping, where only selected observations are used as inputs, forcing the model to learn effective long-term predictions by reducing dependency on continuous observation data.
- Adaptive Training Procedures: A probabilistically driven method adjusts which observations are used during training. By dynamically lowering the probability of using certain observations as inputs over training epochs, the model adapts to predict further ahead.
These enhancements aim to address the empirical observation that the standard PD-NJ-ODE framework, without modifications, struggles with long-term prediction accuracy for chaotic and certain stochastic systems.
Experimental Results
The authors provide extensive experimental evaluation using chaotic systems and stochastic datasets to demonstrate their approach's effectiveness. Two significant datasets were used:
- Double Pendulum: The chaotic dynamics of a double pendulum were used to assess the model's ability to predict long-term behavior starting from initial conditions of the angles and momenta of the pendulum arms.
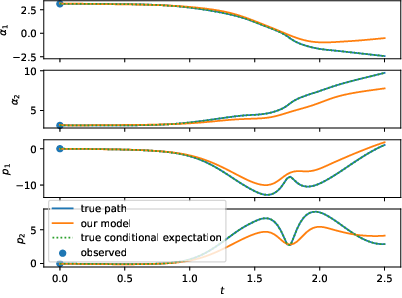
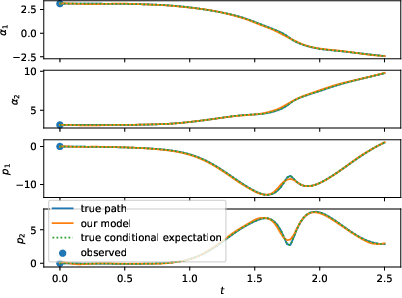
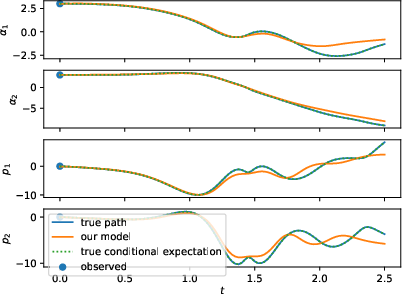
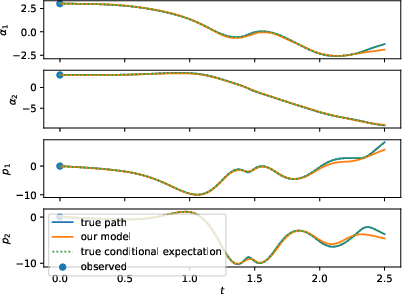
Figure 1: Left: test samples of a Double Pendulum with standard training framework (N). Right: the same test samples of the Double Pendulum with the enhanced training framework and larger dataset (N-OF-IIS-large). The conditional expectation coincides with the process, since it is deterministic.
- Stochastic Systems: Multiple geometric Brownian motion datasets were tested to verify the model's predictions, emphasizing scenarios with varying observation frequencies and dynamic parameters.
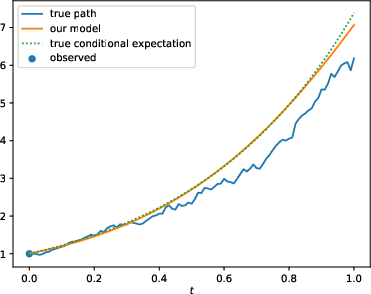
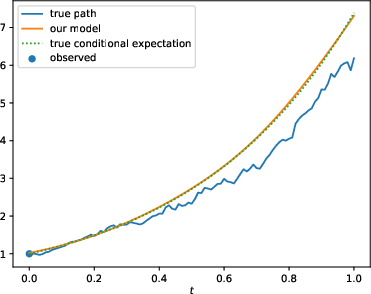
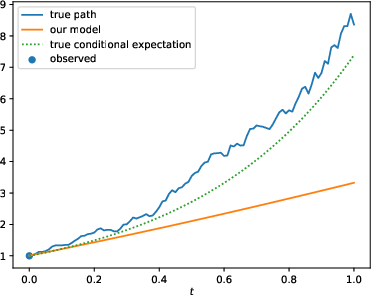
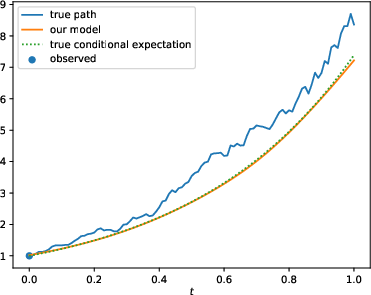
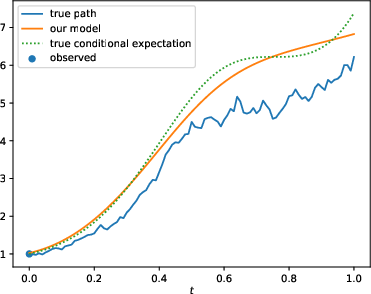
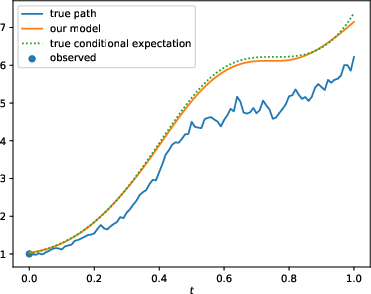
Figure 2: Comparison of the standard (N; left) and enhanced (N-OF-IIS; right) model on a test sample of the BS-Base (top), BS-HighFrequ (middle) and BS-TimeDep (bottom) dataset.
The results show that with the proposed enhancements, PD-NJ-ODE models significantly outperform standard configurations, especially in long-term prediction scenarios, where the regular training fails to maintain model accuracy.
Theoretical Implications and Future Directions
Beyond practical enhancements, the authors assert theoretical convergence guarantees for their modified PD-NJ-ODE framework, extending the scope of the conditional expectation that the model can predict. This supports broader applicability for both chaotic deterministic systems and more general stochastic processes.
The implications for future work include refining adaptive training strategies further and exploring additional domains where PD-NJ-ODE and its enhancements might provide state-of-the-art predictive capabilities. Moreover, integrating these neural ODE approaches with other machine learning frameworks may yield novel hybrid models capable of even more robust and interpretable predictions.
Conclusion
The research presents strong evidence that enhanced training strategies for PD-NJ-ODE can significantly improve long-term prediction accuracy in chaotic systems and stochastic processes. The proposed methods ensure that the models do not merely rely on dense observational data but instead learn to infer future states from limited and strategic inputs, potentially impacting a wide array of applications spanning physics, finance, and beyond.