- The paper introduces Optimus-1, a novel AI agent using a Hybrid Multimodal Memory module that integrates a Hierarchical Directed Knowledge Graph and an Abstracted Multimodal Experience Pool.
- It demonstrates enhanced planning and reflection capabilities, achieving up to a 30% improvement and a sixfold performance increase over baseline models in complex Minecraft tasks.
- Experimental results validate that non-parametric, experience-driven learning can bridge the gap toward human-level performance in long-horizon task execution.
Optimus-1: Hybrid Multimodal Memory Empowered Agents Excel in Long-Horizon Tasks
The paper "Optimus-1: Hybrid Multimodal Memory Empowered Agents Excel in Long-Horizon Tasks" (2408.03615) introduces Optimus-1, an AI agent capable of performing long-horizon tasks within the open-world environment of Minecraft. Building upon existing research that leverages Multimodal LLMs (MLLMs), this paper presents a novel approach to integrate structured world knowledge and multimodal experience to significantly enhance the agent's planning and reflection capabilities.
Introduction to Optimus-1
Optimus-1's development is rooted in addressing the deficiencies in existing AI agents, particularly their struggles with long-horizon tasks in dynamic open-world environments like Minecraft. These agents often fall short due to a lack of structured world knowledge and an inability to learn from multimodal experiences. Inspired by cognitive science insights into human memory, the authors propose the Hybrid Multimodal Memory (HMM) module comprising two key components: the Hierarchical Directed Knowledge Graph (HDKG) and the Abstracted Multimodal Experience Pool (AMEP) (Figure 1).
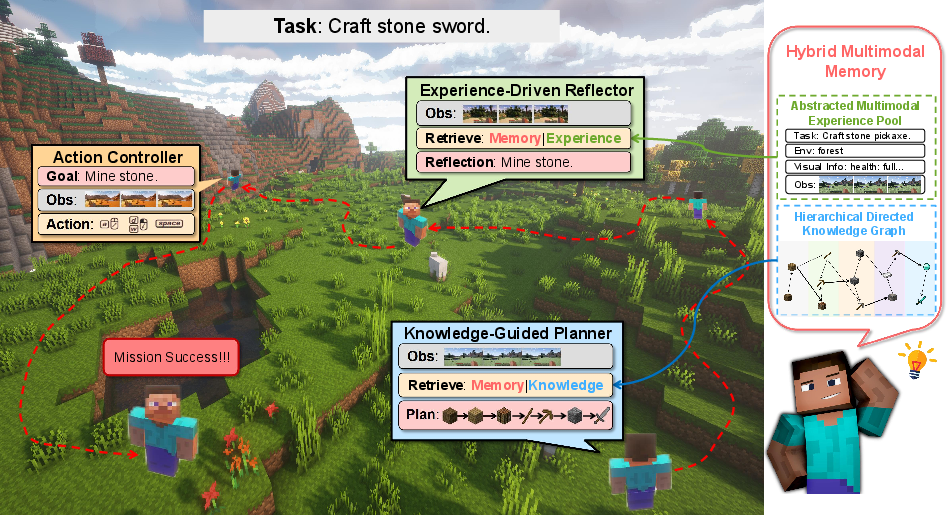
Figure 1: An illustration of Optimus-1 performing long-horizon tasks in Minecraft. Given the task ``Craft stone sword," Knowledge-Guided Planner incorporates knowledge from Hierarchical Directed Knowledge Graph into planning, then Action Controller executes these planning sequences step-by-step. During the execution of the task, the Experience-Driven Reflector is periodically activated and retrieves experience from the Abstracted Multimodal Experience Pool for reflection.
Hybrid Multimodal Memory Module
Abstracted Multimodal Experience Pool
The Abstracted Multimodal Experience Pool (AMEP) addresses the challenge of lacking multimodal historical reference for agents. Existing agents typically rely solely on unimodal experience, failing to harness the full range of multimodal information available from past interactions.
The AMEP's implementation involves a two-stage filtering and mapping process. Initially, visual information is subjected to temporal filtering through a video buffer, using a pace of 1 frame per second to remove redundancy (Figure 2a). Subsequently, frames from the filtered video are processed using an image buffer to maintain significant image diversity before being aligned with corresponding textual sub-goal descriptions. The agent employs MineCLIP to ensure coherence between visual and textual data before storing them within the AMEP, which includes environment data, initial agent states, and task plans, making retrieval both global and locally detailed.
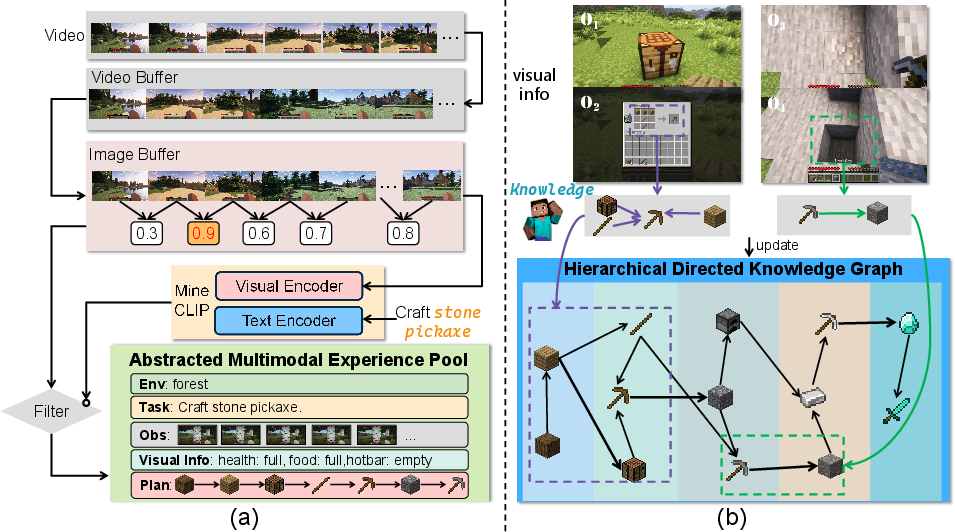
Figure 2: (a) Extraction process of multimodal experience and (b) Overview of Hierarchical Directed Knowledge Graph.
Hierarchical Directed Knowledge Graph
The Hierarchical Directed Knowledge Graph (HDKG) is another fundamental component of the HMM module, primarily responsible for storing and providing structured world knowledge. In open-world environments like Minecraft, this knowledge system enables Optimus-1 to execute complex tasks without parameter updates.
HDKG converts object and resource relationships into a directed graph, where nodes represent objects and edges denote their semantic connections. For example, creating a diamond sword requires structured knowledge about its components, which are stored as node relationships in HDKG (Figure 2b). By retrieving this graph-based knowledge, the Knowledge-Guided Planner can efficiently generate detailed sub-goal sequences for task execution.
Optimus-1 Architecture
The overall architecture of Optimus-1, as presented in Figure 3, is constructed on top of the HMM module, integrating a Knowledge-Guided Planner, Experience-Driven Reflector, and Action Controller, designed to emulate human-like cognitive abilities crucial for long-horizon task accomplishment.
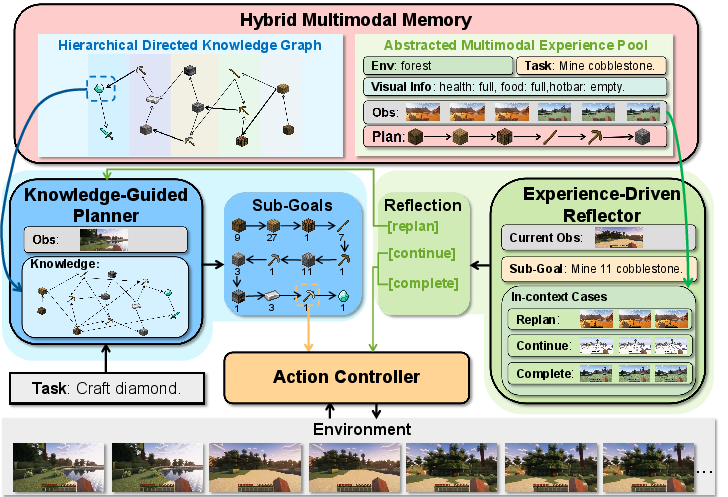
Figure 3: Overview framework of our Optimus-1 comprising the Knowledge-Guided Planner, Experience-Driven Reflector, Action Controller, and Hybrid Multimodal Memory architecture, effectively demonstrating the process of crafting a stone sword.
Knowledge-Guided Planner and Action Controller
The Knowledge-Guided Planner integrates environmental visual conditions into the planning process. Leveraging the HDKG, it derives the necessary sub-goals from a directed graph of object relationships without parameter updates. The Action Controller then operates with the sub-goals and current observations to generate control signals that alter the agent's state in the game environment.
Experience-Driven Reflector
To address errors in task execution, especially in long-horizon tasks, the Experience-Driven Reflector dynamically retrieves multimodal experiences from the AMEP. This mechanism categorizes reflection outcomes as COMPLETE, CONTINUE, or REPLAN based on the success, ongoing, or failure status of the task, thereby prompting the Knowledge-Guided Planner to adjust its strategy if necessary.
Experimental Results
The paper evaluates Optimus-1's performance using a benchmark suite encompassing 67 long-horizon tasks within the Minecraft simulation environment. As demonstrated in Table 1, Optimus-1 shows marked improvement over existing agents on these tasks, achieving up to a 30% improvement, with a performance close to human-level.
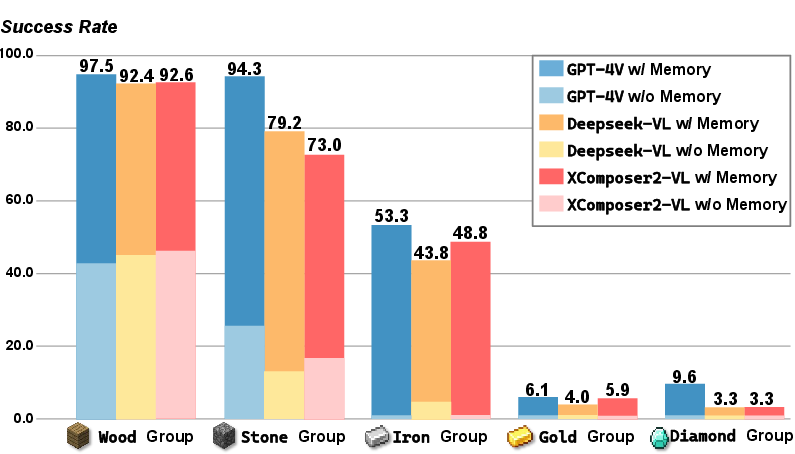
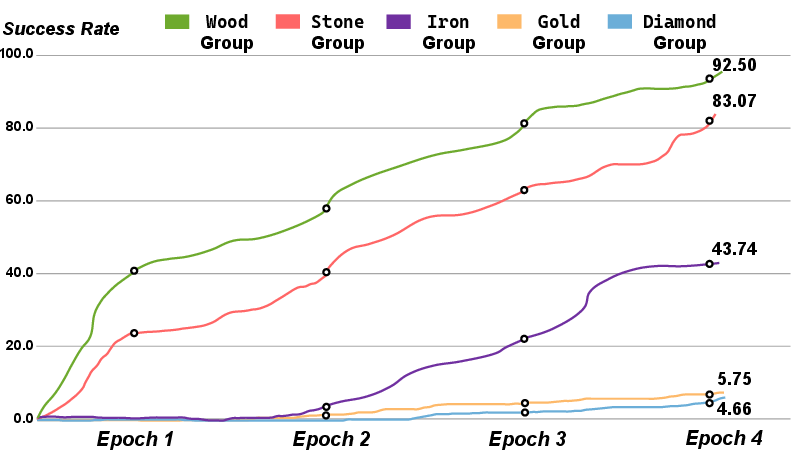
Figure 4: Performance improvement with Hybrid Multimodal Memory demonstrating up to a 6x increase.
Performance metrics—success rate (SR), average steps (AS), and average task completion time (AT)—favorably compare Optimus-1 against GPT-3.5, GPT-4V, DEPS, and Jarvis-1, as shown in Table 1. Notably, Figure 4 reveals significant performance enhancements owing to the HMM module, achieving two to six times the improvement over baselines like GPT-4V.
Conclusion
The implementation of the Hybrid Multimodal Memory module, comprising the HDKG and the AMEP, showcases a significant advancement in AI agent capabilities for long-horizon tasks within open-world environments such as Minecraft. The reliance on non-parametric learning through the innovative "free exploration-teacher guidance" methodology further facilitates Optimus-1's self-evolution. Experimental results substantiate Optimus-1's superior performance in complex task benchmarks, narrowing the gap to human-level capabilities. The success in integrating various MLLMs as Optimus-1’s backbone highlights the potential for deploying these methodologies in broader AI applications beyond gaming environments. Future developments are expected to further enhance the self-evolutionary learning and action execution capacities, expanding the reliance on high-quality video-action data collection during inference.