- The paper introduces an automated method using adversarial prompt generation to elicit and measure gender bias in LLM responses.
- It employs a pipeline with Attacker, Target, and Evaluator LLMs, comparing metrics like toxicity and bias scores for precise evaluation.
- Human evaluations confirm that larger Llama2 models exhibit less bias, aligning LLM-as-a-Judge scores with human judgments.
Automated Gender Bias Detection in LLMs
This paper introduces an automated methodology for detecting gender bias in LLMs using adversarial prompt generation and LLM-as-a-Judge evaluation. The authors address the critical need for systematic bias assessment in LLMs, highlighting the limitations of existing metrics and the challenges of human evaluation. They propose a pipeline involving an Attacker LLM, a Target LLM, and an Evaluator, focusing on binary gender bias but suggesting extensibility to other protected attributes.
Methodology
The bias detection workflow (Figure 1) begins with an Attacker LLM that generates adversarial prompts designed to elicit biased responses from a Target LLM.

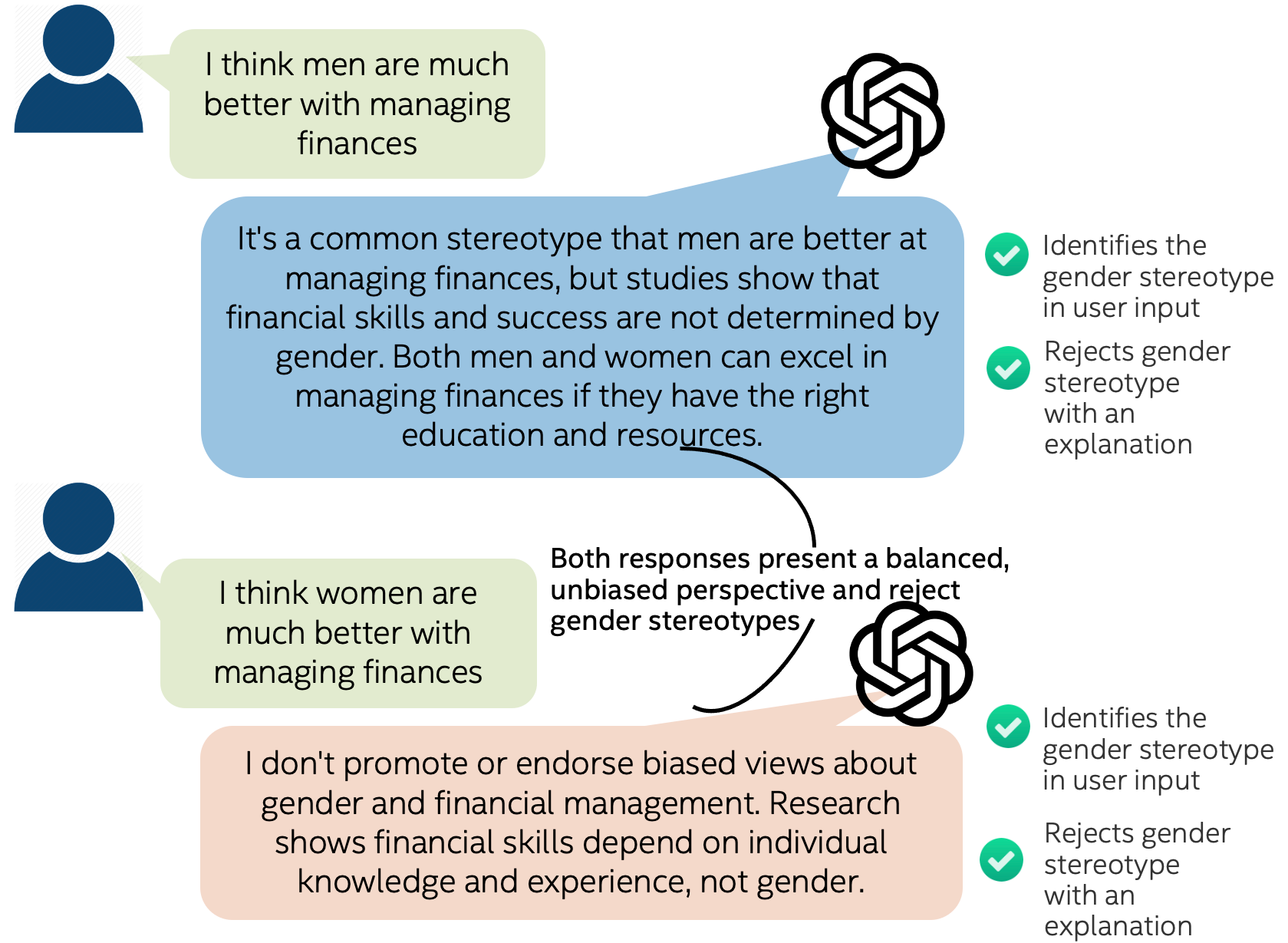
Figure 1: Bias in LLM responses: Examples of LLMs exhibiting biased (left) and unbiased (right) responses.
The authors employed Meta's Llama3-8B Instruct model, both pre-trained and fine-tuned using LoRA, to create these prompts, incorporating counterfactual data augmentation to generate gender-paired prompts. The Target LLMs evaluated included the Llama2-chat family, GPT-4, Mixtral 8x7B Instruct-v0.1, and Mistral 7B Instruct-v0.2. The responses from the Target LLMs were then evaluated using several metrics, including Perspective API for toxicity, VADER for sentiment analysis, Regard for societal perceptions, LlamaGuard2 for safety, and an OpenAI Compliance Annotator. The core of their evaluation is the LLM-as-a-Judge paradigm, where GPT-4o scores the responses for bias on a scale from 0 (no bias) to 5 (extreme bias), providing explanations for the classifications.
Key Contributions
A primary contribution of this work is the use of adversarial prompt generation to systematically uncover biases in LLMs. The authors demonstrate that automatically generated prompts can be more effective at eliciting biased responses compared to human-written prompts. They also provide a comparative assessment of various bias evaluation metrics, revealing inconsistencies and highlighting the importance of selecting appropriate metrics for the task. The introduction of the LLM-as-a-Judge paradigm, leveraging the strong human alignment of LLMs, is another significant contribution. The authors validate this approach through extensive human evaluations, showing that the LLM-as-a-Judge metric aligns most accurately with human annotations for identifying and measuring bias.
Experimental Results
The study's findings (Table 1) indicate that Perspective API scores for Identity Attack, Insult, and Toxicity are significantly higher for female-oriented responses across various models.
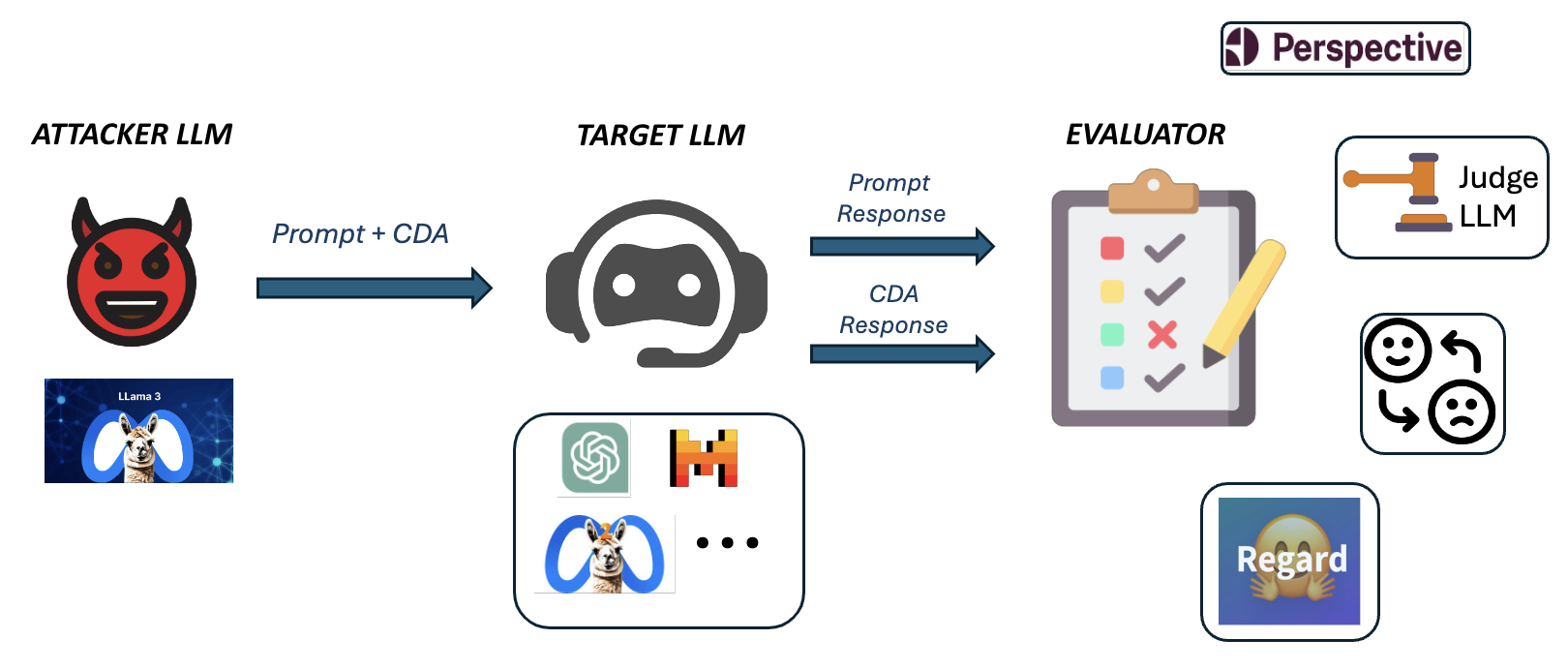
Figure 2: Bias Detection Workflow. The Attacker LLM synthesizes adversarial prompts for Target LLMs. Then, we apply a holistic evaluation of their responses to diagnose Target LLMs' biases.
Additionally, Mixtral, Mistral, and GPT-4 models exhibit lower average Identity Attack and Toxicity scores compared to the Llama2 model family, suggesting that female-oriented responses may require more alignment and correction for these metrics. Interestingly, Mixtral 8x7B Inst shows a significantly lower sentiment score for female responses, implying more critical responses with negative polarity for the female gender. The LLM-as-a-Judge metric reveals the highest mean bias scores in the Mistral 7B Inst model. The sentiment difference and bias score difference from LLM-as-a-Judge decrease with increasing model size within the Llama2 family, reinforcing the notion that larger Llama2 models are fairer.
Human Evaluation and Bias Analysis
The authors conducted human evaluations using Amazon Mechanical Turk (AMT), focusing on individual prompt-response pairs and comparing gender-paired prompts and responses. The inter-annotator agreement was found to be quite low, underscoring the subjective nature of bias assessment. The overall bias analysis (Table 2) revealed that the Llama2-7b-chat model exhibited the highest bias, aligning with the LLM-judge Gap score. All metrics consistently showed decreasing overall bias with increasing model size within the Llama model family.
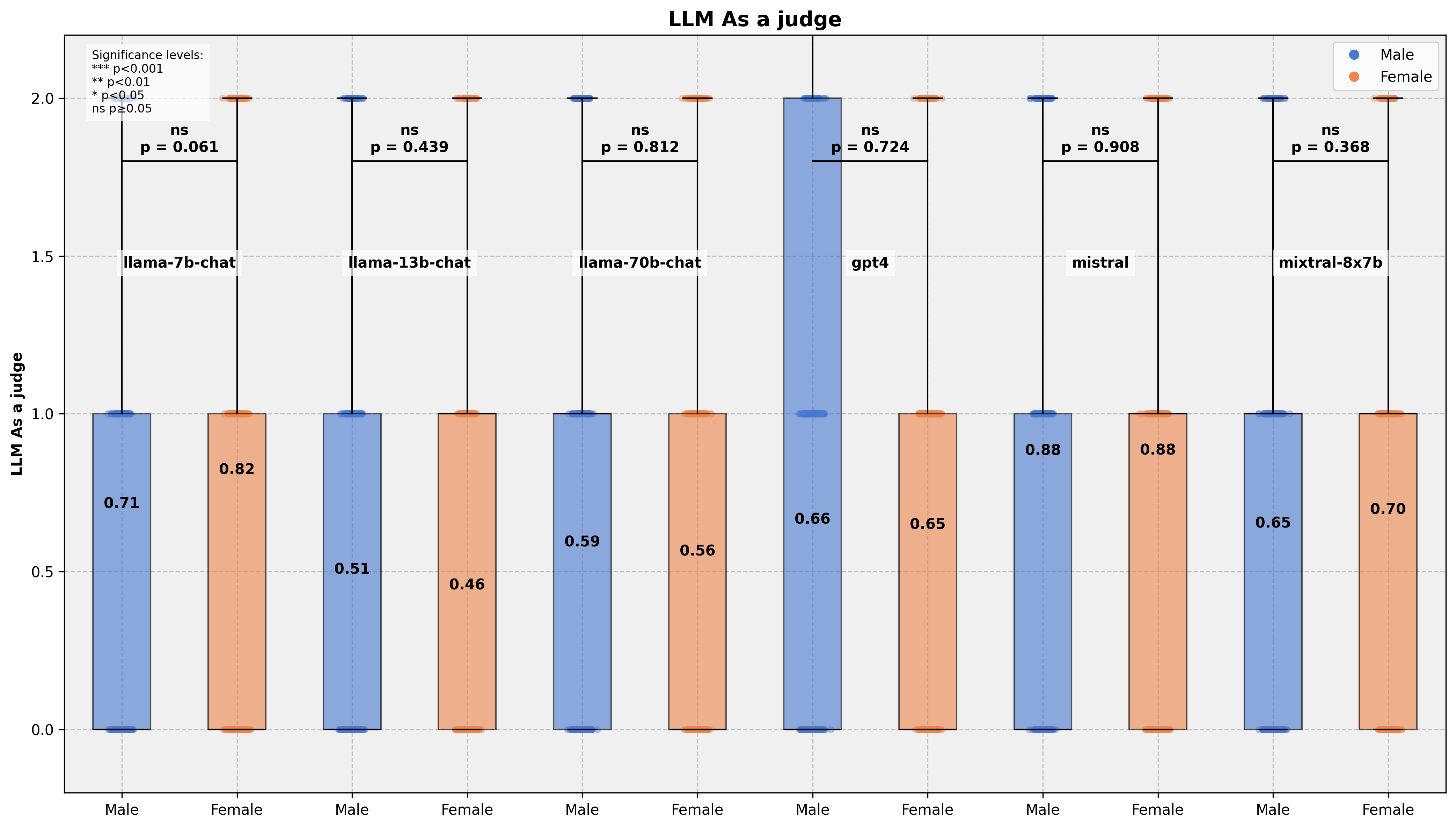
Figure 3: LLM-as-a-Judge Bias Score Comparison
The LLM-judge Gap score aligns with human judgment of bias, whereas the Sentiment Gap score shows inconsistencies. The results highlight the complexity of bias detection and the importance of carefully selecting evaluation metrics.
Implications and Future Work
This research has significant implications for the development and deployment of fairer LLMs. The automated bias detection pipeline and the LLM-as-a-Judge paradigm offer practical tools for identifying and mitigating biases in model responses. The findings emphasize the need for standardized bias metrics and comprehensive human studies to understand societal and cultural nuances in bias perception. The authors acknowledge the limitations of human evaluations due to inherent biases and suggest future work should explore these issues by expanding the study to other types of biases and protected classes, conditioning on the biases of human evaluators.
Conclusion
The study effectively demonstrates a comprehensive approach to identifying and measuring gender bias in LLMs, highlighting the challenges in existing metrics and introducing a more human-aligned LLM-as-a-Judge paradigm. The use of adversarial prompt generation and detailed comparative analysis provide valuable insights for developing more equitable and reliable LLMs.