- The paper introduces a Bayesian framework that leverages posterior convergence and cautious hypothesis testing to bound the probability of harmful actions.
- It employs both I.I.D. and non-I.I.D. data strategies to rigorously estimate risks in safety-critical decision-making scenarios.
- Experimental analysis shows that Bayesian guardrails achieve competitive safety outcomes, reinforcing the potential for safe-by-design AI systems.
Can a Bayesian Oracle Prevent Harm from an Agent?
This paper explores the feasibility of designing AI systems with runtime safety guarantees based on probabilistic bounds, derived from Bayesian principles, to prevent harmful actions. The theoretical framework introduces Bayesian oracles that evaluate context-dependent risks to aid in creating safer AI through cautious hypothesis testing.
Introduction
The rapid evolution of AI capabilities has outpaced the ability of traditional governance and evaluation strategies to ensure safety guarantees. The authors propose an approach where AI systems are designed to adhere to probabilistic safety guarantees, minimizing harm via runtime verification. This involves using Bayesian posteriors to maintain a bound on the probability of safety violations under unknown hypotheses.
The core idea lies in identifying plausible, cautious hypotheses that maximize Bayesian posteriors, effectively guarding against potentially dangerous actions. This theoretical framework addresses the challenge of estimating upper bounds on harm probability using machine learning, allowing AI to decline actions predicted to incur high risk. The notion of 'harm' is contextually bound and needs further specification.
Safe-by-Design AI
The paper situates the research within the "safe-by-design" framework, proposing that AI systems should be developed from the ground up with integrated safety mechanisms. Building on quantitative guarantees seen in other safety-critical domains, such as avionics and nuclear systems, the research underscores the necessity for AI systems to maintain robustness in operation, thereby preventing unintended consequences.
Central to this framework is the Bayesian posterior convergence, dictating that the posterior probability of the true hypothesis should dominate over time as observations increase. This principle is leveraged to infer bounds on safety risks and guide decision-making within AI, emphasizing avoiding harm even with bounded confidence.
Methodology
I.I.D. Data
For independently and identically distributed (I.I.D.) observations, the paper elaborates on posterior convergence using Doob's consistency theorem. As the volume of data increases, the posterior distribution concentrates on the true hypothesis.
A specific proposition, termed True Theory Dominance, is presented, which asserts that, under well-defined conditions, the AI can eventually identify the most plausible hypothesis that minimizes harm even with finite data. This is supported by bounding techniques that engage in hypothesis space exploration through Bayesian optimization.
Harm Probability Bounds
A key contribution is providing bounds on harm probability, enabling verification systems to filter risky actions by evaluating sequences of observations. The method leverages the posterior consistency across hypotheses to establish probabilistic safety thresholds.
Non-I.I.D. Data
In scenarios where data is not I.I.D., a different approach using a supermartingale method is employed to ensure that the posterior on the true hypothesis retains a positive lower bound. The researchers utilize this property to derive bounds that are robust even in the presence of sequence-dependent data.
Propositions such as Weak Harm Probability Bound and Stronger Harm Probability Bound illustrate how to manage risk estimation under non-I.I.D. constraints, offering a systematic way to enforce risk thresholds operationally.
Experimental Analysis
The evaluation centers on a bandit problem designed to simulate decision-making scenarios where the agent must avoid harm. The experimental setup tests various guardrail strategies based on the derived theoretical models against a baseline 'cheating' method, which knows the true hypothesis.
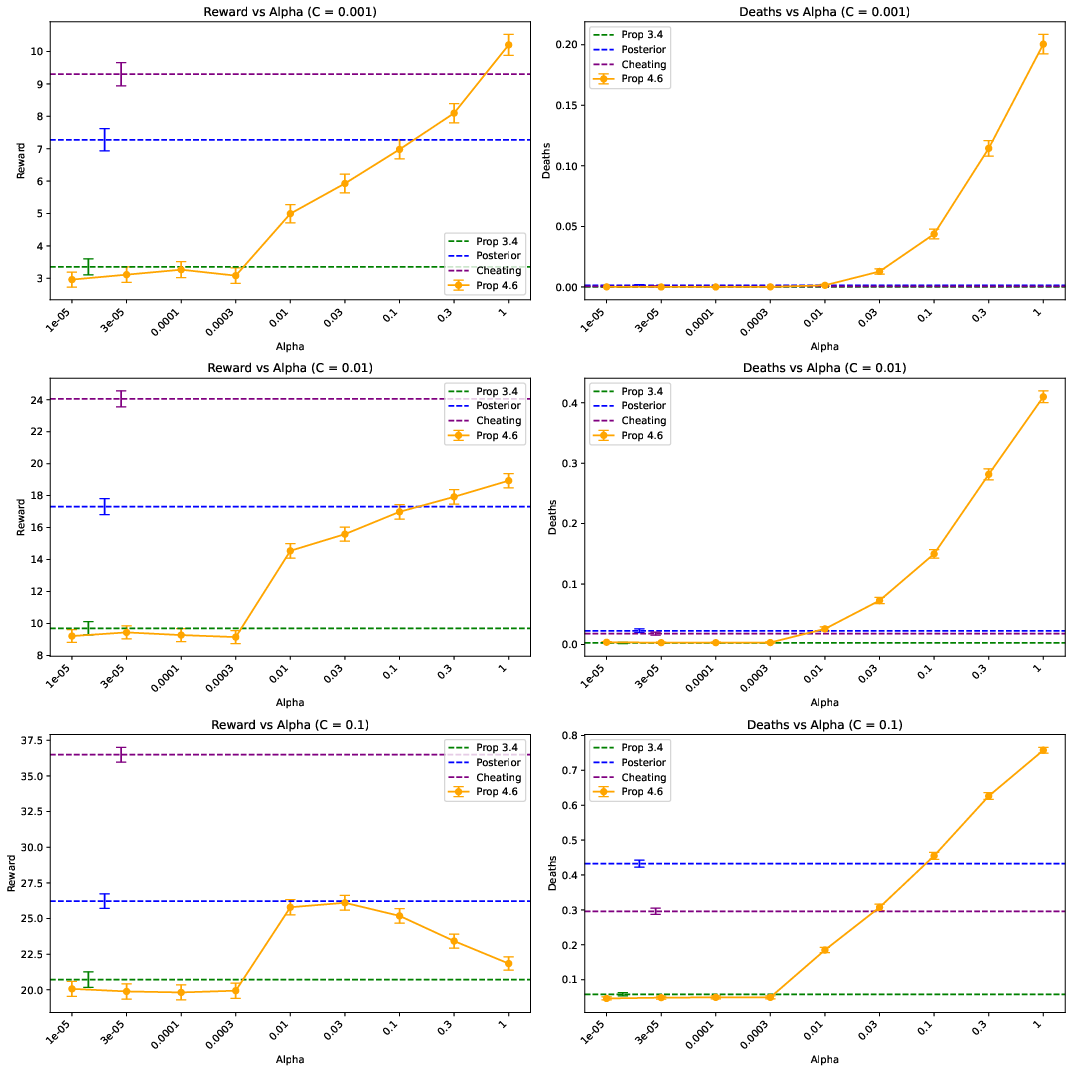
Figure 1: Mean episode deaths and reward for different guardrails in the exploding bandit setting.
The results underscore that Bayesian-derived guardrails achieve competitive safety outcomes, highlighting their potential in practical application. Figure 1 illustrates comparative results, with Bayesian guardrails providing effective risk mitigation against uncertainties.
Conclusion
The study articulates a probabilistic approach to implementing machine learning-based safety mechanisms within AI systems. The Bayesian model provides a foundational scaffold to derive risk-averse actions and integrate runtime safeguards effectively. While promising, the framework necessitates addressing open challenges—particularly in scaling Bayesian inference, defining harm specifications, and managing approximation errors in real-world applications.
Future work is recommended on refining these methods for tractability, such as leveraging amortized inference and exploring enhancements in safety mechanism efficiency, to better translate theoretical guarantees into operational systems capable of robust, autonomous operation.