- The paper introduces RED-CT, a methodology leveraging LLM-labeled data and confidence-informed sampling to train efficient, accurate edge classifiers.
- It integrates active learning, soft labels, and expert annotations to mitigate data noise and enhance classifier performance.
- The approach outperforms full-scale LLMs on tasks like stance detection and misinformation identification while reducing computational costs.
RED-CT: A Systems Design Methodology for Using LLM-labeled Data to Train and Deploy Edge Classifiers for Computational Social Science
This paper introduces RED-CT, a novel methodology for effectively harnessing LLMs to improve linguistic classifiers deployed in resource-constrained edge environments. The approach leverages LLMs as data annotators and integrates system intervention measures to enhance performance across various computational social science tasks.
Introduction and Motivation
LLMs have significantly advanced NLP capabilities, offering robust performance in text classification tasks such as emotion, stance, and misinformation detection. However, deploying these models in production environments is often fraught with hurdles, including cost, network security, privacy constraints, and latency issues in air-gapped systems. RED-CT proposes a systematic solution by utilizing LLM-labeled data to train smaller, more efficient classifiers tailored for edge deployments.
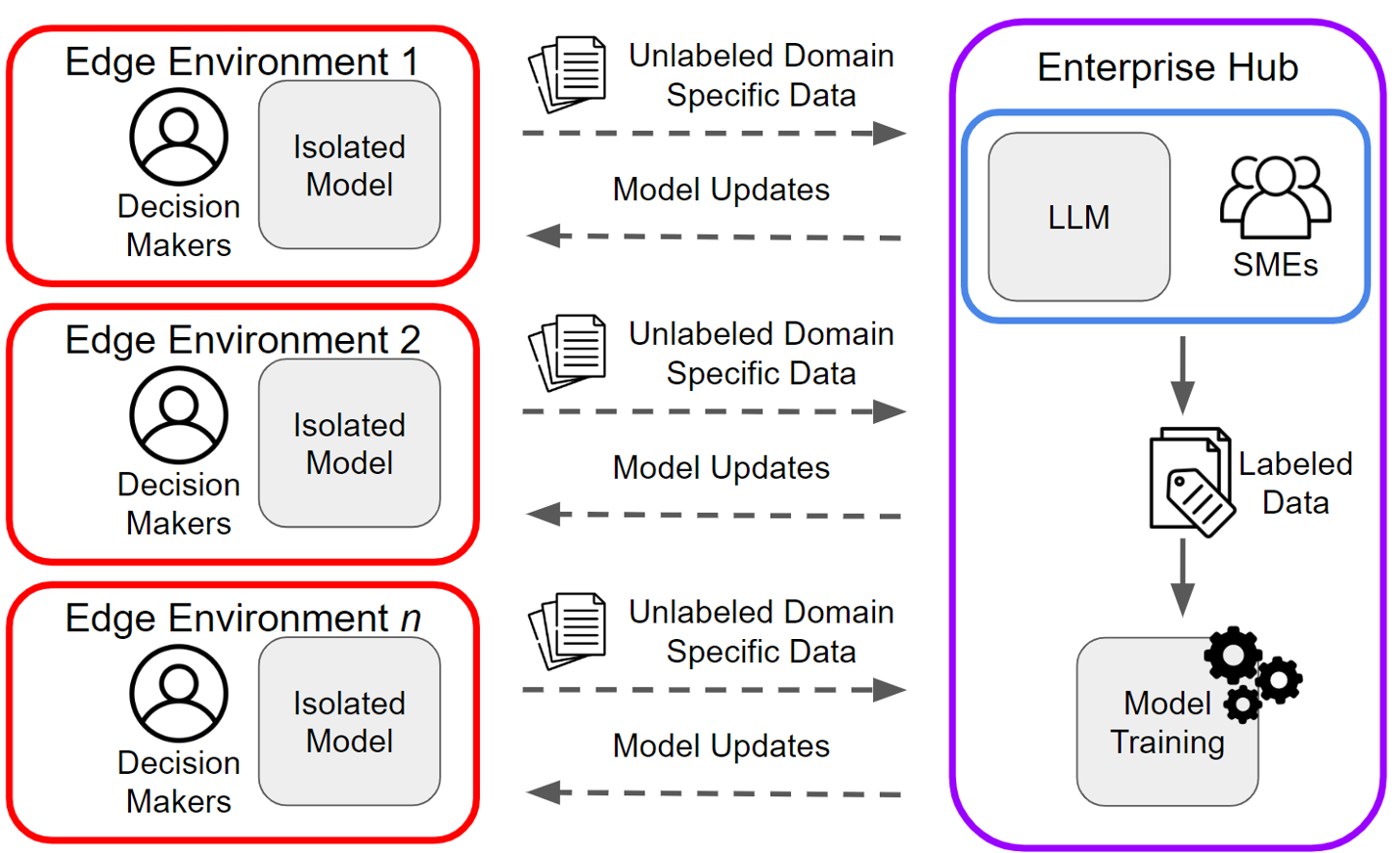
Figure 1: RED-CT design which allows LLM-like capabilities for NLP tasks deployed in edge environments.
Methodology
RED-CT System Overview
RED-CT aims to optimize the deployment of NLP classification tools in environments with limited connectivity and computational resources. This framework integrates active learning techniques, such as confidence scores and soft labels, within a modular design to facilitate rapid edge deployment. The methodological process involves the following steps:
- Data Collection and Labeling: Data is collected at the edge, labeled using LLM predictions, augmented by enterprise hub analysts, and partially validated by SMEs.
- Edge Classifier Training: Leveraging BERT-based models, classifiers are fine-tuned on LLM-labeled datasets, incorporating a small subset of expert-labeled samples for increased accuracy.
- Systems Intervention Methods: Interventions include confidence-informed sampling to select examples for human annotation and learning with soft labels to reduce overfitting on noisy LLM predictions.
One pivotal aspect of RED-CT is the confidence score mechanism which directs the selection of samples for expert annotation. This measure is derived from token probability distributions within LLM outputs, specifically targeting low-confidence samples for human review. Additionally, the use of soft labels, derived from the expit function applied to LLM-generated token probabilities, accounts for the annotator's uncertainty and enhances model generalization.
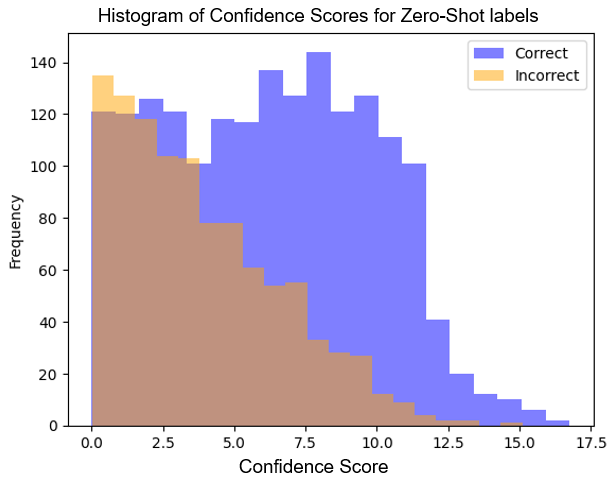
Figure 2: The distribution of confidence scores for examples labeled correctly and incorrectly using gpt-3.5-turbo zero-shot stance classification. The distributions are overlaid as opposed to stacked.
Evaluation and Results
The efficacy of RED-CT was tested across tasks such as stance detection, misinformation identification, ideology detection, and humor detection using datasets with established performance benchmarks. The results demonstrate that edge classifiers trained via the RED-CT methodology can outperform LLMs on numerous instances with minimal human input, reducing costs and increasing scalability.
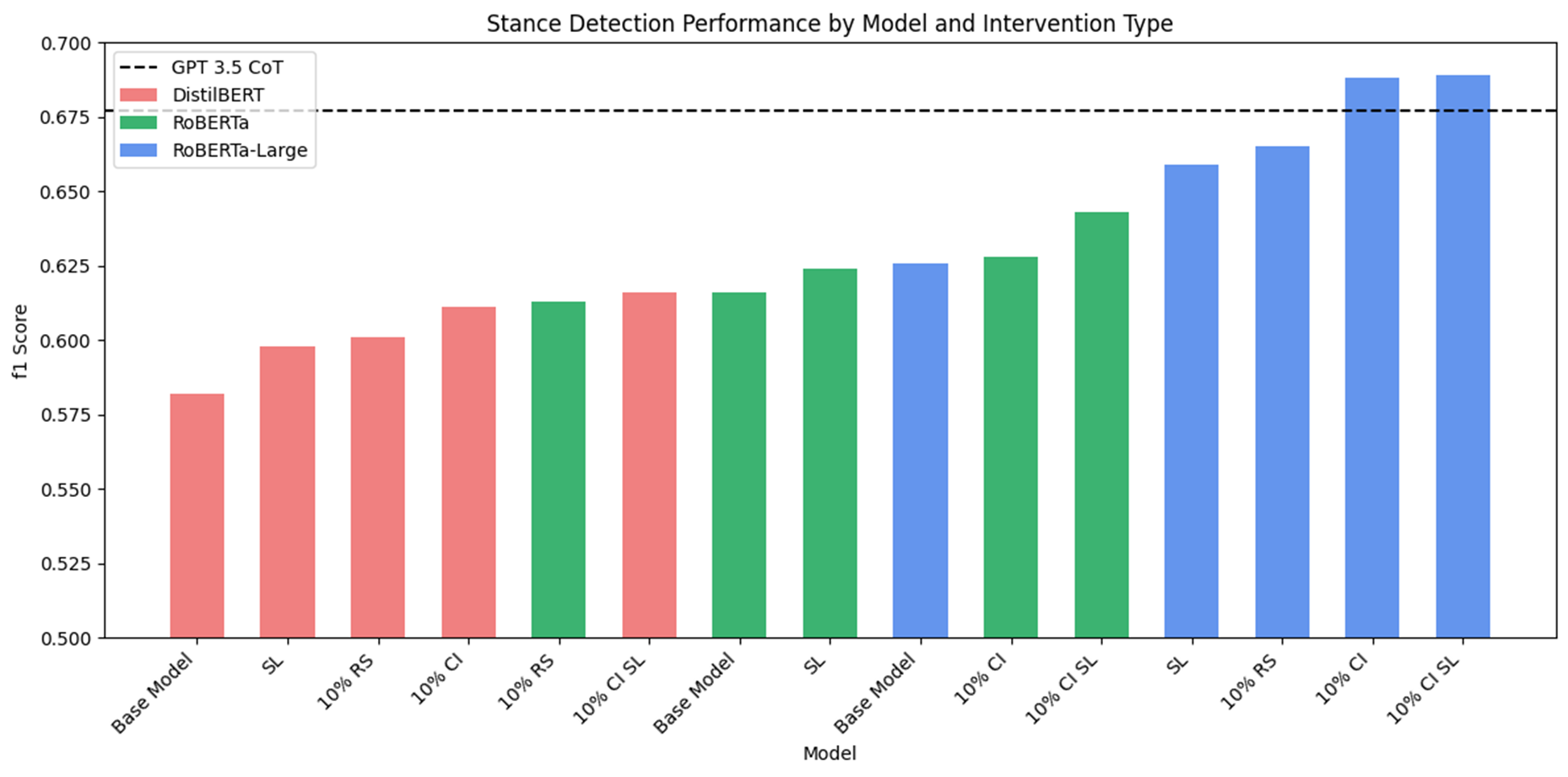
Figure 3: Comparing edge model F1 score as we change model and system interventions types for stance detection. We note steady improvements of edge model performance as we introduce more complex models and system intervention measures. The largest edge model with all system interventions out-performs gpt-3.5-turbo CoT.
Discussion
The results highlight the potential of combining human-in-the-loop strategies with automated LLM labeling for robust model performance in edge applications. The system intervention measures crucially underpin this methodology by tailoring the training process to address LLM prediction errors and biases efficiently. For example, confidence-ranked expert sampling mitigates biases inherent in LLM-training data and enhances the overall classification accuracy.
Conclusion
RED-CT offers a strategic framework for deploying NLP models in edge environments, integrating LLM-labeled data with system interventions to mitigate costs and reliance on extensive datasets. This methodology provides a scalable, efficient solution for deploying resource-light classifiers in environments constrained by security and computational resources.
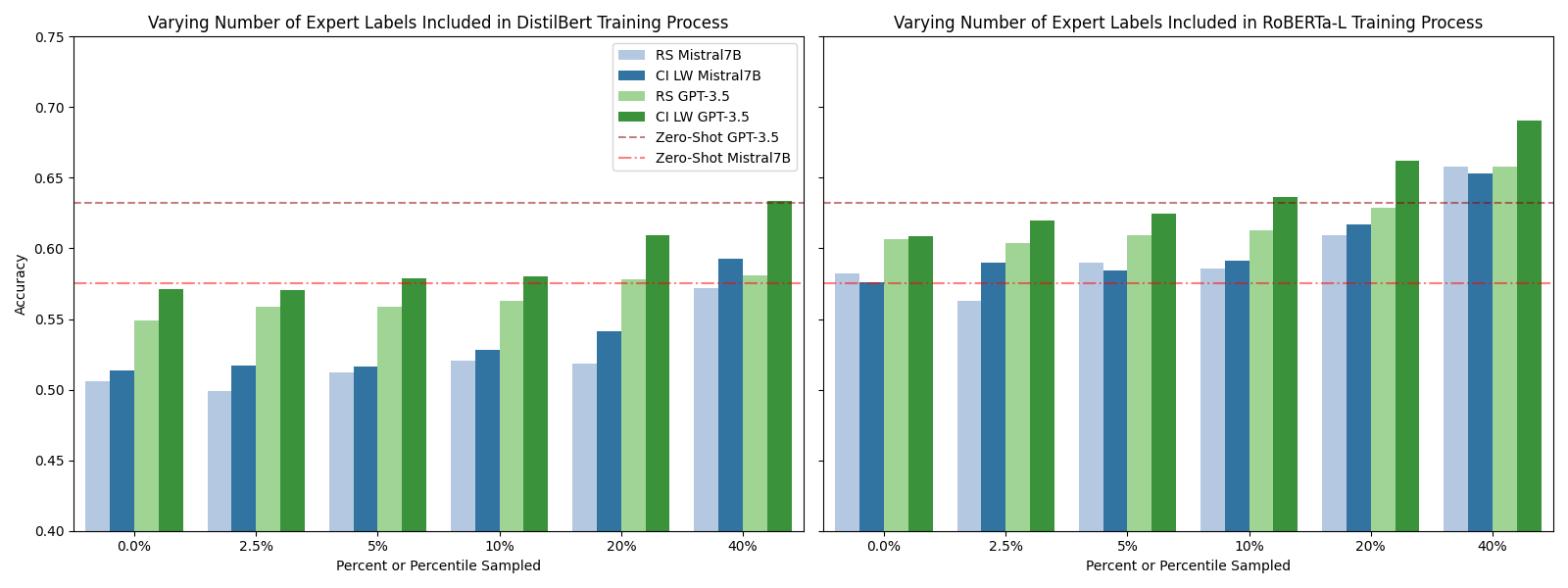
Figure 4: Varying the number of expert labels included amongst the LLM labels in the training process for DistilBERT and RoBERTa-L. RS implies randomly sampled expert labels for the training process and CI SL implies confidence informed sampling with label weighted training.
In summary, the RED-CT framework underscores the potential for intelligent systems that optimize the deployment of modern AI into critical, resource-constrained applications, setting the groundwork for future large-scale implementations in computational social science.