- The paper introduces rough convex cone embeddings that model both rigid and fuzzy membership to enable sub-entity answer retrieval in MMKGs.
- It redefines FOL operators to operate on these embeddings, achieving up to 56.5% MRR improvement on sub-entity queries over existing approaches.
- The framework integrates a novel scene graph generation and mapping pipeline to dynamically extract fine-grained answers from multi-modal data.
RConE: Rough Cone Embedding for Multi-Hop Logical Query Answering on Multi-Modal Knowledge Graphs
Introduction
Multi-Hop Logical Query Answering (MLQA) on Knowledge Graphs (KGs) involves responding to queries comprising complex logical constructs (notably First-Order Logic, FOL) over large graphs. When KGs are extended to include multiple modalities—such as images, text, and video—the resultant Multi-Modal Knowledge Graphs (MMKGs) enable more detailed and nuanced knowledge representation. Despite the growing body of work on logical query answering in unimodal KGs, prior methods cannot systematically leverage the rich, intrinsic features of multi-modal entities. Further, queries whose answers lie within sub-entities of multi-modal objects (e.g., colors within an image) are intractable for extant systems. "RConE: Rough Cone Embedding for Multi-Hop Logical Query Answering on Multi-Modal Knowledge Graphs" (2408.11526) introduces a geometric embedding framework, RConE, for MMKGs that addresses these limitations by introducing a rough convex cone embedding designed to handle multi-hop FOL queries and support answer retrieval at a finer (sub-entity) granularity.
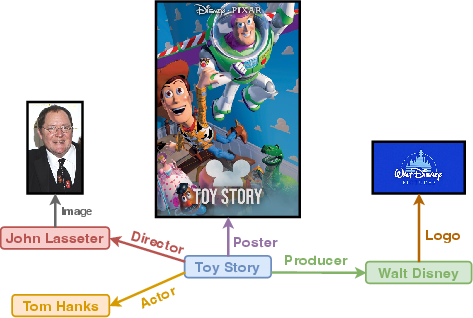
Figure 1: A toy example of a Multi-Modal Knowledge Graph, consisting of images (Toy Story (Poster), John Lasseter (Image), and Walt Disney (Logo)) as a modality, along with regular entities.
Existing frameworks for logical query answering (e.g., BetaE, ConE) embed queries and entities using geometric or probabilistic regions, enabling differentiable FOL operator computation for unimodal KGs. However, these approaches either (i) ignore the intrinsic multi-modal features, thus discarding crucial semantic cues, or (ii) cannot retrieve sub-entity answers from complex entities. Generating scene graphs (sub-KGs) in an offline manner is computationally and spatially prohibitive. Critically, many queries in MMKG settings demand answers refer to intra-entity details (e.g., a shirt's color within a movie poster), not entire entities.
RConE seeks to (1) embed both entities and their sub-entities alongside queries into a unified geometric space, (2) revise FOL operator definitions to accommodate the boundaries between complete membership, partial membership, and exclusion, and (3) propose an efficient mechanism for sub-entity answer extraction without a pre-materialization of all scene graphs.
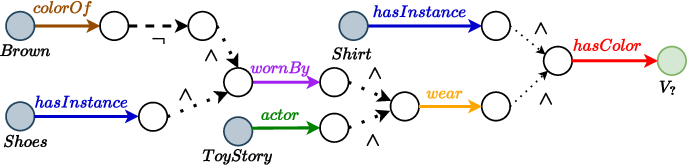
Figure 2: Computational graph for the FOL query corresponding to multi-hop query answering, illustrating entity set distributions and operator-induced transformations.
RConE Embedding Model
Rough Convex Cone Embeddings
RConE builds on sector-cone embeddings (as in ConE), extending these to "rough convex cones" by adding a fuzzy (boundary) aperture to each cone. Each embedding is parameterized as a triplet (θax,θri,θfu) where:
- θax: Semantic axis in d-dimensional embedding space;
- θri: Rigid aperture (coverage of full membership);
- θfu: Fuzzy (boundary) aperture (partial membership region).
This extension facilitates modeling partial semantic similarity, crucial for capturing entities like images containing answer sub-entities within them.
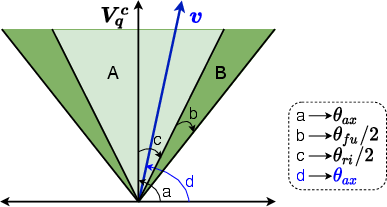
Figure 3: RConE embedding parameterization with rigid and fuzzy regions, showing entity and query locations relative to the answer set.
Logical Operator Redefinition
RConE adapts FOL operators—projection, intersection, complement, and union—to operate on these rough convex cones. This entails:
- Projection: Relation-dependent cone translation via learned MLP transformation, updating all three parameters.
- Intersection: Geometric intersection of rough sets, with rigid and fuzzy overlaps computed via attention-weighted and neural set modules.
- Complement: Axis reversal and region subtraction, flipping membership semantics.
- Union: DNF-form union of cone embeddings, handled non-iteratively for computational efficiency.
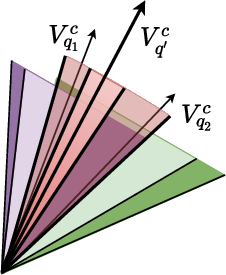
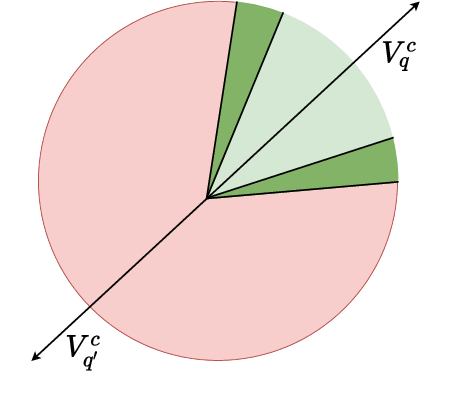
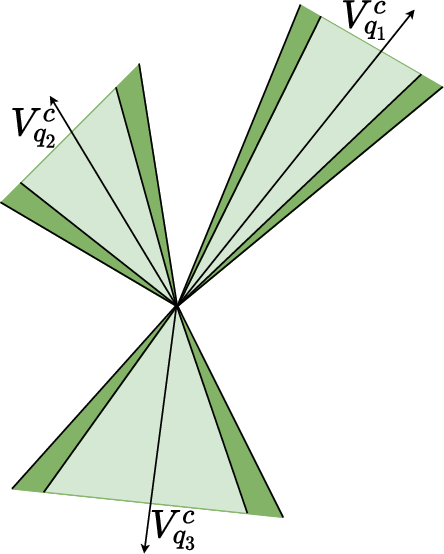
Figure 4: The effect of different logical operators on RConE embeddings—projection, intersection, complement, and union—across $1$-ary cases.
Sub-Entity Prediction via Modular Pipeline
The sub-entity prediction module executes the following pipeline:
- Scene Graph Generation: For each candidate multi-modal entity in the fuzzy region, generate scene graphs using a FCSGG-based zero-shot visual model pre-trained on Visual Genome.
- Scene Graph Embedding: Each sub-entity graph is independently embedded into a (non-cone) ComplEx space.
- Graph Transformation: Sub-entity embeddings are mapped to the RConE space using a transformer module that attends to both intra-scene context and the surrounding KG entity-neighborhood.
The pipeline enables localization and semantic mapping of answers at the sub-entity level.
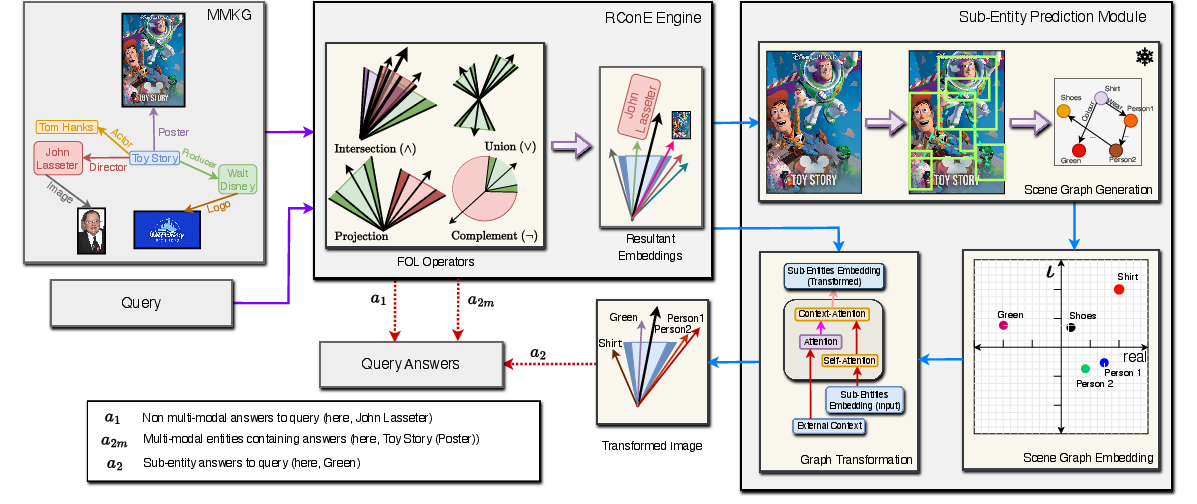
Figure 5: Overall RConE framework, moving from MMKG and query input through the RConE Engine and Sub-Entity Prediction module.
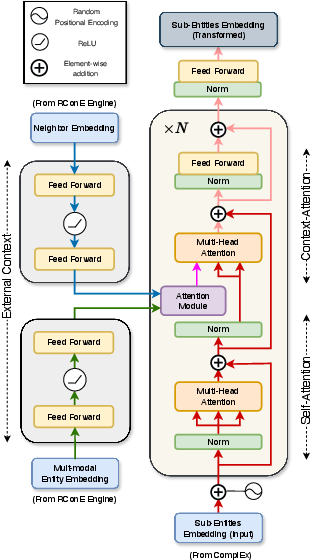
Figure 6: Graph Transformation module, mapping scene graph embeddings to the RConE space with external context via attention.
Query Generation and Training
RConE introduces a query generation module to create training and test queries with both entity-level and sub-entity (scene graph) answers, supporting 14 different FOL query structures. Scene graphs are linked to their parent MMKGs using ComplEx-based link prediction, enabling both types of queries (Type I: sub-entity answer; Type II: normal entity answer).
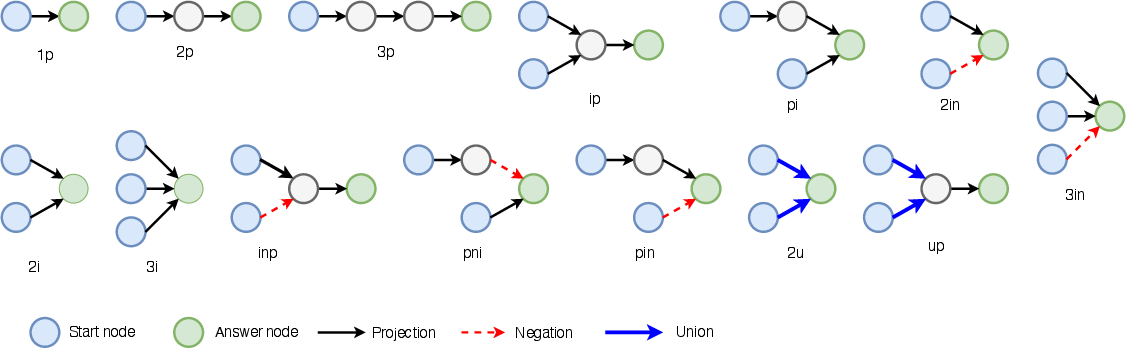
Figure 7: Query structures employed for logical multi-hop query generation over MMKGs.
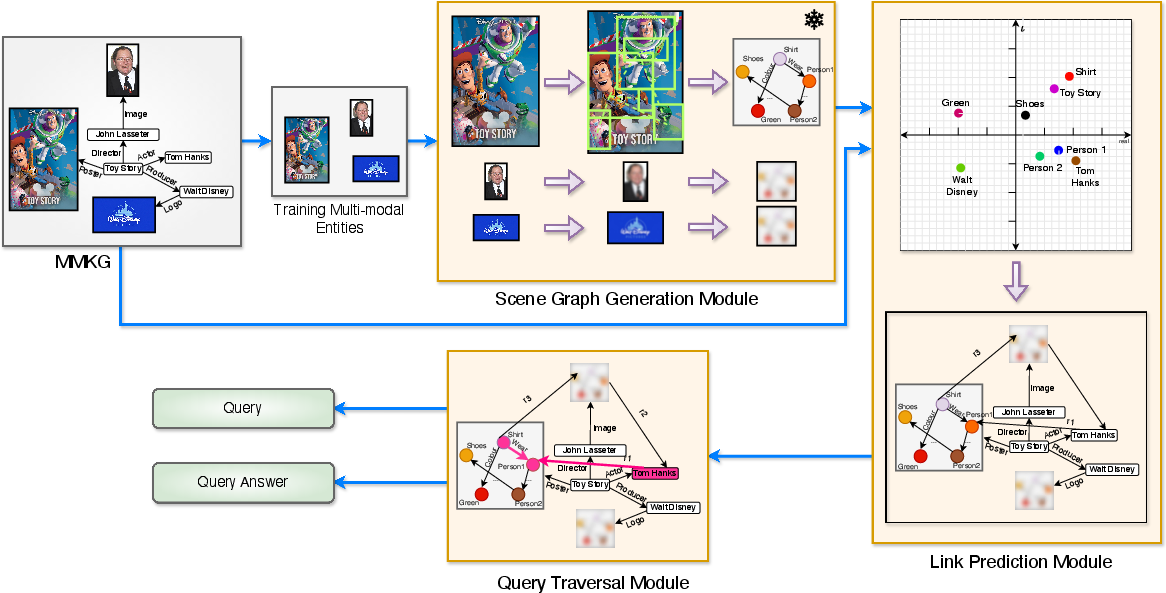
Figure 8: The full query generation pipeline leveraging scene graph generation and traversal for multi-modal, multi-hop queries.
Experimental Results
Extensive evaluation on four public MMKGs (FB15k, FB15k-237, YAGO15k, DB15k) and a control unimodal set (FB15k-NMM) shows:
- Type I Queries (sub-entity answers): RConE achieves MRR improvements of up to 56.5% over ConE and BetaE across datasets. HITS@10 for candidate entities and scene sub-entities remains consistently high (e.g., >80% in FB15k and FB15k-237).
- Type II Queries (entity answers): RConE's performance is within a reasonable bound of ConE, indicating negligible regression even when handling more general queries (see Tables 3 and 4).
- Model Robustness: On the unimodal dataset, RConE matches ConE's performance, confirming that the fuzzy cone extension does not degrade baseline model behavior.
Tables are omitted here per instructions; refer to the source for detailed ablation and structure-wise breakdowns.
Practical and Theoretical Implications
RConE constitutes the first end-to-end system able to propagate FOL queries through MMKGs and retrieve answers at sub-entity granularity, integrating image and scene analysis into a differentiable, geometric reasoning framework. This enables:
- Fine-grained semantic question answering in domains where entities are inherently heterogeneous (e.g., biomedicine, multimedia search).
- Training and inference that avoids exhaustive scene graph enumeration, instead dynamically generating and mapping as needed for candidate entities.
- A geometric semantics for multi-modal partial membership, with implications for future work on multi-modal logical reasoning, cross-modal alignment, and inductive KG reasoning.
Future Directions
Obvious extensions lie in broadening modalities (e.g., fusing audio, text) and scaling the attention-based scene graph transformer for more complex entity contexts. Additionally, further integration of inductive logic and cross-modal data fusion can be explored to address queries that require aggregating evidence from disparate modalities.
Conclusion
RConE advances the state-of-the-art in logical query answering over MMKGs by introducing rough convex cone embeddings, redefining logical operator semantics, and providing an efficient, modular framework for sub-entity question answering. The architecture demonstrates strong empirical performance for multi-modal answers, while maintaining generalization to classical unimodal cases. RConE's methods and supporting datasets open new research directions in multi-modal KG reasoning and serve as a robust foundation for next-generation complex multi-modal QA systems.