- The paper presents a phase-aware, RL-guided routing method that reduces E2E latency by 11.43% compared to round-robin scheduling.
- It employs a fine-grained workload model that distinguishes prefill and decode phases using an output length predictor to steer requests efficiently.
- The paper demonstrates that intelligent routing flattens TTFT variance and minimizes queuing delays, challenging classical instance-local optimizations.
Workload-Aware Routing for LLM Serving: Reinforcement Learning with Phase-Aware Scheduling
Motivation and Problem Characterization
LLM inference now constitutes a dominant class of GPU workloads, especially within public cloud and SaaS APIs. The inference pipeline includes two core stages: prefill (prompt ingestion, typically compute-bound) and decode (output token generation, typically memory-bound due to sequential context accumulation). The bulk of existing system-level literature has focused on instance-local schedulers, employing batching algorithms at the LLM instance to optimize for either throughput or end-to-end latency. However, these methods do not address the top-level routing problem, i.e., how to dynamically assign incoming, heterogeneous requests to distinct LLM instances at scale.
This paper addresses that gap: it empirically demonstrates that naively interleaving requests with diverse prompt/decode characteristics on a single instance results in significant, avoidable latency spikes and wasteful queuing. It provides theoretical and practical evidence that, under real-world prompt and decode distributions (as shown for Llama 2 7B traffic), routing decisions that jointly account for phase-level heterogeneity can yield substantial improvements in E2E latency.
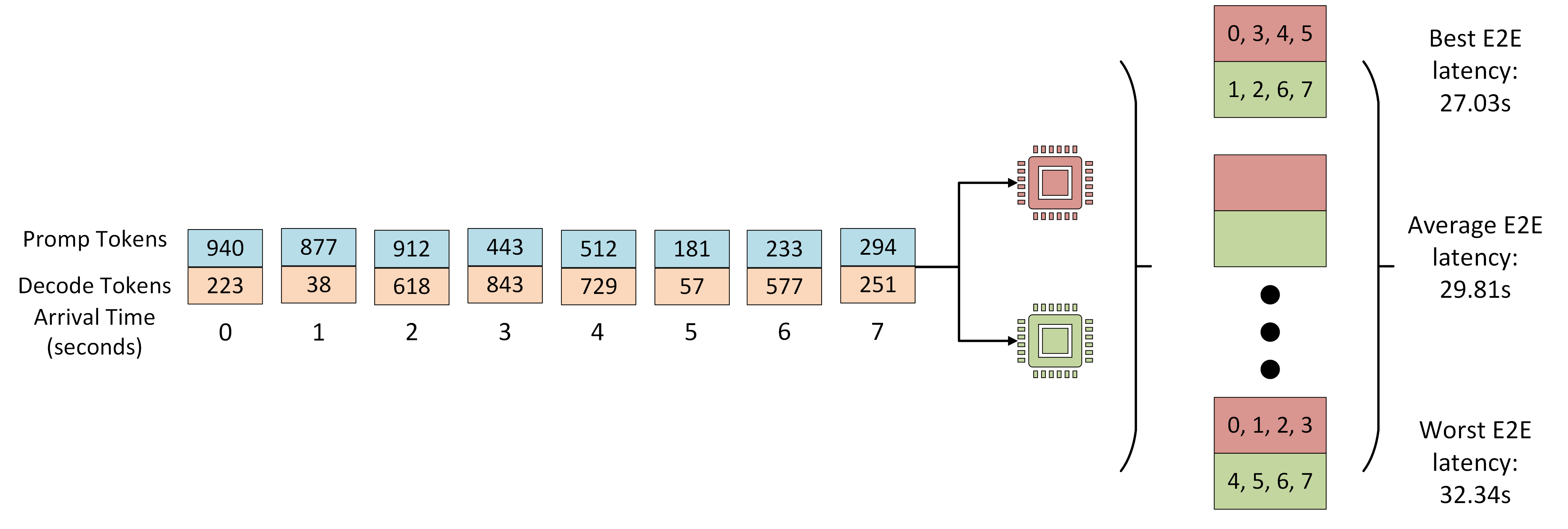
Figure 1: The experimental set up evaluates routing strategies using heterogeneous request sequences, demonstrating gaps between optimal and random assignment to LLM instances.
Empirical Analysis: Characterizing and Predicting Workload Heterogeneity
Rather than treating all requests as atomic jobs, the work introduces a fine-grained, phase-aware workload model. Request classes are defined along two dimensions: prefill (prompt) and decode, each partitioned into light/heavy according to empirically profiled execution time intervals. Using a mixed workload derived from code completion, conversational, summarization, translation, and sentiment analysis tasks, the study illuminates clear diversity in phase requirements (Figure 2). This heterogeneity translates into sharply different performance impact when requests are mixed—decode latencies are less sensitive to batching, but prefill remains highly susceptible to interference.
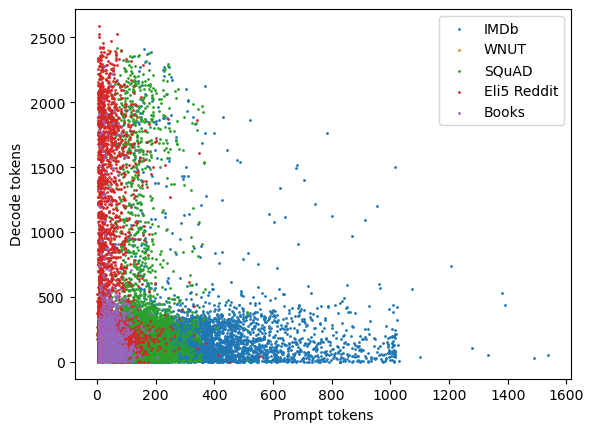
Figure 2: Prompt and decode distributions per dataset class, revealing multimodal, heavy-tailed workload characteristics across common LLM application tasks.
A lightweight output length predictor is introduced, leveraging a fine-tuned DistilBERT classifier with task-type hints (task classification is >93% accurate). Unlike previous approaches that bucket by output length alone, this predictor uses variable-width buckets tied to expected latency. Explicitly encoding task type as a prompt suffix yields a substantial improvement (from ≈6% to ≈40–80% bucket accuracy, varying by task), which is essential for steering requests to the least congested or most phase-compatible instance.
The latency impact estimator formalizes the cost of admitting a request into a model’s batch, capturing both prompt-phase and decode-phase contention. The estimator is parameterized by gradients profiled for the specific hardware–model pair, ensuring portability, and computes anticipated batch execution time by linearly weighting the number of tokens and current phase state of all requests on the candidate instance.
This penalty function rmixing(st,st+1) is incorporated into the reward for routing policies, explicitly discouraging assignments that combine heavy prefill with existing heavy decode jobs on the same GPU.
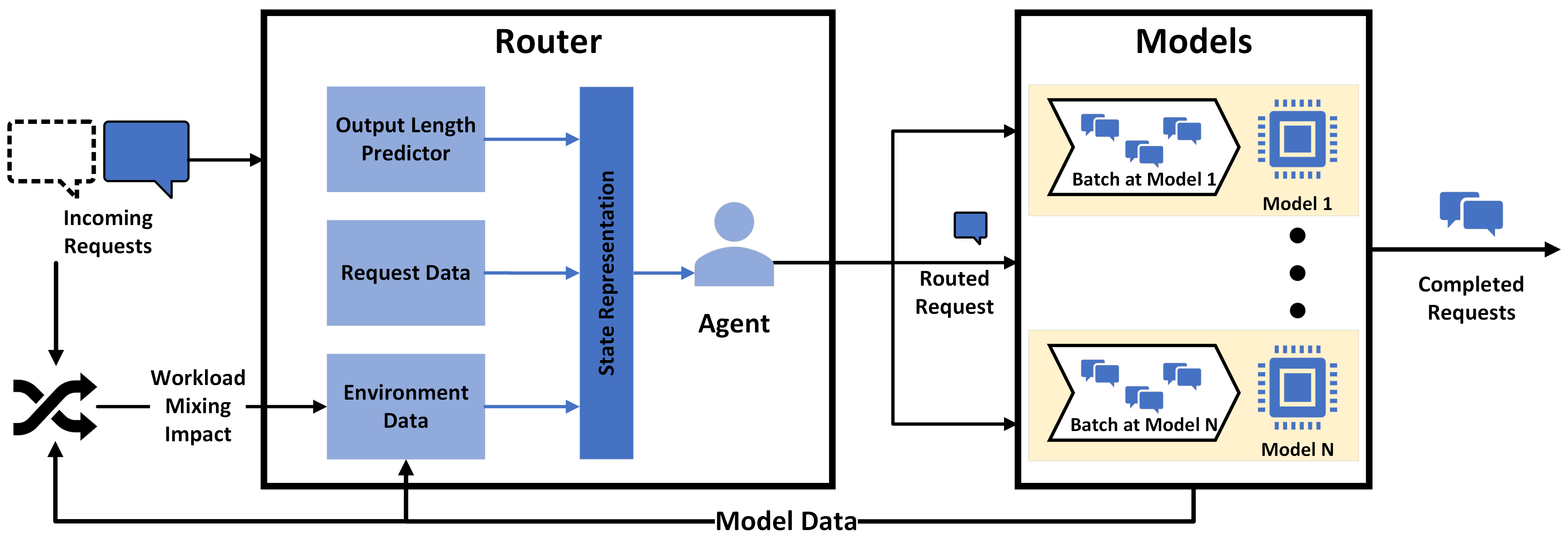
Figure 3: Architecture diagram: The intelligent router leverages both output length prediction and the workload impact estimator for instance assignment, contrasting with previous, instance-isolated schedulers.
The routing challenge is formalized as a Markov Decision Process with state descriptors that encode per-instance prompt/decode histograms, capacity availability, queue lengths, and expected request completion times. The action space is the set of m available instances; the agent may also optionally refrain from immediate assignment, biasing towards delayed placement if advisable.
The reward formulation includes: (1) negative terms for queueing; (2) a positive reward for completions; (3) a penalty based on the workload impact estimator to steer away from high-interference assignments. A key contribution is the use of “heuristic-guided” RL: instead of hard-coding penalties into the reward, the prior knowledge from the penalty estimator is annealed over training epochs—its effect is gradually diminished as the RL agent collects empirical data on its own assignments, improving robustness and convergence.
Three RL strategies are compared:
- Baseline RL: vanilla reward shaping with only completion/queue terms.
- Workload-Aware RL: explicit addition of the penalty term, constant across training.
- Workload-Guided RL: penalty appears only as a guidance term, vanishing as training progresses, preserving the original objective.
Convergence and stability are empirically confirmed across multiple runs (Figure 4).
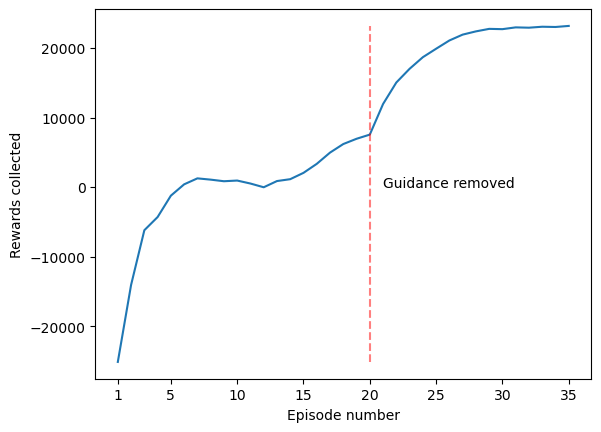
Figure 4: Workload-guided RL reward progression over training, demonstrating early bias from the penalty guidance and eventual convergence to optimal actions.
Quantitative Results and Contradictory Claims
Experimental evaluation is conducted using Llama 2 7B models deployed via vLLM, with 4 V100 GPUs and realistic request arrival streams. Workload-driven RL policies are compared to round-robin, join-shortest-queue, max-capacity, and Min-Min heuristics.
Key findings:
- Workload-guided RL reduces E2E latency by 11.43% compared to round-robin across 2,000 highly heterogeneous requests. Baseline RL yields improvements of ~4.3%, with further gain from phase-aware guidance.
- Contrary to assumptions embedded in classical multicore/job routing, instance-local batching optimizations (bin-packing, shortest-job-first) are consistently subdominant compared to intelligent routing. The gap between naive and optimal assignment persists even when fine-tuned batching is implemented instance-locally.
- For longer request streams, RL-based routing completely flattens the time-to-first-token (TTFT) variance and reduces the number of requests queued at model instances—a tail-effect that classical methods cannot eliminate.
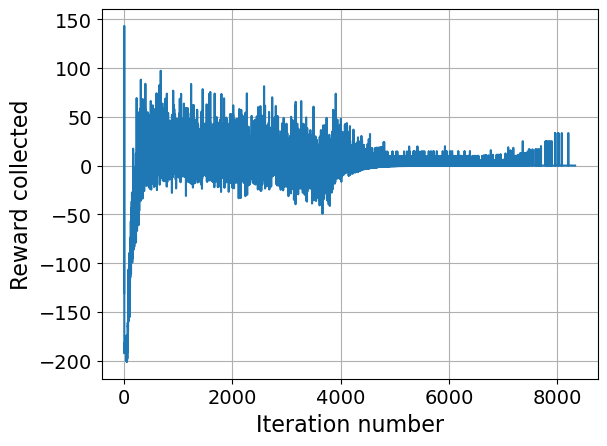
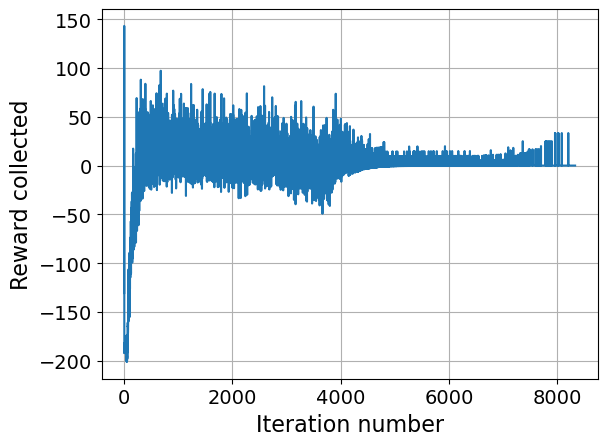
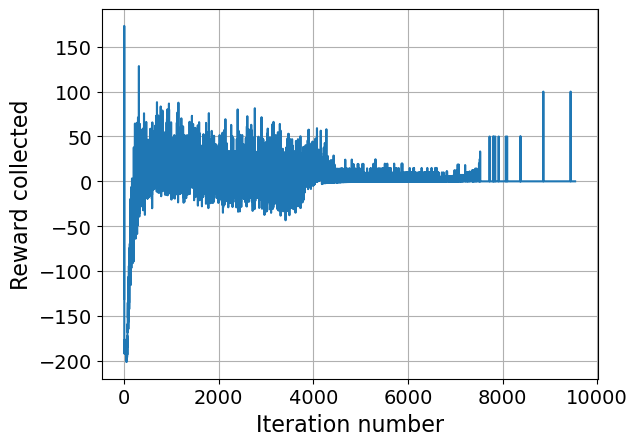
Figure 5: Baseline RL reward trajectory during training, indicating challenges in optimization when lacking workload-aware guidance.
These results explicitly contradict common wisdom in LLM serving circles that instance-level batching “solves” most of the performance pathologies; the global routing problem must be solved with explicit heterogeneity awareness.
Practical Implications and Future Directions
The techniques demonstrated are scalable: output length predictors and impact estimators generalize to arbitrarily many model–hardware combinations, given sufficient profiling of token time gradients. Critically, the approach can be layered atop any batching algorithm, as the router shapes the workload to maximize batch homogeneity and minimize interference, which is especially important as instances grow in size and models in number.
The work opens lines for further research:
- Application of the router to multi-tenant, preemptive settings with strict SLA guarantees and non-i.i.d. request distributions.
- Extension to multi-model GPU deployment, where workloads of distinct resource profiles must share single physical GPUs.
- Integration with speculative decoding strategies or compositional inference (as the router can nudge the system towards configurations that maximize speculative execution wins).
- Incorporation of richer job features (user provenance, personalization, downstream deadlines) into the routing state representations.
A practical limitation remains that all empirical results are obtained on V100 and Llama 2 7B; future work should test on A100/H100 and larger model scales, though the underlying methodology is invariant to base hardware.
Conclusion
This paper establishes the significance of global, phase-aware, RL-guided routing in LLM inference, providing strong numerical evidence that even sophisticated instance-local schedulers are insufficient to close the performance gap introduced by prompt/decode heterogeneity. Explicitly modeling and learning the impact of workload mixing enables superior end-to-end user-perceived latency, fairness, and overall infrastructure efficiency. The research direction outlined here will be essential as LLM workloads diversify further and system resource management becomes even more critical to sustainable, high-performance LLM deployment.